2022 年已经接近尾声。深度学习模型在生成图像方面的表现愈发出色,显然,未来该模型还将继续发展。今天的局面是如何一步步发展而来的呢?这得追溯到十年前,也就是当今所说的 “AI 之夏” 的起源。下文以时间轴的形式追溯了一些里程碑,从论文、架构、模型、数据集到实验。
Hacker News 评论中有人指出,Hinton 等人的深度信念网早在 2006 年就被用于生成合成 MNIST 数字,参见深度信念网的快速学习算法 。
Durk Kingma 让我注意到变分自动编码器 (VAEs) 稍微先于 GANs,参见自动编码变分贝叶斯和这些早期结果在野外标记面部数据集。
@Merzmensch 在推特上强调了 DeepDream 的重要性,它可以被视为一种原始生成方法,对于图像合成的艺术方面。参见 inception: 深入神经网络。
起源 (2012-2015)
一旦知道深度神经网络将彻底改变图像分类,研究人员就开始朝着 “相反” 的方向探索:如果可以使用一些能有效分类的技术 (例如卷积层) 来制作图像呢?
Hello world!这是 GAN 生成的人脸样本,来自 Goodfellow 等人 2014 年的论文。该模型是在 Toronto Faces 数据集上训练的,该数据集已从网络上删除。
2012 年 12 月:“AI 之夏” 的开始。Hinton 等人撰写的《ImageNet Classification with Deep Convolutional Neural Networks》一文发布,他们第一次将深度卷积神经网络 (CNN)、GPU 和来自互联网的大型数据集 (ImageNet) 结合在一起。

论文链接:https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
2014 年 12 月:Ian Goodfellow 等人发表了《Generative Adversarial Nets》。GAN 是 2012 年之后第一个致力于图像合成而非分析的现代神经网络架构。它引入了一种基于博弈论的独特学习方法,其中两个子网络 ——“生成器” 和 “鉴别器” 互相竞争。最终,只有 “生成器” 从系统中保留下来,用于图像合成。

论文链接 https://proceedings.neurips.cc/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf
2015 年 11 月:《Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks》发表,描述了第一个实际可用的 GAN 体系结构 (DCGAN),并且首次提出了潜在空间操纵的问题 —— 概念是否映射到潜在空间方向?

论文链接:https://arxiv.org/pdf/1511.06434.pdf
Mario Klingenmann 所作《路人回忆 I》,2018 年。培根式的脸是这一领域 AI 艺术的典型,生成模型的非摄影现实主义是艺术探索的焦点。
GAN 可以应用于各种图像处理任务,如风格迁移,图像修复,去噪和超分辨率。与此同时,GAN 的艺术实验开始兴起,Mike Tyka、Mario Klingenmann、Anna Ridler、Helena Sarin 等人的第一批作品相继出现。2018 年发生了第一桩 “人工智能艺术” 丑闻 —— 三名法国学生借用一位美国 19 岁高中毕业学生开源的 AI 算法创作的画作在佳士得拍卖行拍得 43 万美元。与此同时, transformer 架构彻底改变了 NLP,并且在不久的将来对图像合成产生了重大影响。
2017 年 6 月:文章《Attention is all you need》发表。transformer 架构 (以 BERT 等预训练模型的形式) 彻底改变了自然语言处理 (NLP) 领域。

论文链接:https://arxiv.org/pdf/1706.03762.pdf
2018 年 7 月:文章《Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning》发表。对于后来的 CLIP 和 DALL-E 这样的模型来说,这篇文章和其他多模态数据集将变得至关重要。

论文链接:https://aclanthology.org/P18-1238.pdf
该面孔来自 thispersondoesnotexist.com 网站。2010 年代后期 GAN 架构的质量主要是在对齐的人脸图像上进行评估,而对于更异构的数据集,其成功程度有限。因此,在学术 / 工业和艺术实验中,人物面孔仍是重要参照依据。
2018 年 - 2020 年:NVIDIA 研究人员对 GAN 架构进行了一系列重要改进。GAN 生成的图像第一次做到与自然图像高度相似,至少对于像 Flickr-Faces-HQ (FFHQ) 这样高度优化的数据集来说是如此。

论文链接:https://arxiv.org/pdf/1812.04948.pdf
2020 年 12 月:文章《Taming Transformers for High-Resolution Image Synthesis》发布。Vision transformer (ViT) 表明,transformer 架构可以用于图像。本文中提出的方法 ——VQGAN 取得了 SOTA 结果。

论文链接:https://arxiv.org/pdf/2012.09841.pdf
Transformer 时代(2020-2022)
Transformer 架构彻底变革了图像合成的方式,GAN 的使用也逐渐开始减少。「多模态」深度学习巩固了来自 NLP 和计算机视觉的技术,「prompt 工程」取代了模型训练和微调,成为图像合成的新兴方法。
论文《Learning transferable visual models from natural language supervision》提出了 CLIP 架构,引入了多模态功能,推动了当前图像合成的热潮。

CLIP 是一种结合了视觉 transformer 和正则化 transformer 的多模态模型,学习图像和文本描述的「共享潜在空间」。
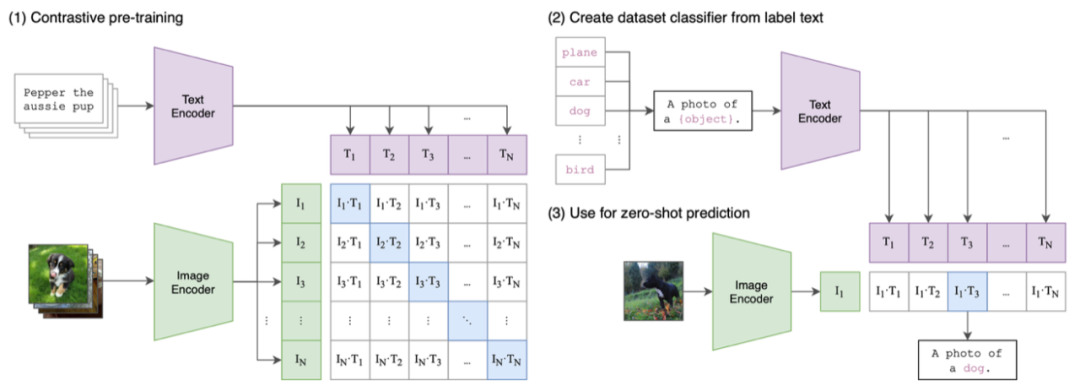
论文链接:https://arxiv.org/pdf/2103.00020.pdf
2021 年 1 月,论文《Zero-shot text-to-image generation》发布,其中提出了 DALL-E 的第一个版本。该模型的原理是在单个数据流中组合文本和图像(被 VAE 压缩为「token」),模型只是简单地「续写句子」。训练数据(250M 图像)包括来自 Wikipedia、Conceptual Captions 和 YFCM100M (http://projects.dfki.uni-kl.de/yfcc100m/) 的文本 - 图像对。CLIP 为图像合成的「多模态」方法奠定了基础。

论文链接:https://arxiv.org/pdf/2102.12092.pdf
下图是 DALL-E 2 模型的一个生成例子,文本描述是「一个金发女人的肖像照片,用单反相机拍摄,中性背景,高分辨率」。

2021 年 6 月,论文《Diffusion models beat GANs on image synthesis》发表。扩散模型引入了一种不同于 GAN 的图像合成方法,从噪声中重建图像。

论文链接:https://arxiv.org/abs/2105.05233
2021 年 7 月,DALL-E mini (https://huggingface.co/spaces/dalle-mini/dalle-mini) 发布,它是 DALL-E 的复制版本(比 DALL-E 更小,但对架构和数据的调整很少)。

2022 年 4 月,论文《Hierarchical text-conditional image generation with CLIP latents》提出了以 GLIDE 为基础的 DALL-E 2。

论文链接:https://arxiv.org/pdf/2204.06125.pdf
2022 年 5 月,论文《Photorealistic text-to-image diffusion models with deep language understanding (https://arxiv.org/pdf/2205.11487.pdf)》提出了 Imagegen 和 Parti,这是谷歌对标 DALL-E 2 的两个模型。
论文链接:https://arxiv.org/pdf/2206.10789.pdf
Photoshop 一般的人工智能 (2022 至今)
虽然 DALL-E 2 为图像模型设置了一个新的标准,但它的商业化限制了模型的创造性。虽然 DALL-E 2 已经发布,但大部分用户仍在继续使用 DALL-E mini。
而这一切随着 Stable Diffusion 的发布发生了改变,Stable Diffusion 标志着图像合成进入「Photoshop 时代」。
2022 年 8 月,Stability.ai 发布了 Stable Diffusion,这个模型可以实现与 DALL-E 2 相同的照片真实感,最重要的是该模型公开可用,并且可以在 CoLab 和 Huggingface 平台上运行。
下图是 Stable Diffusion 生成的巴洛克风格的艺术画作:

谷歌也不甘落后,也是在 2022 年 8 月,谷歌发布了一种「个性化」的文本到图像扩散模型 ——DreamBooth。

论文地址:https://arxiv.org/pdf/2208.12242.pdf
2022 年 10 月,全球最大图片交易商 Shutterstock 宣布与 OpenAI 合作,提供 / 授权生成图像,预计图片市场将受到 Stable Diffusion 等生成模型的严重影响。
原文链接:https://zentralwerkstatt.org/blog/ten-years-of-image-synthesis
内容中包含的图片若涉及版权问题,请及时与我们联系删除





评论
沙发等你来抢