
来自今天的爱可可AI前沿推介
[CV] Multiview Compressive Coding for 3D Reconstruction
C Wu, J Johnson, J Malik, C Feichtenhofer, G Gkioxari
[Meta AI]
面向3D重建的多视压缩编码
要点:
-
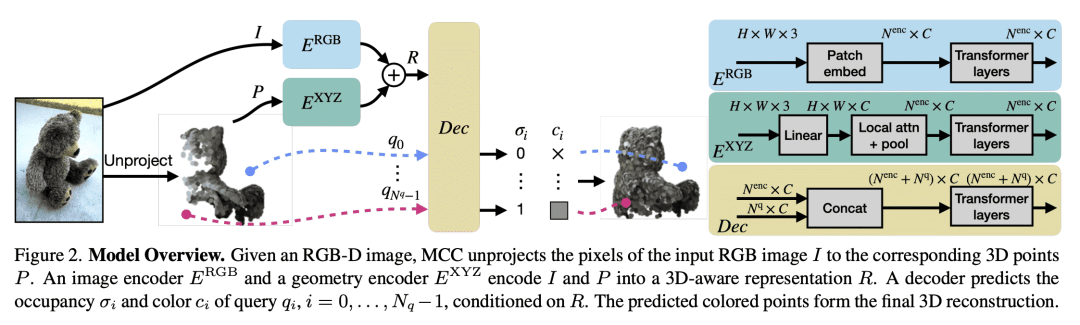
提出多视压缩编码(MCC)作为适用于对象和场景的通用3D重建模型; -
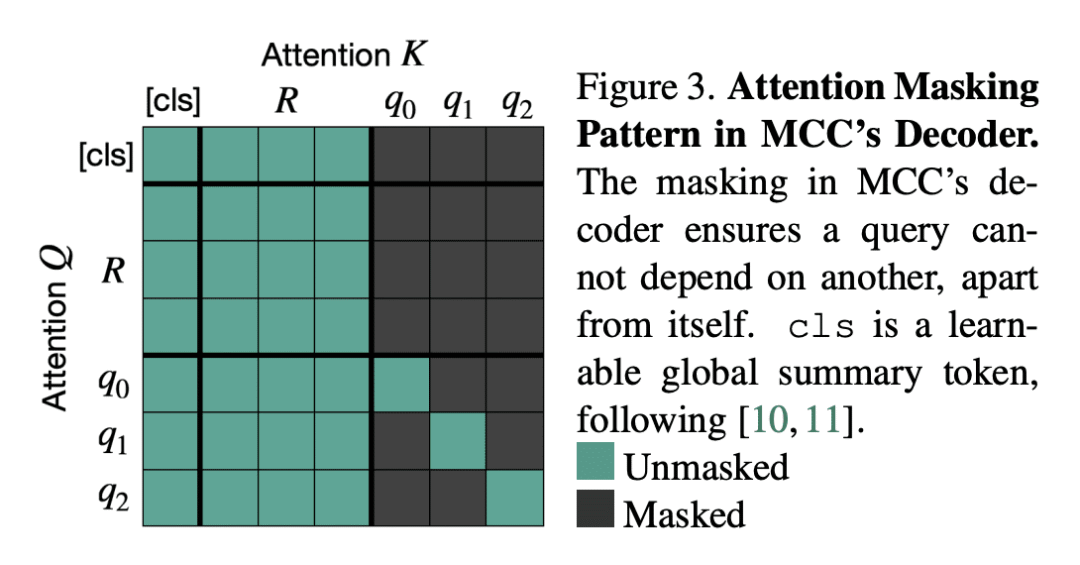
通过查询 3D 感知解码器,来学习压缩输入外观和几何形状,预测3D结构; -
用简单的基于点的方法加上类别无关的大规模训练,作为3D重建的有效方法。
一句话总结:
提出一种新框架,多视压缩编码(MCC),通过从不同的RGB-D视频中学习可泛化表示,用于单幅图像的3D重建,克服图像中未显现遮挡带来的挑战。
摘要:
视觉识别的一个中心目标,是从单幅图像理解对象和场景。借助大规模学习和通用表示,2D识别取得了巨大进展。相比之下,由于图像中存在没有显现的遮挡,3D建模面临新的挑战。之前的工作试图通过从多个视图推断,或依赖稀缺的 CAD 模型,以及特定类别的先验来克服这些问题,这些模型和先验阻碍了扩展到新的设置。本文通过学习受自监督学习进步启发的可泛化表示,来探索单视图 3D 重建。提出一种简单框架,适用于单个对象或整个场景的3D点,以及来自不同 RGB-D 视频的类别无关的大规模训练。所提出的模型多视压缩编码(MCC)通过查询 3D 感知解码器,来学习压缩输入外观和几何形状,预测3D结构。MCC 的通用性和效率,使其能从大规模和多样化的数据源中学习,这些数据源具有强大的泛化,可以学习到 DALL·E 2 生成或用 iPhone 在实际场景捕获的新物体。
A central goal of visual recognition is to understand objects and scenes from a single image. 2D recognition has witnessed tremendous progress thanks to large-scale learning and general-purpose representations. Comparatively, 3D poses new challenges stemming from occlusions not depicted in the image. Prior works try to overcome these by inferring from multiple views or rely on scarce CAD models and category-specific priors which hinder scaling to novel settings. In this work, we explore single-view 3D reconstruction by learning generalizable representations inspired by advances in self-supervised learning. We introduce a simple framework that operates on 3D points of single objects or whole scenes coupled with category-agnostic large-scale training from diverse RGB-D videos. Our model, Multiview Compressive Coding (MCC), learns to compress the input appearance and geometry to predict the 3D structure by querying a 3D-aware decoder. MCC's generality and efficiency allow it to learn from large-scale and diverse data sources with strong generalization to novel objects imagined by DALL⋅E 2 or captured in-the-wild with an iPhone.
论文链接:https://arxiv.org/abs/2301.08247

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢