
【标题】RLPrompt: Optimizing Discrete Text Prompts with Reinforcement Learning
【作者团队】Mingkai Deng, Jianyu Wang, Cheng-Ping Hsieh
【发表日期】2022.10.22
【论文链接】https://arxiv.org/pdf/2205.12548.pdf
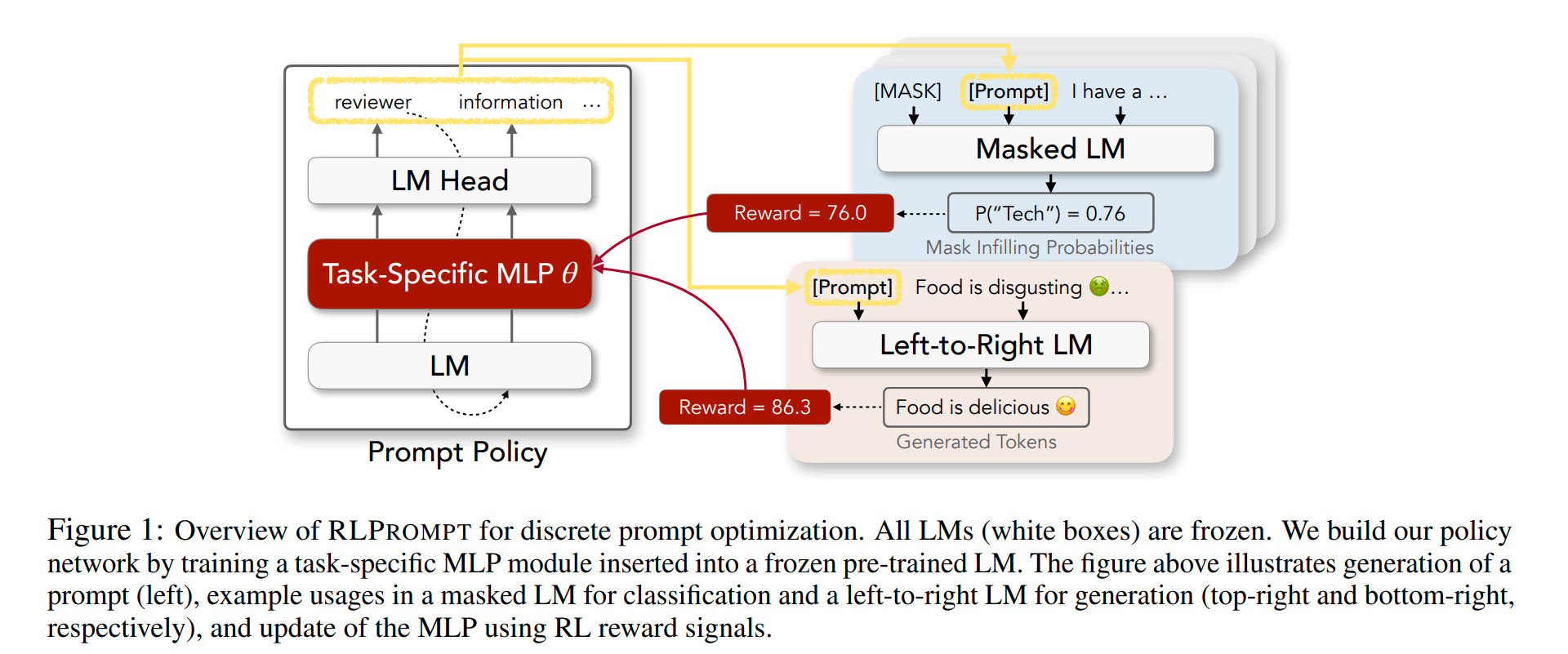
【推荐理由】提示在使大型预训练语言模型(LMs)能够执行各种NLP任务方面取得了令人印象深刻的成功,尤其是当只有很少的下游数据可用时。然而,自动为每个任务找到最佳提示是一项挑战。大多数现有的工作都依赖于调整软提示,这在可解释性、跨LMs的可重用性以及梯度不可访问时的适用性方面存在不足。另一方面,离散提示很难优化,通常是通过“枚举-然后选择”启发式方法创建的,这些启发式方法没有系统地探索提示空间。本文提出了一种具有强化学习(RL)的高效离散提示优化方法RLPrompt。RLPrompt制定了一个参数有效的策略网络,该网络在有奖励的训练之后生成期望的离散提示。为了克服大型LM环境中奖励信号的复杂性和随机性,作者引入了有效的奖励稳定,这大大提高了训练效率。RLPrompt可灵活应用于不同类型的LMs,例如掩码和从左到右的模型,用于分类和生成任务。在少数镜头分类和无监督文本风格转换上的实验表明,与现有的各种微调或提示方法相比,具有更高的性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢