
来自今天的爱可可AI前沿推介
[CV] Learning Customized Visual Models with Retrieval-Augmented Knowledge
H Liu, K Son, J Yang, C Liu, J Gao, Y J Lee, C Li
[Microsoft & University of Wisconsin–Madison]
基于检索增强知识的定制视觉模型学习
要点:
-
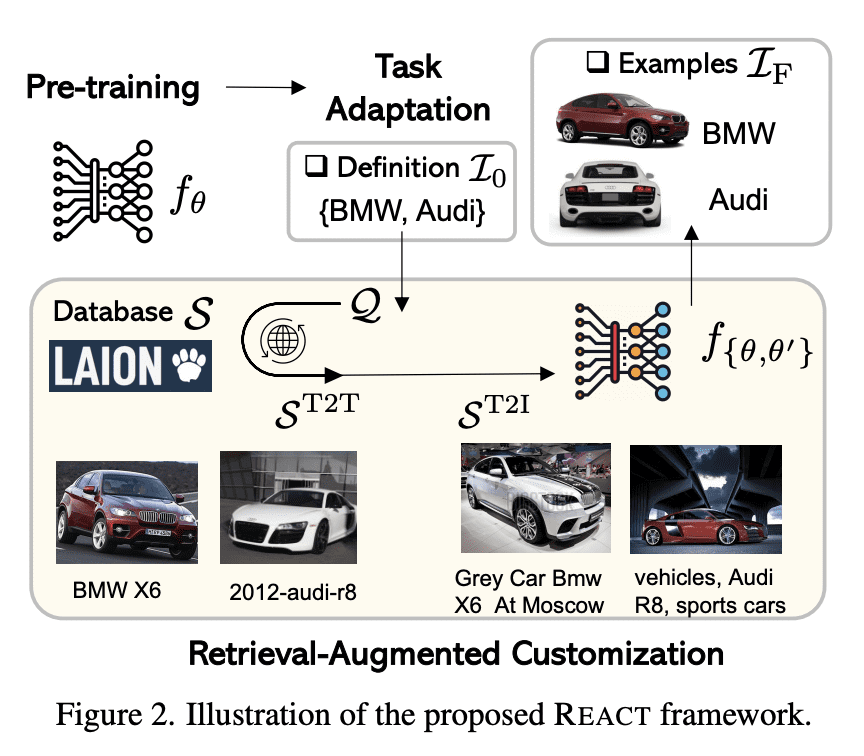
提出一种新框架REACT(检索增强定制),用于用网络级图像文本数据为目标域构建定制视觉模型; -
对各种任务的广泛实验,包括在零样本和少样本的设置下进行分类、检索、检测和分割,展示了REACT的有效性; -
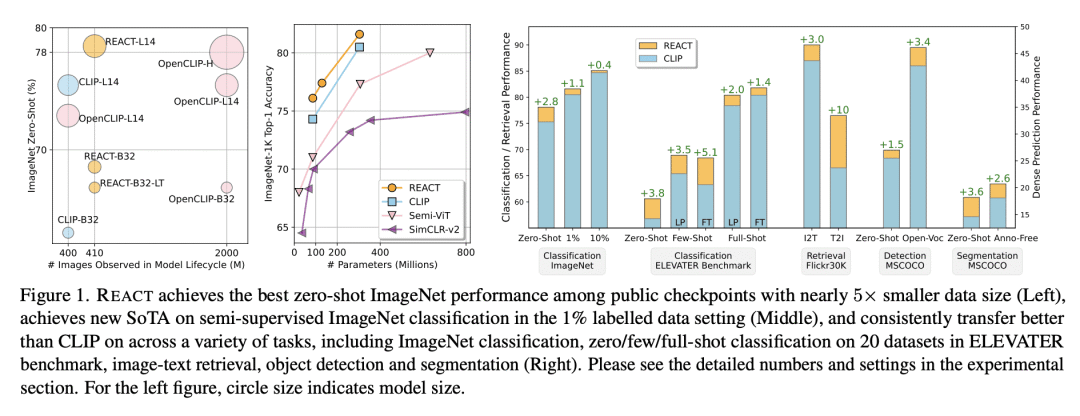
与当前最先进的模型 CLIP 相比,REACT 可以在 ImageNet 上实现高达 5.4% 的改进,在 ELEVATER 基准(20个数据集)上实现 3.7% 的零样本分类任务。
一句话总结:
提出REACT,一个获取相关网络知识的框架,为目标域构建定制的视觉模型,与现有模型相比,在零样本分类任务方面实现了高达 5.4% 的改进。
摘要:
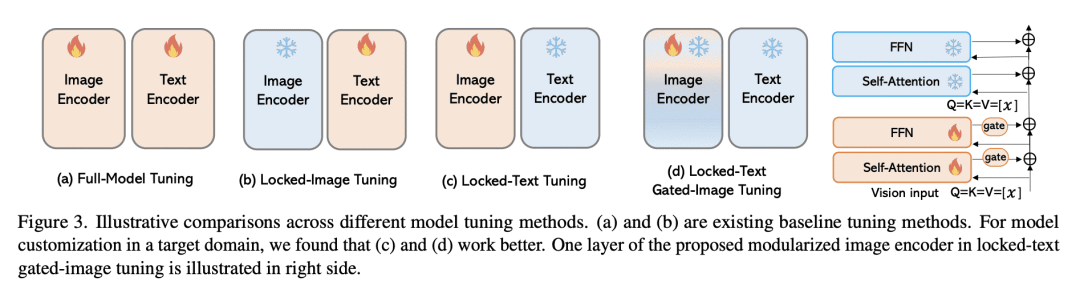
CLIP等图像文本对比学习模型表现出很强的任务迁移能力。这些视觉模型的高度通用性和可用性是通过网络级的数据收集过程实现的,以确保广泛的概念覆盖,然后是昂贵的预训练,将所有知识注入模型权重。本文提出 REACT,检索增强定制,一种获取相关网络知识的框架,为目标域构建定制的视觉模型。作为外部知识,从网络级数据库中检索最相关的图像文本对(约占CLIP预训练数据的3%),提出仅通过训练新的修改块来自定义模型,同时冻结所有原始权重。REACT 的有效性通过对分类、检索、检测和分割任务(包括零样本、少样本和全样本设置)的广泛实验得到了证明。特别是,在零样本分类任务上,与CLIP相比,在ImageNet上实现了高达5.4%的改进,在ELEVATER基准(20个数据集)上实现了3.7%的改进。
Image-text contrastive learning models such as CLIP have demonstrated strong task transfer ability. The high generality and usability of these visual models is achieved via a web-scale data collection process to ensure broad concept coverage, followed by expensive pre-training to feed all the knowledge into model weights. Alternatively, we propose REACT, REtrieval-Augmented CusTomization, a framework to acquire the relevant web knowledge to build customized visual models for target domains. We retrieve the most relevant image-text pairs (~3% of CLIP pre-training data) from the web-scale database as external knowledge, and propose to customize the model by only training new modualized blocks while freezing all the original weights. The effectiveness of REACT is demonstrated via extensive experiments on classification, retrieval, detection and segmentation tasks, including zero, few, and full-shot settings. Particularly, on the zero-shot classification task, compared with CLIP, it achieves up to 5.4% improvement on ImageNet and 3.7% on the ELEVATER benchmark (20 datasets).
论文链接:https://arxiv.org/abs/2301.07094
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢