
2019年3月,机器学习先驱、强化学习大牛Richard S. Sutton发表了一篇名为「苦涩的教训」(The Bitter Lesson)的文章,曾经轰动一时。Sutton认为过去70年走过人工智能弯路中,「堆算力」可能是我们最终实现有效的通用学习方法,而非人类专家设计的复杂知识。
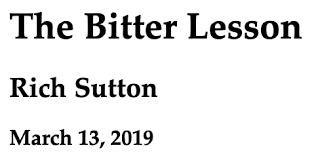
最近谷歌AI的研究人员Karol Hausman提出了「苦涩的教训2.0版本」,他认为在机器人之外的领域(比如大型语言模型)中寻找到一种可以大规模「生成数据」的方式,可能是机器人领域这么多年发展下来学到的苦涩教训。
网友甚至还直接预测出了「苦涩的教训3.0」:当你意识到「基础模型的创造者」比你更有能力对模型进行微调时,在大型预训练模型上进行微调的整个想法就不攻自破了。因为微调对他们来说非常便宜,而且他们有更多的计算能力。他们可以直接向客户出售服务,而非向「中介机构」提供API来访问。Karol Hausman的主要研究方向是使机器人能够在现实环境中基于最少量监督(minimal supervision)获得通用技能。他也是斯坦福大学机器人研究和人工智能专业的兼职教授(adjunct professor)。
从历时70年的人工智能研究中可以学到的最大教训是,提升计算量的一般方法是最有效的,而且能大幅提升性能。其根本原因是摩尔定律...
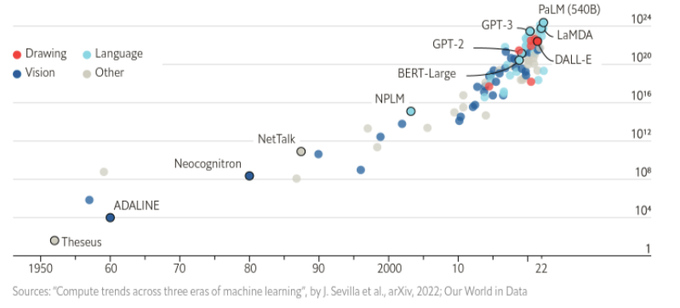

例如,要求语言模型描述如何清理洒出来的东西可能会生成一个合理的叙述,但它可能不适用于需要在特定环境中执行此任务的特定智能体,如机器人。
研究人员提出通过预训练的行为来提供这一基础,这些行为可以被用来微调模型,以提出既可行又适合上下文的自然语言行为。

机器人可以充当语言模型的「手和眼睛」,而语言模型提供关于任务的高级语义知识。
文章中展示了如何将低级任务与大型语言模型相结合,以便语言模型提供执行复杂和时间扩展指令的过程的高级知识,而与这些任务相关的价值函数提供了将这些知识与特定物理环境联系起来所必需的基础。
实验中在一些现实世界的机器人任务对该方法进行评估,结果表明,这种方法是能够完成长期的、抽象的、自然语言指令的移动机械手。
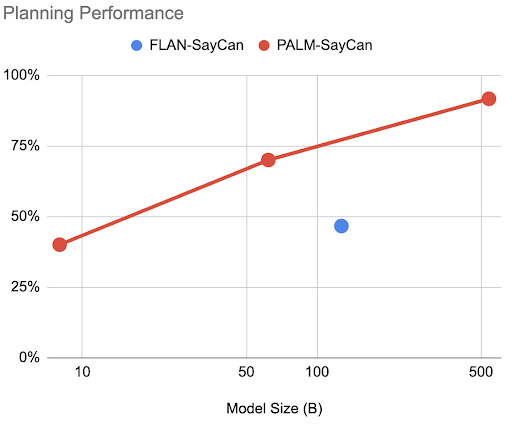
在论文的后续更新PaLM-SayCan中,研究人员发现确实观察到了「苦涩的教训2.0」版本中的行为,即仅通过升级模型中的LLM到更高性能的PaLM,就可以得到1)更好的性能;2)思维链提示;3)处理其他语言的查询。
大型语言模型(LLMs)的推理能力可以应用于自然语言处理以外的领域,如机器人的规划和互动。
这些具体的问题要求智能体从多个语义层次上来理解世界:可用的技能组合,这些技能如何影响世界,以及世界的变化如何映射到语言。
在具身环境中进行规划的LLMs不仅需要考虑做什么技能,还需要考虑如何和何时做这些技能,而且这些答案可能会随着时间的推移而改变,以回应智能体自己的选择。
这项工作研究了在这种具身环境中使用的LLM,在多大程度上可以对通过自然语言提供的反馈源进行推理,而无需任何额外的训练。

文中提出,通过利用环境反馈,LLMs能够形成一种内心独白(inner monologue),使它们能够在机器人控制场景中进行更丰富的处理和计划。
实验中研究了各种反馈来源,如成功检测、物体识别、场景描述和人类互动,从结果中可以发现,闭环语言反馈明显改善了三个领域的高水平指令完成情况,包括模拟和真实的桌面重新安排任务以及真实厨房环境中的长距离移动复制任务。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢