
来自爱可可的前沿推介
Meta-prediction Model for Distillation-Aware NAS on Unseen Datasets
未见数据集上的蒸馏感知NAS元预测模型
要点:
-
提出一种跨数据集、架构和教师泛化的新的元预测模型,可以在蒸馏给定教师知识时准确预测架构性能;
-
基于特定教师对学生的参数重映射和重映射学生的功能性嵌入,提出一种新的蒸馏感知任务编码;
-
在异构不可见 DaNAS 任务的准确性估计方面优于现有的快速 NAS 方法。
一句话总结:提出一种跨数据集、体系结构和教师泛化的新的元预测模型,以便在蒸馏给定教师网络的知识时准确预测架构性能,在看未见数据集上优于现有的快速 NAS 方法。
论文:https://openreview.net/forum?id=SEh5SfEQtqB
摘要:
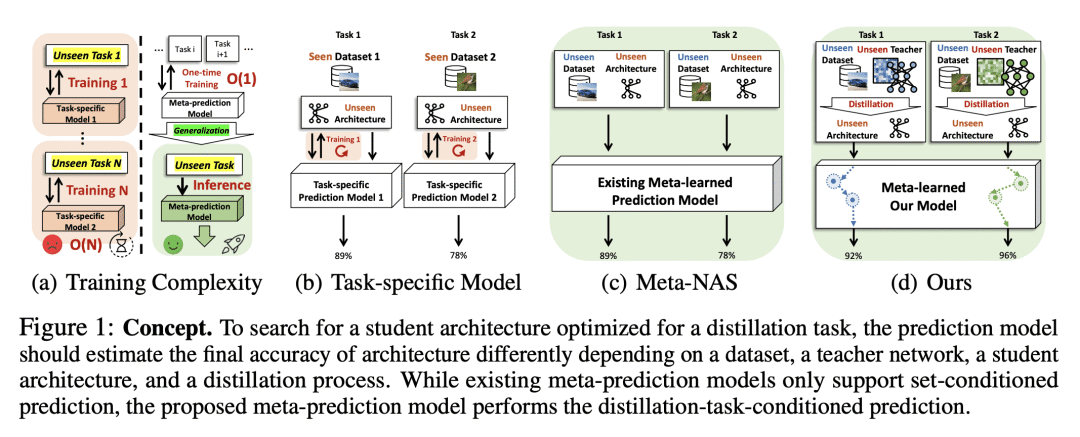
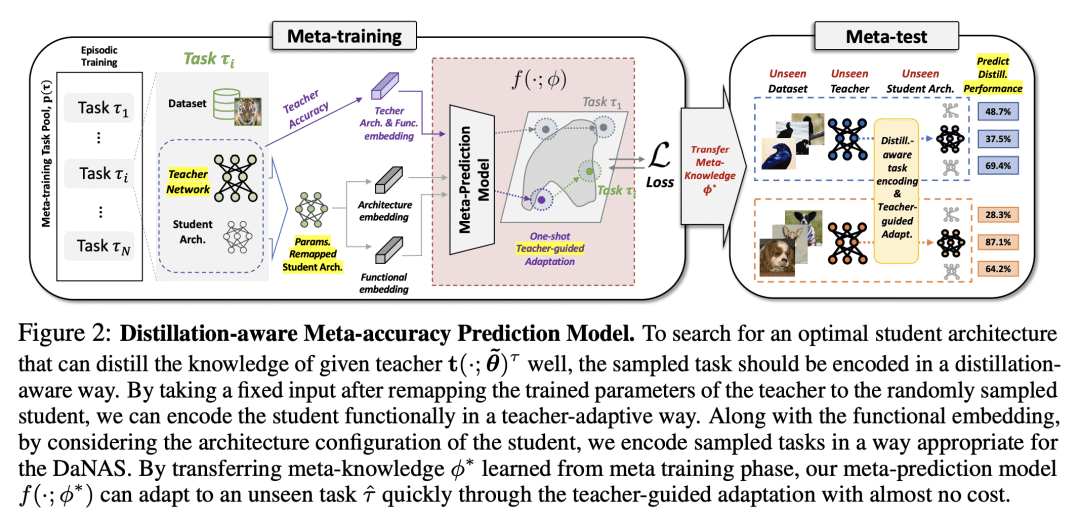
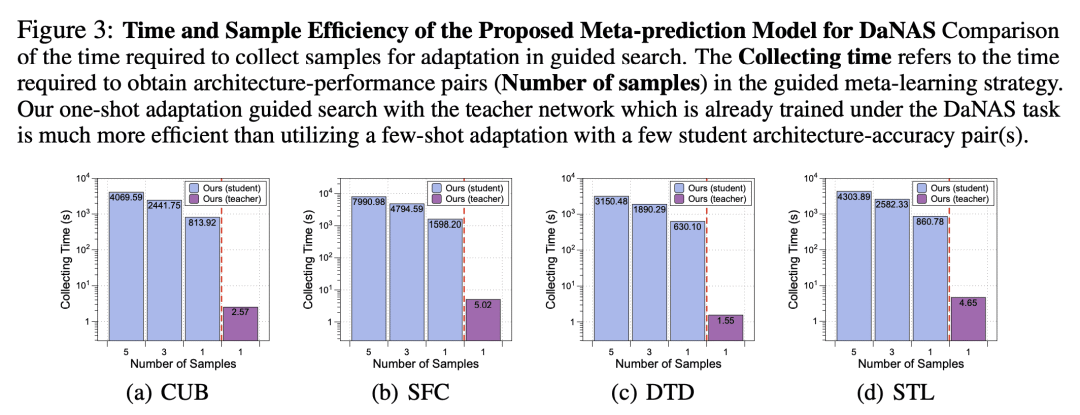
蒸馏感知网络架构搜索(DaNAS),旨在搜索在从给定教师模型中蒸馏知识时,可获得最佳性能和/或效率的最佳学生架构。之前的 DaNAS 方法主要涉及寻找固定源/目标任务和教师的网络架构,这些任务在新任务上没有很好地泛化,因此需要对域和教师的新组合进行昂贵的搜索。对于没有 KD 的标准 NAS 任务,提出了基于元学习的计算高效 NAS 方法,该方法学习多个任务的广义搜索过程,并将这些任务获得的知识迁移到新任务中。然而,由于假设在没有老师 KD 的情况下从头开始学习,它们可能不适合 DaNAS 场景,这可能会显著影响从搜索中获得的架构的最终准确性。为了消除 DaNAS 方法的过度计算成本和快速 NAS 方法的次优性,本文提出一种基于蒸馏感知的元精度预测模型,可以预测给定架构在与给定教师执行 KD 时在数据集上的最终性能,而无需在目标任务上进行实际训练。实验结果表明,所提出的元预测模型成功地泛化到 DaNAS 任务的多个未见数据集,在很大程度上优于现有的元 NAS 方法和快速 NAS 基线。
Distillation-aware Network Architecture Search (DaNAS) aims to search for an optimal student architecture that can obtain the best performance and/or efficiency when distilling the knowledge from a given teacher model. Previous DaNAS methods have mostly tackled the search for the network architecture for a fixed source/target tasks and the teacher, which are not generalized well on a new task, thus need to perform costly search for any new combination of the domains and the teachers. For standard NAS tasks without KD, meta-learning-based computationally efficient NAS methods have been proposed, which learn the generalized search process over multiple tasks and transfer the knowledge obtained over those tasks to a new task. However, since they assume learning from scratch without KD from a teacher, they might not be ideal for DaNAS scenarios, which could significantly affect the final accuracies of the architectures obtained from the search. To eliminate excessive computational cost of DaNAS methods and the sub-optimality of rapid NAS methods, we propose a distillation-aware meta accuracy prediction model which can predict a given architecture's final performances on a dataset when performing KD with a given teacher, without having to actually train it on the target task. The experimental results demonstrate that our proposed meta-prediction model successfully generalizes to multiple unseen datasets for DaNAS tasks, largely outperforming existing meta-NAS methods and rapid NAS baselines.

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢