
作者:Roy Ganz、Oren Nuriel、Aviad Aberdam、等
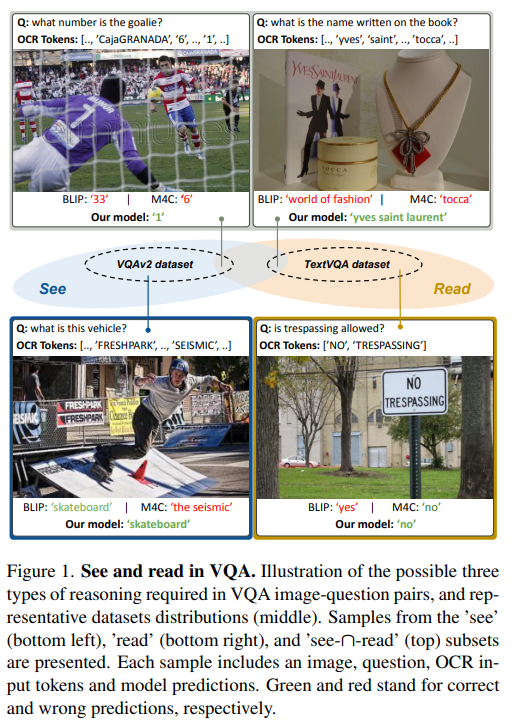
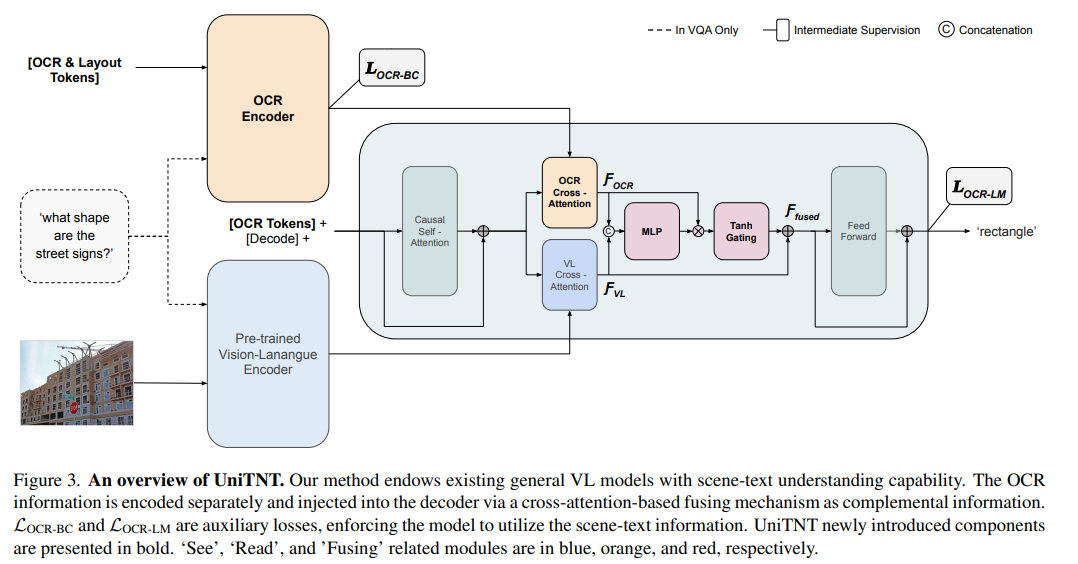
简介:本文研究视觉问答(VQA)与图像捕获(CAP)统一整合的方法,并获得业界首个成功处理两种任务类型的单一模型,大幅提升了场景文本理解能力。VQA和CAP是最流行的视觉语言任务之一,它们具有类似的场景文本版本,需要从图像中的文本进行推理。尽管它们之间有明显的相似之处,但两者都是独立处理的,产生了可以看到或阅读的任务特定方法,但不能同时看到或阅读。在这项工作中,作者对这一现象进行了深入分析,并提出了UniTNT,这是一种统一文本非文本方法,它赋予了现有的多模态架构场景文本理解能力。具体来说,作者将场景文本信息视为一种额外的模态,通过指定的模块将其与任何预训练的基于编码器-解码器的架构融合。彻底的实验表明:UniTNT产生了第一个成功处理两种任务类型的单一模型。此外,作者表明场景文本理解能力可以分别将视觉语言模型在VQA和CAP上的性能提高3.49%和0.7CIDEr。
论文下载:https://arxiv.org/pdf/2301.07389.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢