
来自今天的爱可可AI前沿推介
[LG] The Role of Baselines in Policy Gradient Optimization
J Mei, W Chung, V Thomas, B Dai, C Szepesvari, D Schuurmans
[Google Research & McGill University & University of Montreal & DeepMind]
基线在政策梯度优化中的作用
要点:
-
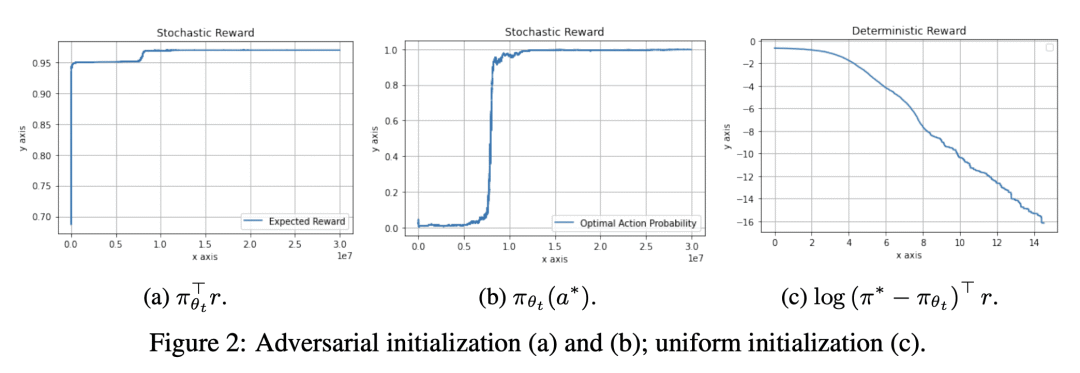
使用状态价值基线,允许 on-policy 随机自然策略梯度(NPG)以 O(1/t) 的速度收敛到之前未知的全局最优策略; -
通过证明自然政策梯度估计的方差,在有或没有基线的情况下仍然是无限的,且方差减少无法解释基线在此背景下的效用,从而为基线在随机策略梯度中的作用提供了新的理解; -
价值基线的主要效果,是降低更新的侵略性,这对于随机 NPG 几乎可以肯定地收敛是必要和充分的。
一句话总结:
研究了基线在 on-policy 随机策略梯度优化中的作用,并表明使用状态价值基线可以使 on-policy 随机自然策略梯度以 O(1/t) 速率收敛到全局最佳策略,提供了对基线作用的新理解。
论文链接:https://arxiv.org/abs/2301.06276
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢