

Paper: https://arxiv.org/pdf/2211.05783.pdf
Code: https://github.com/autonomousvision/unimatch
导读
光流估计、立体匹配和深度估计是计算机视觉中常见的任务,即通过多视角的场景的稠密特征匹配从一组二维图像中理解三维场景结构和运动。传统方法通常使用优化方法来解决这些任务,例如光流的变分方法、立体视觉的半全局匹配(Semi-Global Matching)、从SFM中的光束平差法(Bundle Adjustment)。虽然经典方法取得了重要进展,但它们在无纹理区域和细结构等具有挑战性的情况下仍然存在困难。深度学习和大规模数据集的快速发展也使得可以使用复杂的深度神经网络直接对几何和运动进行前馈推理。目前基于学习的方法正在benchmark上占主导地位。
背景
作者认为现有的方法大多是通过设计特定于任务的模型来独立解决每个任务,直观的想法是能否存在一个网络同时解决光流估计,立体匹配和深度估计这三个比较接近的几何问题。为了实现这一目标,作者首先确定了阻碍先前模型普遍适用性的主要障碍:先前的方法主要将任务特定的cost volume作为模型中间组件,并使用后续卷积网络进行光流/差异/深度回归。由于cost volume是任务相关的(例如,光流的cost volume通常基于2D邻域相关,而立体匹配网络通过1D相关而深度估计是3D相关),这就需要任务相关的卷积网络用于cost volume的后处理,参数并不共享。此外,卷积网络的类型也可能相当不同(2D,3D或Conv-GRU)。这给统一这些任务的pipeline中引入了额外的挑战。
这篇论文的关键见解是,这些任务可以统一为明确的几何特征密集匹配问题,通过直接比较特征相似性来解决。统一模型自然地实现了跨任务迁移,因为每个任务都使用完全相同的可学习参数来进行特征提取。例如,在没有任何微调的情况下,预训练的光流模型可以直接用于立体匹配任务和深度估计任务。而且,当使用预训练的光流模型作为初始化进行微调时,既可以得到更快训练速度,而且还可以取得更好的性能。
这项工作是GMFlow的重大扩展,其中新的贡献如下:
-
统一光流估计/立体匹配/深度估计任务。GMFlow的目的是证明其是RAFt这类迭代架构的在光流估计任务中的有效替代方案,而这项工作统一了三个密集匹配估计任务,将GMFlow扩展到立体匹配和深度估计,并进行了大量实验 -
复用预先训练的光流模型来研究跨任务迁移行为 -
引入额外的后处理步骤,进一步提高了原始GMFlow的性能
在10个流行的数据集上论文展示了最先进的或高度有竞争力的性能
方法
不同视点之间的密集匹配关系是光流、立体匹配和深度估计任务的核心。为了统一这三个任务,本文的关键思想是使用一个显式的密集匹配方法,它通过直接比较特征相似性来识别匹配,因此需要一个较强的特征。因此作者使用上文GMFlow的Transformer来提取用于匹配的强特征。请注意,匹配层是根据每个任务的不同约束设计的,因此是特定于任务的。但是,匹配层是无参数的,因为它们只比较特征相似性。所有三个任务的可学习参数完全相同,因此可以复用进行跨任务迁移。
两个图像I1和I2作为输入。可以是用于光流的视频帧,用于立体匹配的对齐的立体对,或者用于深度估计的未校正的立体像对(已知相机内参和外参)。首先利用权重共享卷积网络提取8倍降采样密集特征,然后通过任务无关的GMFlow的Transformer来进行特征增强得到F1,F2。然后输入光流匹配、立体匹配和深度估计各自的无参数任务特定匹配层:
Flow Matching
光流表示两个视频帧之间的运动,可以通过在图像二维平面上寻找二维像素密集匹配来计算。为了实现这一点,直接进行全局匹配,比较F1中每个位置与F2中所有位置的特征相似性。
-
计算一个二维匹配相关性矩阵
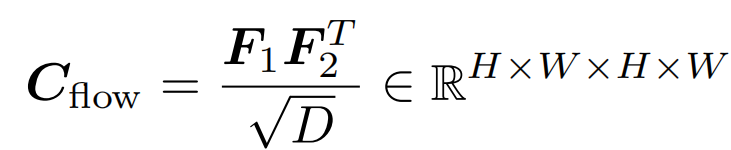
-
使用可微的softmax,得到匹配分布情况
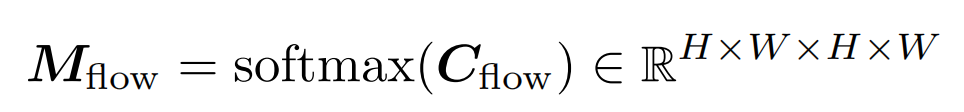
-
与像素网格的二维坐标G加权平均得到亚像素匹配
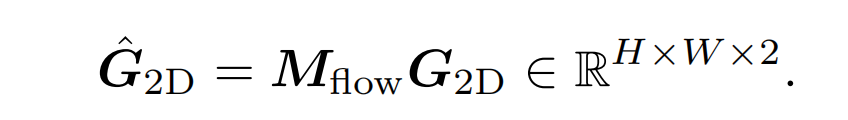
-
计算相应的像素坐标之间的差值,可以得到光流
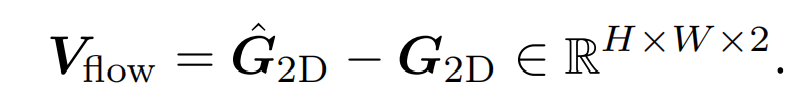
Stereo Matching
立体匹配的目的是找到立体对之间沿水平扫描线的像素视差即一维对应(原匹配图像对做了极线校正),这可以看作是二维光流的一种特殊情况。不像上面光流中的二维全局匹配,我们只需要考虑沿着一维水平方向的匹配。
-
计算一个一维匹配相关性矩阵
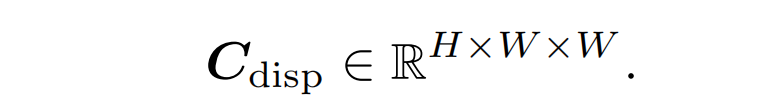
-
使用可微的softmax,得到匹配分布情况
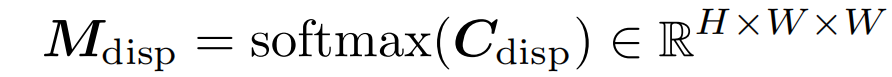
-
与水平位置分布加权平均得到亚像素匹配
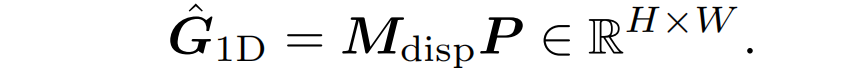
-
计算相应的像素坐标之间的水平方向的差值,可以得到视差
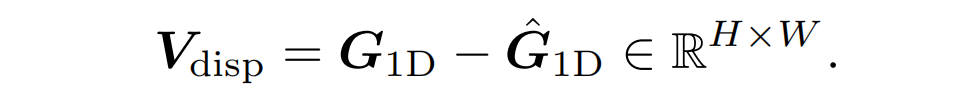
Depth Matching
对于末进行极线矫正的双目深度估计, 作者假设图像I1和I2的相机内参和外参是已知的。
-
离散化深度范围,然后对于每个深度候选,与世界坐标系中的像素网格的二维坐标G进行wrap,得到相机系的2D坐标对应关系
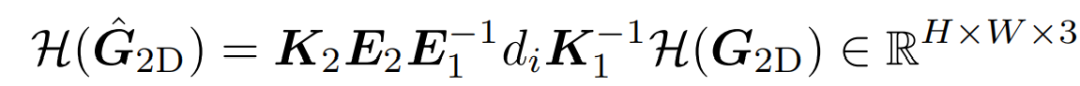
-
使用G对F进行双线性插值采样, 得到深度候选d的F^2。然后计算它们的相关性为
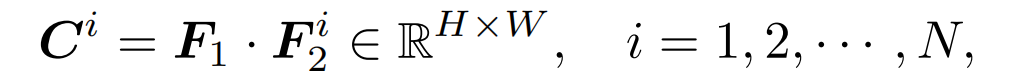
-
concat得到的所有候选深度的相关性
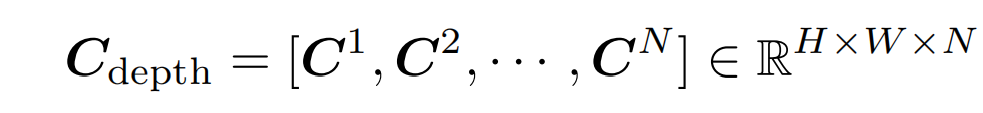
-
使用可微的softmax,得到匹配分布情况
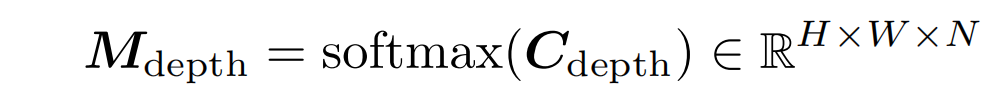
-
通过计算所有候选深度的匹配分布加权平均值,可以得到深度
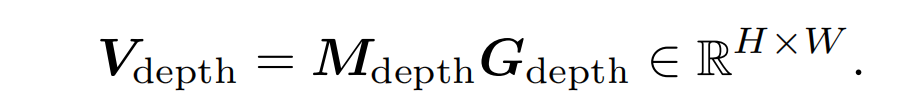
分别将上述光流、立体匹配和深度估计的模型分别命名为GMFlow、GMStereo和GMDepth
细化(后处理)
前文提出的方法(使用1/8像素的特性)已经实现了具有竞争力的性能,简单且高效,接下来为了适应不同的任务,论文探索了两种类型的细化方法来进一步提升性能。
-
层次匹配细化: 层次匹配细化使用的就是前文的基于Transformer+softmax的全局匹配思路,因此是与任务无关的。该统一全局匹配方法在1/8的特征分辨率下进行,并获得了1/8的光流/视差/深度预测。为了提高性能和细粒度细节,这里采用全局加局部特征融合的思路,即将1/8的光流/视差/深度预测进行上采样到1/4分辨率,作为GMFlow中第一个CNN的输出,同时wrap得到第二个CNN的输出,两者输入到GMFlow的Transformer层进行特征增强,再通过一个local match的方式得到预测的光流/视差的残差添加到之前通过全局匹配获得的上采样流/视差预测中。可以注意到,在1/8和1/4的层次匹配阶段,论文的方法共享了Transformer和self-attention权重,因为除了不同的范围(全局和局部)外,它们基本上执行了非常相似的匹配过程。这不仅减少了参数,而且提高了泛化性。 -
局部回归细化:
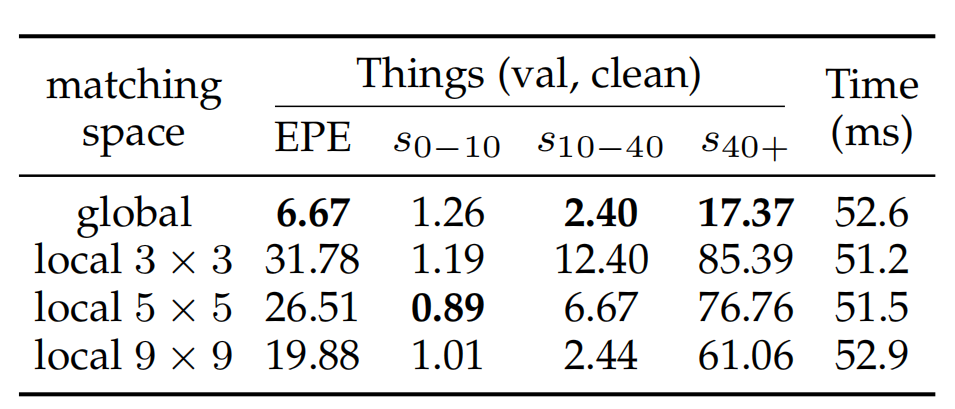
前文的结果显示,统一模型加一个任务无关的层次匹配细化,能够超过31次的细化的RAFT,这证明了基于全局匹配的范式的有效性。如上图所示,我们的统一全局匹配方法在大运动的情况下更具优势。但是对于小的运动,可能不需要执行全局匹配,在这种情况下,局部回归(cost volume + conv)是有利的。为了实现最佳的性能,一个简单的方法是结合这两种光流估计方法的优点。也就是说,局部回归方法被用作我们的统一模型的后处理步骤。这进一步改善了细粒度的细节和难以匹配的区域。
这种局部回归是任务相关的:
-
对于光流,论文使用二维correlation;对于校正的立体匹配,论文也使用correlation,因为论文发现虽然存在一些冗余,但它的表现优于一维correlation;对于未校正的深度估计,论文使用由当前深度预测和相对位姿转换构造的二维correlation。这种细化架构是特定于任务的,而不是在任务之间共享的。 -
对于不同的任务,附加迭代细化的可选数量也有所不同,论文根据经验选择这个数字。对于光流,在层次匹配细化后,论文在1/4特征分辨率下使用6个额外的细化步骤;对于修正的立体匹配,论文在层次匹配细化后,使用了1/4特征分辨率的3个额外的细化步骤;对于未修正的深度估计,论文使用1个额外的细化步骤
实验
双目立体匹配
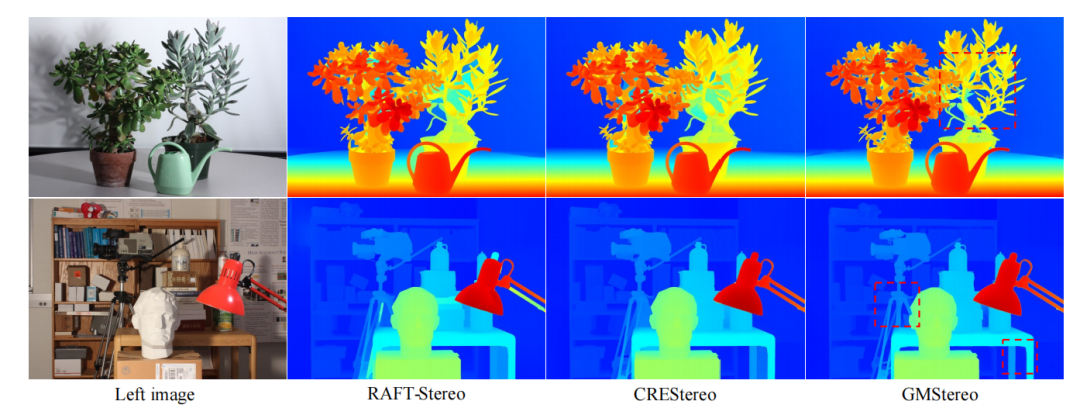
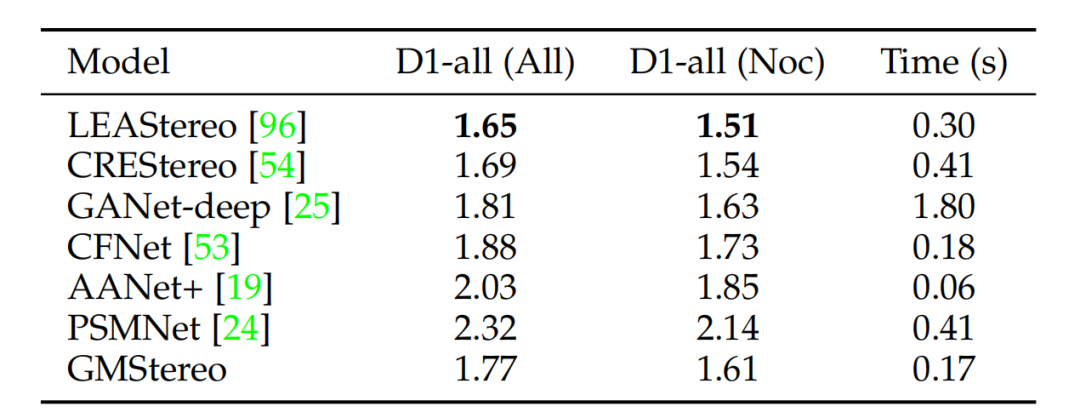
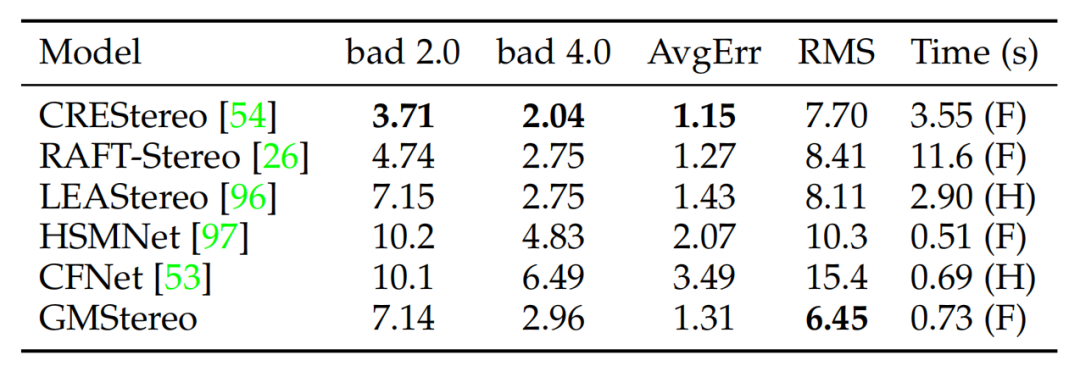
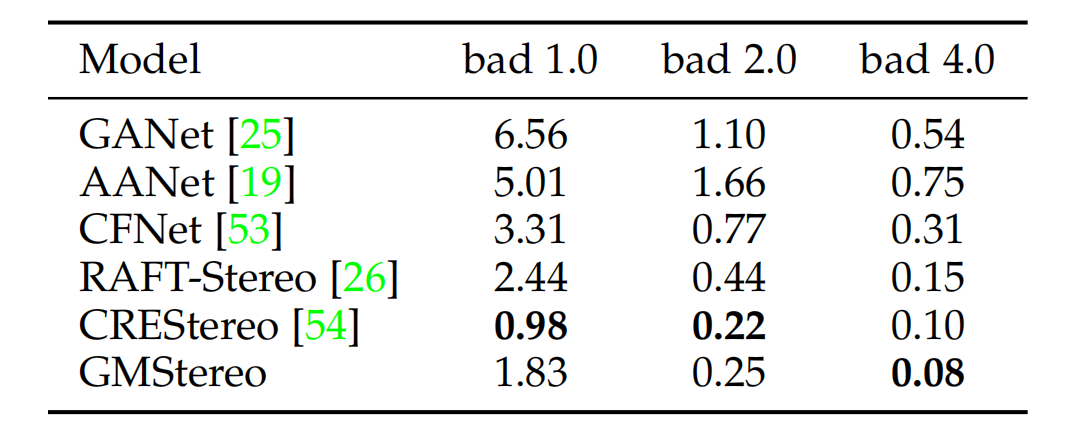
与光流估计任务类似,论文使用额外的特定于任务的基于local match的局部回归细化来进一步提高性能。虽然校正后的立体匹配是一维匹配任务,但作者发现在“cost volume + 卷积”的回归方法中,二维相关性优于一维相关性。因此,最终的模型除了在1/4特征分辨率下的1个层次匹配细化外,还使用了3个额外的细化。与RAFTStereo 和CRETStereo相比,论文的最终模型所需的改进次数要小得多,归功于强大的特征增强。最终结果如上图所示,论文的方法在多个数据集取得最先进或者高度竞争力的性能,同时在模型设计和推理速度方面更简单、更高效。
深度估计
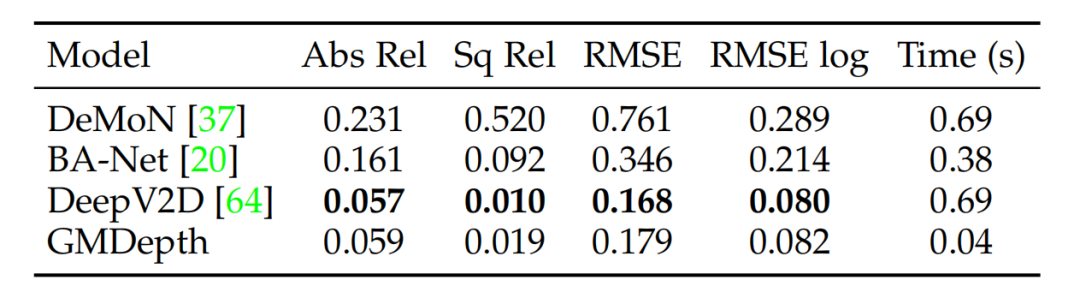
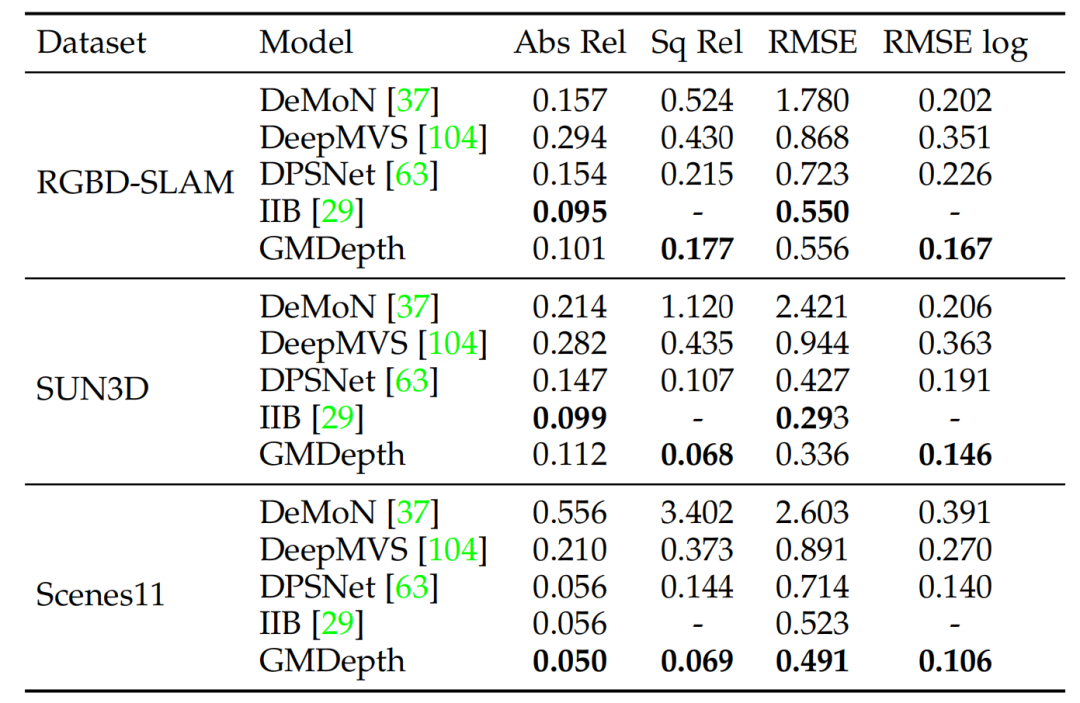
论文在1/8的特征分辨率下使用了一个额外特定于任务的基于local match的局部回归细化,这进一步提高了性能同时保持较快的推理速度。最终结果如上图所示,本文方法在多个数据集取得最先进或者高度竞争力的性能,同时在模型设计和推理速度方面更简单、更高效。
跨任务迁移
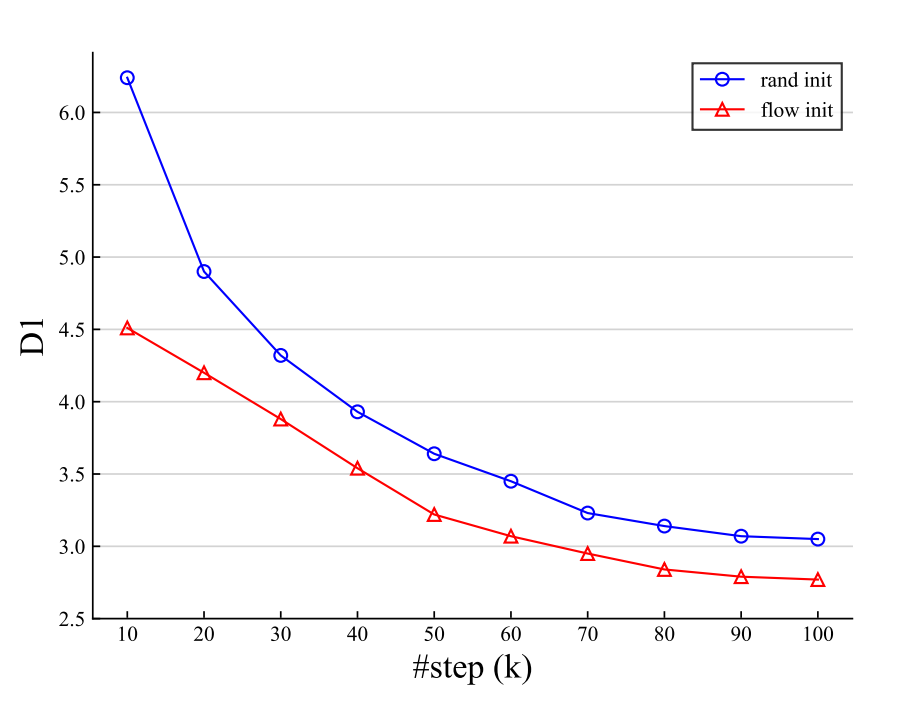
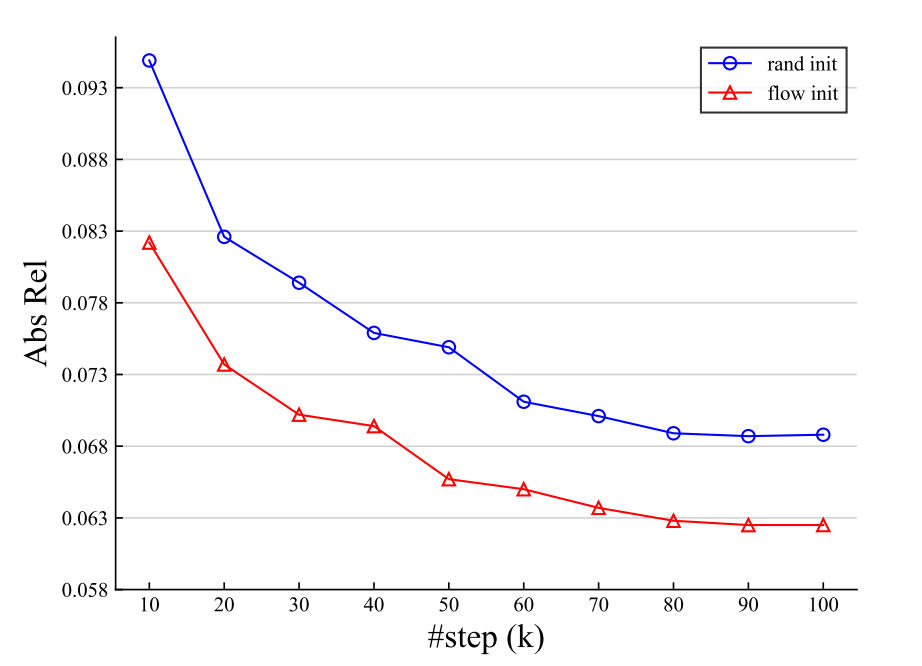
论文的统一模型的还有一个独特好处是,它很自然地支持跨任务迁移,因为所有的任务的可学习参数都是完全相同的。更具体地说,可以直接使用预先训练好的光流模型,并将其应用于立体匹配和立体深度估计任务。如上图所示,其预训练光流模型的性能明显优于随机初始化模型。

值得注意的是,以往没有光流模型可以直接用于未校正的立体深度估计,而所提模型取得了良好的结果,如上图所示。预训练的流模型可以进一步细化立体和深度任务,不仅可以加快训练速度,而且比随机初始化获得更好的性能
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢