
来自今天的爱可可AI前沿推介
LG] Mega: Moving Average Equipped Gated Attention
Mega: 移动平均门控注意力
要点:
-
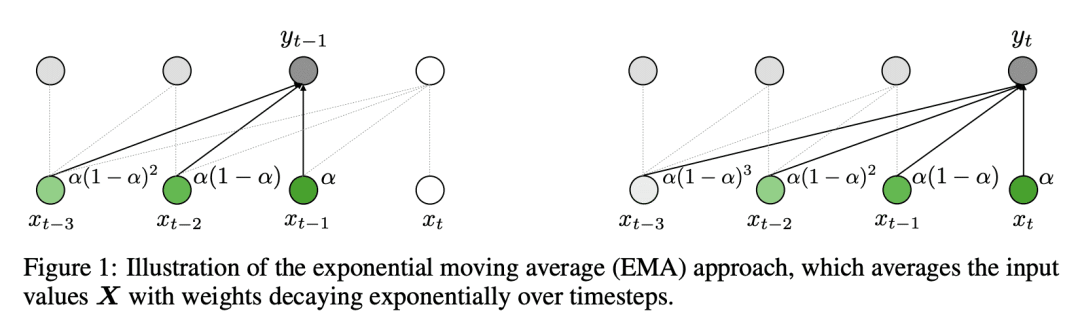
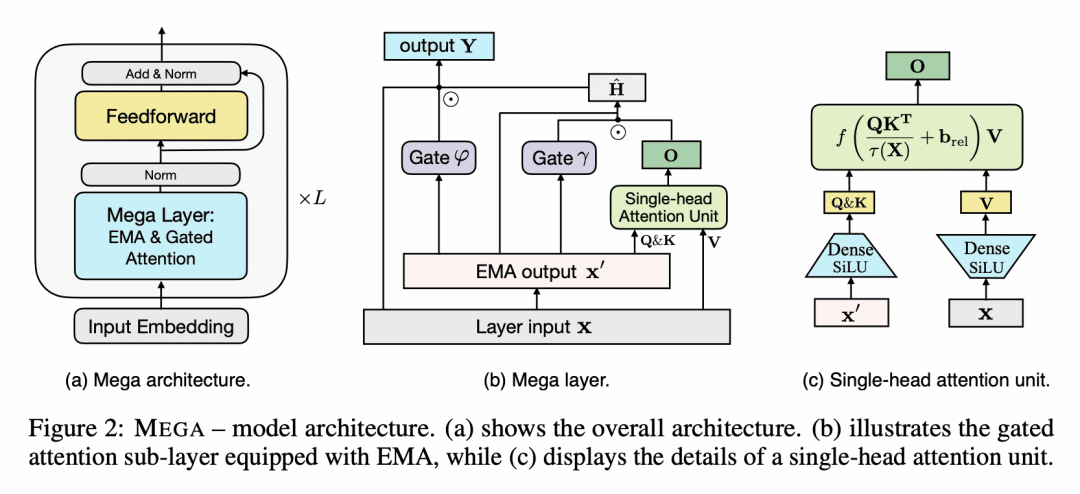
提出 Mega,一种采用指数移动平均的简单且具有理论基础的单头门控注意力机制; -
将位置感知的局部依赖性纳入位置无关注意力机制中; -
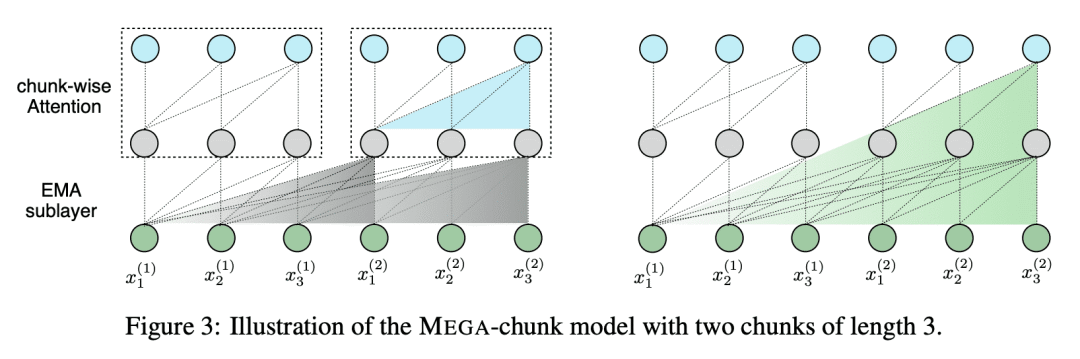
Mega 的变体 Mega-chunk,提供线性时间和空间复杂性,且质量损失最小。
一句话总结:
Mega 是一种简单有效的神经架构,采用指数移动平均将归纳偏差纳入注意力机制,大大改进了各种数据类型和任务的其他序列模型。
摘要:
Transformer 注意力机制的设计选择,包括弱归纳偏差和二次计算复杂度,限制了其在长序列建模中的应用。本文提出 Mega,一种简单、具有理论基础的单头门控注意力机制,采用(指数)移动平均,将位置感知局部依赖性的归纳偏差纳入位置无关的注意力机制中。进一步提出一种 Mega 变体,通过有效地将整个序列分为多个固定长度的块,提供线性时间和空间复杂性,且只产生最小的质量损失。对广泛的序列建模基准的广泛实验,包括 Long Range Arena、神经机器翻译、自回归语言建模及图像和语音分类,表明 Mega 比其他序列模型取得了重大改进,包括 Transformer 的变体和最近的状态空间模型。
The design choices in the Transformer attention mechanism, including weak inductive bias and quadratic computational complexity, have limited its application for modeling long sequences. In this paper, we introduce Mega, a simple, theoretically grounded, single-head gated attention mechanism equipped with (exponential) moving average to incorporate inductive bias of position-aware local dependencies into the position-agnostic attention mechanism. We further propose a variant of Mega that offers linear time and space complexity yet yields only minimal quality loss, by efficiently splitting the whole sequence into multiple chunks with fixed length. Extensive experiments on a wide range of sequence modeling benchmarks, including the Long Range Arena, neural machine translation, auto-regressive language modeling, and image and speech classification, show that Mega achieves significant improvements over other sequence models, including variants of Transformers and recent state space models.
论文链接:https://openreview.net/forum?id=qNLe3iq2El
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢