
一位普林斯顿大学的学生,Edward Tian 推出了一个专杀 ChatGPT 的应用「GPTZero」,马上可以分辨出内容是机器生成还是人写的。该程序 1 月 2 日上线,在一周内有3万人试用,托管 GPTZero 的免费平台 Streamlit 此后介入,以更多的内存和资源支持 Tian,以处理网络流量。
GPTZero 的一炮而红,让 Tian 获得了来自 a16z、 Menlo Ventures 和 Red Swan 等知名风投的青睐。Tian 表示自己的 GPTZero 尚未完成,仍需改进和进一步地开发,甚至计划让大家继续免费使用他的程序,用来支持各地新晋英文老师的工作。
Edward Tian 表示研发 GPTZero,是希望能让学术界恢复严谨性。Tian是美国普林斯顿大学的大四学生,主修计算机科学专业,专门研究自然语言处理,辅修认知科学和新闻学。他还曾是英国广播公司和开源情报网站 Bellingcat 的研究员,也曾是被微软收购的反恐初创公司 Miburo Solutions 的分析师。在那里,他监测虚假信息和机器人检测。

GPTZero 的开发者 Edward Tian|网络
GPT Zero 的工作原理
GPTZero 应用程序的原理是借助一些文本属性进行分析。首先是困惑度(perplexity),即文本对模型的随机性,或语言模型对文本的「喜爱」程度;然后是突发度(burstiness),即机器写作的文本在一段时间内表现出的困惑度更均匀和恒定,而人类书写的文本则不会这样。
检测文本的「困惑性」(Perplexity)和「突发性」(Burstiness)这两项指标,并分别对其打分,根据统计学特征来确定,文本是由人工智能写的还是人类写的。总体来说,如果这两项参数得分都很低,那么该文本很有可能出自 AI 之手。
这里所说的「困惑性」,是指来自人类所写作品的语言的复杂性和随机性。指标主要是衡量文本在一个句子中的随机程度,以及一个句子的构造方式是否会让 GPTZero 感到困惑。
每当用户在 GPTZero 输入一段测试内容,它就会分别计算出:「文字总困惑度」、「所有句子的平均困惑度」、「每个句子的困惑度」。
这些数值越低,越能说明这个文本对 GPTZero 来说是非常「熟悉」的,那么它很可能是 AI 生成的;相反,如果这些数值越高,就越能说明文本中句子的构造或用词方式让 GPTZero 感到「惊讶」,那么它就更可能是出自人类之手。
这是因为,人工智能接受过数据库的训练,生成的文本在一段时间内,表现出的困惑度会更均匀和恒定,选词的可预测性也更高;而人类书写的文本则不会这样,真人的遣词造句一般会比较随机,比机器更容易写比较出乎意料的词句。
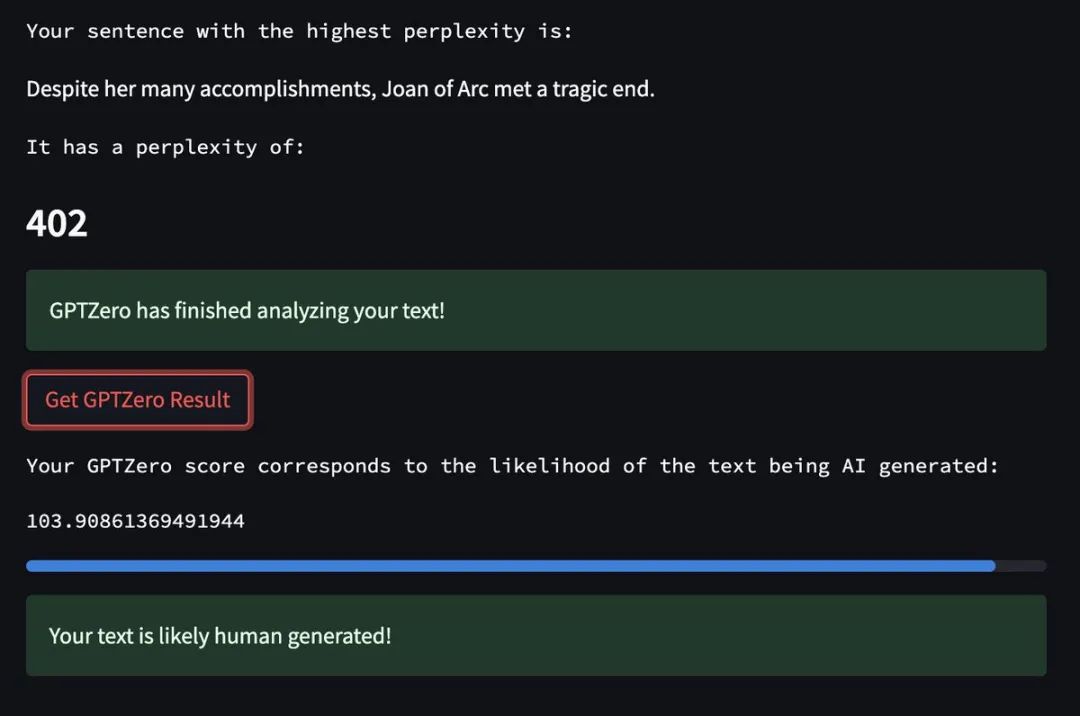
使用 GPTZero 检测文字是否由 ChatGPT 生成|Twitter
而「突发性」,则是指来自人类使用的句子结构的变化。
这个参数主要是比较句子复杂性的变化程度,衡量它们的一致性。这是因为,人类倾向于写高度复杂的文本;而人工智能产出的文本则是低复杂度的;此外,由于人类的思维结构不是线性的,他们的句子结构也遵循类似的模式。
人类使用句子结构,会在长而复杂的句子,和短而简单的句子之间摇摆不定,有着更多的句式变化,比如复杂和简单交替并存,一个长难句之后接着出现更简短的句子;而机器生成的句子则倾向于更加统一,很少会有一系列长度相差很大的句子。
在选词上「简单」而「熟悉」,并使用「统一整齐」的句子,是人工智能生成作品的标志特征,而更复杂和多样的东西,则表明是人类写的。这也是「困惑性」和「突发性」这两项指标可以作为衡量标准的原因。
2022 年 12 月,OpenAI 专注于人工智能安全的研究员 Scott Aaronson 透露,该公司正在努力开发「缓解措施」,用一种「不易察觉的秘密信号」对 GPT 生成的文本打上「水印」,以识别其来源,从而打击作弊的系统。
这项技术将通过微妙地调整 ChatGPT 选择的特定单词选择来发挥作用,读者不会注意到这种方式,但对于任何寻找机器生成文本迹象的人来说,这在统计上都是可预测的。
公司发言人表示,「我们将 ChatGPT 作为新研究的预览技术,希望能从现实世界的应用中进行学习。我们认为这是开发和部署功能强大、安全的 AI 系统的关键部分。我们会不断吸取反馈和经验教训,」。
OpenAI 还联合哈佛等高校机构联合打造了一款检测器:GPT-2 Output Detector,ChatGPT同团队的人开发了 GPT 检测器(https://huggingface.co/openai-detector)
作者们先是发布了一个「GPT-2 生成内容」和 WebText 数据集,帮助 AI 理解机器语言和人类语言之间的差异。随后,用这个数据集对 RoBERTa 模型进行微调,就得到了这个 AI 检测器。其中人类语言一律被识别为 True,AI 生成的内容则一律被识别为 Fake。
值得一提的是,RoBERTa 是 BERT 的改进版。原始的 BERT 使用了 13GB 大小的数据集,但 RoBERTa 使用了包含 6300 万条英文新闻的 160GB 数据集。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢