
01. 背景介绍
最近在做关键词抽取项目,需要将用户搜索query、资讯news、广告文案、用户点击title等不同场景下的文本数据提取关键词,然后作为特征提供给下游召回和推荐场景中使用。之前也分享过一篇关键词抽取的文章《广告行业中那些趣事系列31:关键词提取技术攻略以及BERT实践》
关键词抽取流程主要分成获取候选词和候选词打分两个流程:
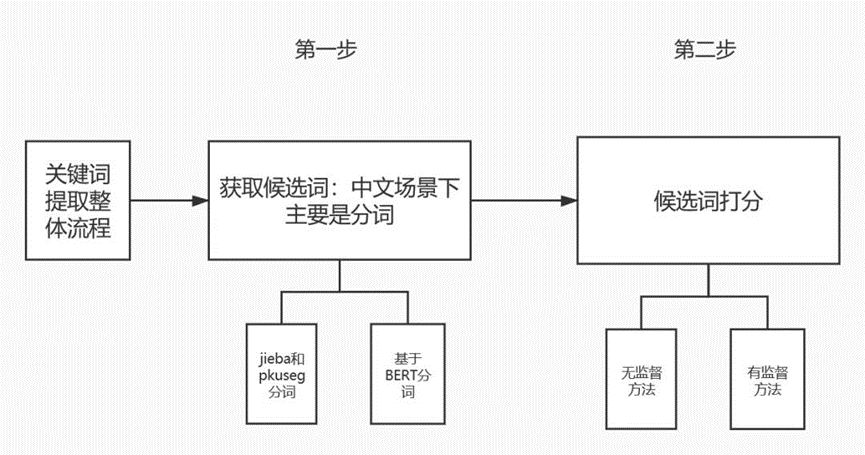
对于获取候选词流程,中文场景下主要是分词,一方面我们主要通过jieba和哈工大pkuseg分词,另一方面还可以通过BERT进行分词;
对于候选词打分流程,主要通过无监督学习和有监督学习两大类进行打分。
最近调研到Keybert作为一种无监督学习的关键词抽取流程,效果不错,这里对Keybert进行调研并打算应用到广告场景中。
02. Keybert详解
2.1 什么是Keybert
Keybert是一种基于无监督学习的关键词抽取技术,不仅效果好,而且易于使用。Keybert主要通过Bert获取文档和候选词的embedding,然后使用余弦相似度计算得到文档中最相似的候选词作为关键词。
2.2 Keybert提取关键词流程

Keybert提取关键词流程如上图所示,主要包括三个流程:
第一步,使用Bert获取文档/候选词的embedding表示;

这里需要注意的是文档embedding质量的好坏会影响关键词抽取的结果。Keybert支持从sentence_transformers、Flair、Hugginface Transformers、spaCy等下载预训练模型对文档进行embedding编码;
第二步,使用词嵌入模型提取n-gram词或者关键词作为候选词,这里可以是sklearn中的CountVectorizer或者Tfidf等方法;

第三步,计算文档和候选词的余弦相似度,找到最能表示文档的关键词。

2.3 Keybert如何解决多样性问题
了解了Keybert提取关键词的流程后,下面通过一个实际的例子查看Keybert抽取效果,同时了解下作者是如何解决多样性问题。使用下面的英文文档:

使用Keybert抽取top5的候选关键词结果如下:

上面抽取的5个候选关键单词可以很好的代表文档内容即有监督学习定义。相比于单词,我们还可以抽取词组作为候选关键词,把n_gram_range设置成(3,3)则可以使用3个单词组成的词组作为候选关键词,抽取结果如下:

虽然使用3-gram词组相比于单个词来说更能代表关键词,但是存在的问题是词组之间十分相似。Keybert的作者认为词组之间比较相似主要原因在于这些词是最能代表文档的关键词, Keybert主要通过MSS(Max Sum Similarity)和MMR(Maximal Marginal Relevance)两种算法来提升关键词的多样性。
2.3.1 Max Sum Similarity算法
MSS算法思想是先找到topN相似的单词或词组作为候选词nr_candidates,然后从nr_candidates中找到最不像的topK作为候选关键词。MSS算法实现代码:

通过MSS可以提升抽取关键词的多样性,当MSS中的nr_candidates设置过小时基本和余弦相似度结果类似,基本失去作用;但是当nr_candidates设置过大时则容易导致提取关键词不准。下面是MSS中的nr_candidates的对关键词抽取结果影响:

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢