
除了生成图像,Stable Diffusion玩音乐也不在话下,Stable Diffusion 模型经过调试可以生成声谱图了,如下动图中的放克低音与爵士萨克斯独奏。
原文链接:https://www.riffusion.com/about

项目地址:https://github.com/riffusion/riffusion-app
具体而言,1.5 版本的 Stable Diffusion 模型对与文本配对的声谱图进行了微调。音频处理发生在模型的下游。
声谱图
音频声谱图以可视的形式将声音片段的频率内容表现出来,其中 x 轴表示时间,y 轴表示频率。每个像素的颜色显示了音频在给定频率和时间上的振幅。
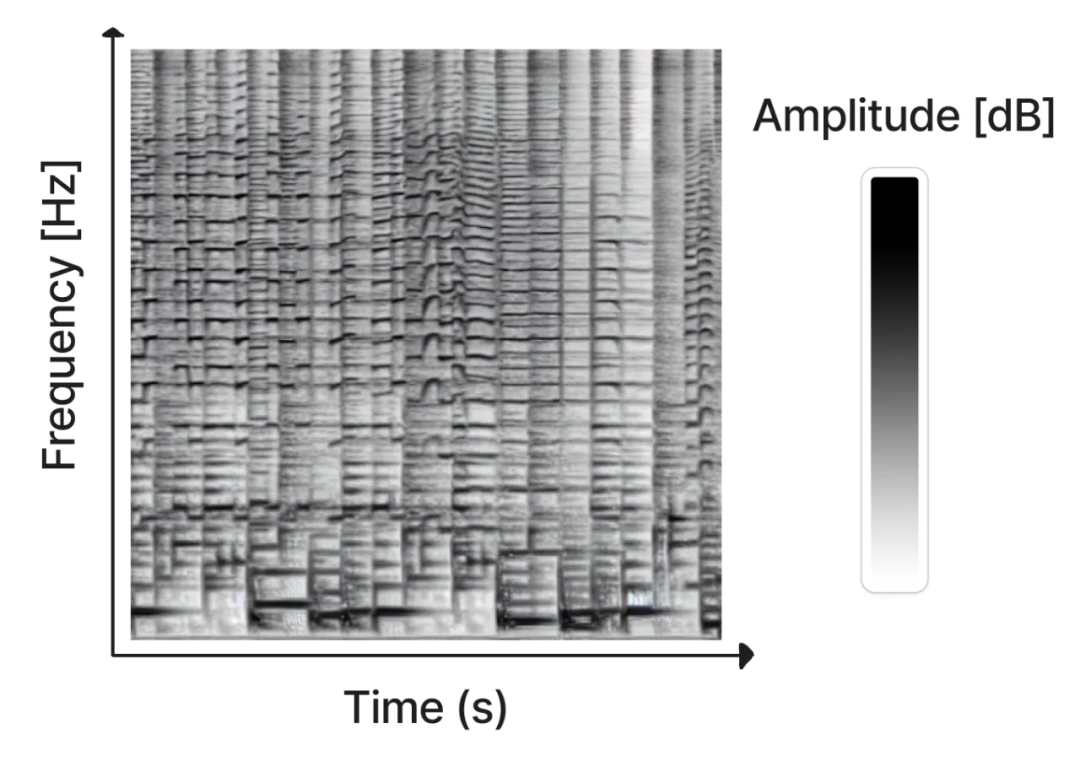
STFT 是可逆的,因此可以从声谱图中重建原始音频。然而,Riffusion 模型得到的声谱图只包含正弦波的振幅,而不包含相位,这是因为相位是混乱的,很难学习。相反在重建音频片段时,我们使用 Griffin-Lim 算法来近似相位。
声谱图中的频率区间使用 Mel 尺度,这是一个音高知觉尺度,由听众判断彼此之间的距离是否相等。
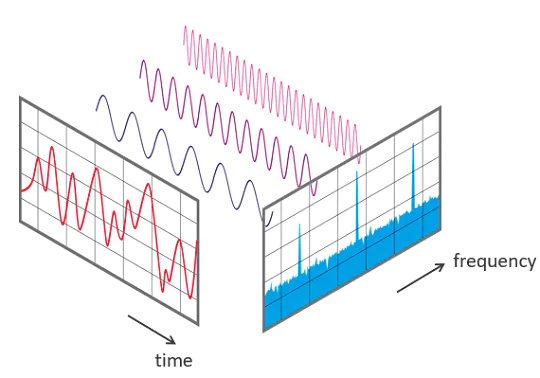
下图是一个解释为声谱图并转换为音频的手绘图像。回放可以直观地了解它们是如何运作的。请注意听下半部分两条曲线的音高,以及顶部四条垂直线如何发出类似于 hi-hat 音的节拍。

我们使用了 Torchaudio,好处在于它有优秀的模块可以在 GPU 上高效地进行音频处理。
图像到图像
使用 diffusion 模型不仅可以将创作条件设置为文本 prompt,还可以设置为其他图像。这对于修正声音的同时保留你喜欢的原始片段的结构非常有用。用户可以使用去噪强度参数控制与原始片段的偏离程度,并向新的 prompt 方向倾斜。
例如,下图为放克萨克斯管的即兴重复片段,然后修改一下,把钢琴音量调高。

生成短片段固然很有趣,但无限的 AI 生成片段才是我们真正想要的。
假设放入一个 prompt 并生成 100 个具有不同 seed 的片段。我们无法将结果片段连接起来,因为它们有不同的音调、节奏和强拍。
因此,我们的策略是选择一个初始图像,并通过使用不同的 seed 和 prompt 运行图像到图像的生成,并生成该初始图像的变体。这将保留片段的关键属性。为了使它们可循环,我们还创建了具有精确测量数值的初始图像。
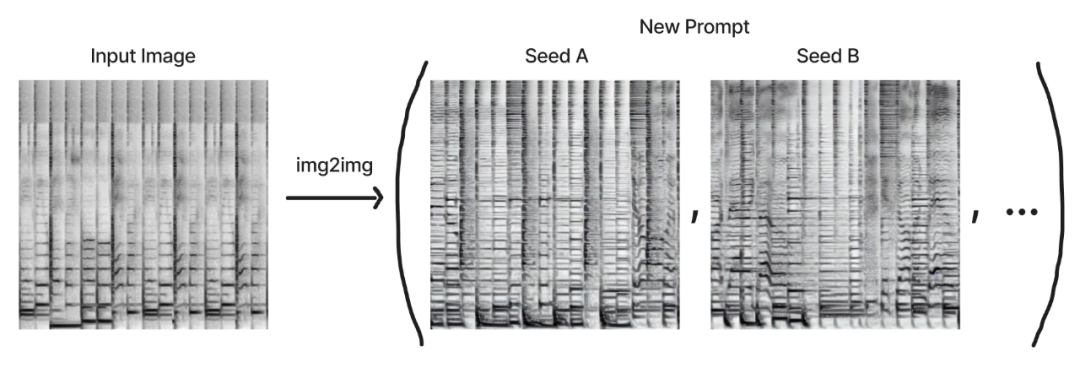
然而,即使使用这种方法,片段之间的过渡仍然很突兀。对于具有相同整体结构的同一 prompt 的多种解释,仍然可以在它们的氛围和旋律主题上呈现很大不同。
为了解决这个问题,我们在模型潜在空间中的 prompt 和 seed 之间平滑地进行插值。在 diffusion 模型中,潜在空间是一个特征向量,它嵌入了模型可以生成的整个可能空间。彼此相似的项目在潜在空间中是接近的,并且潜在空间的每个数值都解码为可行的输出。
关键在于,我们可以对带有两种不同 seed 的 prompt 之间的潜在空间进行采样,也可以对带有相同 seed 的两个不同 prompt 进行采样。下面是一个可视化模型示例:

我们的模型可以用来做同样的事,它往往产生光滑的过渡,即使在完全不同的 prompt 之间。这比插入原始音频有趣得多,因为在潜在空间中,所有中间点听起来仍然像合理的片段。
下图是彩色的,以显示相同 prompt 的两个 seed 之间的潜在空间插值。播放这个序列要比只播放两个端点流畅得多。插入片段往往是多样化的,有自己的即兴重复片段和主题。
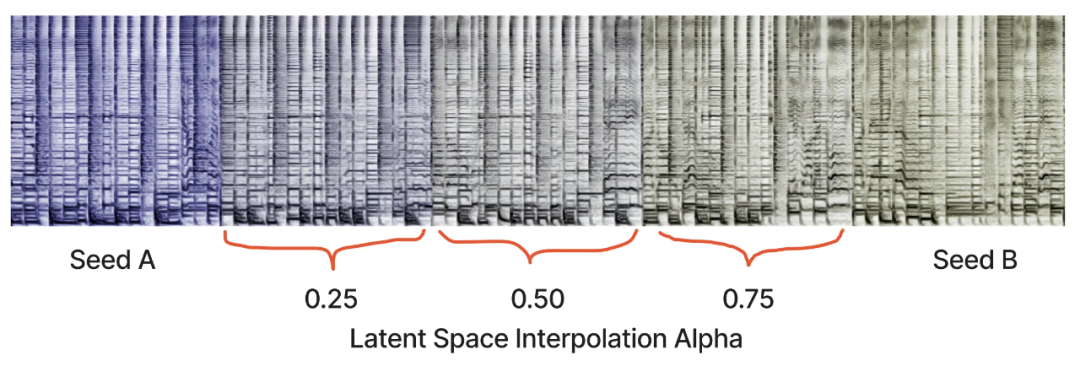
下面是我们最喜欢的一个,从敲击到爵士乐的 20 步插值。
还有一个是从教堂钟声到电子节拍。
最后是阿拉伯福音的插值,这一次两个 seed 之间有相同的 prompt。
交互式 Web 应用程序
交互式 web 应用程序可以将所有的这些整合在一起,也可以输入 prompt 并无限实时生成插值内容,同时以 3D 方式可视化声谱图时间轴。
当用户输入新的 prompt 时,音频平滑地过渡到新的 prompt。如果没有新的 prompt,应用程序将在同一 prompt 的不同种子之间插入。声谱图被可视化为遵循半透明播放头时间轴的 3D 高度图。
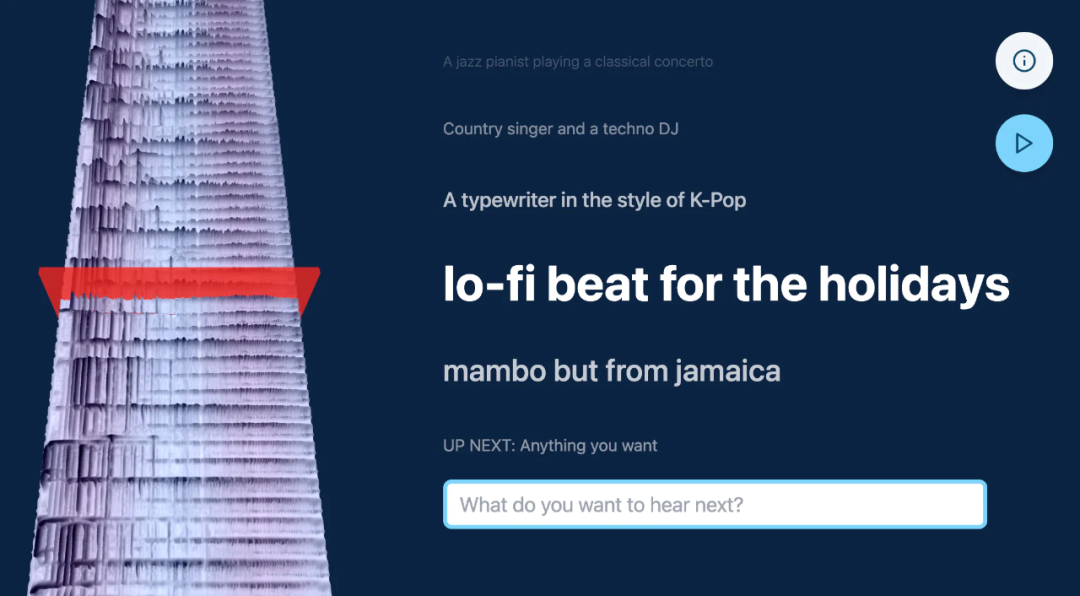
该应用程序是使用 Next.js、React、Typescript、three.js、Tailwind 和 Vercel 构建的,通过 API 进行通信,以在 GPU 服务器上运行推理调用。我们使用 Truss 打包模型并在本地进行测试,然后部署到 Baseten,它提供了 GPU 推理、自动缩放和可观察性。我们在生产中使用了 NVIDIA A10G。如果你的 GPU 足够强大,可以在五秒内生成 stable diffusion 结果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢