
来自今天的爱可可AI前沿推介
[LG] NeRF in the Palm of Your Hand: Corrective Augmentation for Robotics via Novel-View Synthesis
A Zhou, M J Kim, L Wang, P Florence, C Finn
[Stanford & MIT CSAI & LGoogle]
手眼NeRF:基于新视图合成的机器人纠正性增强
要点:
-
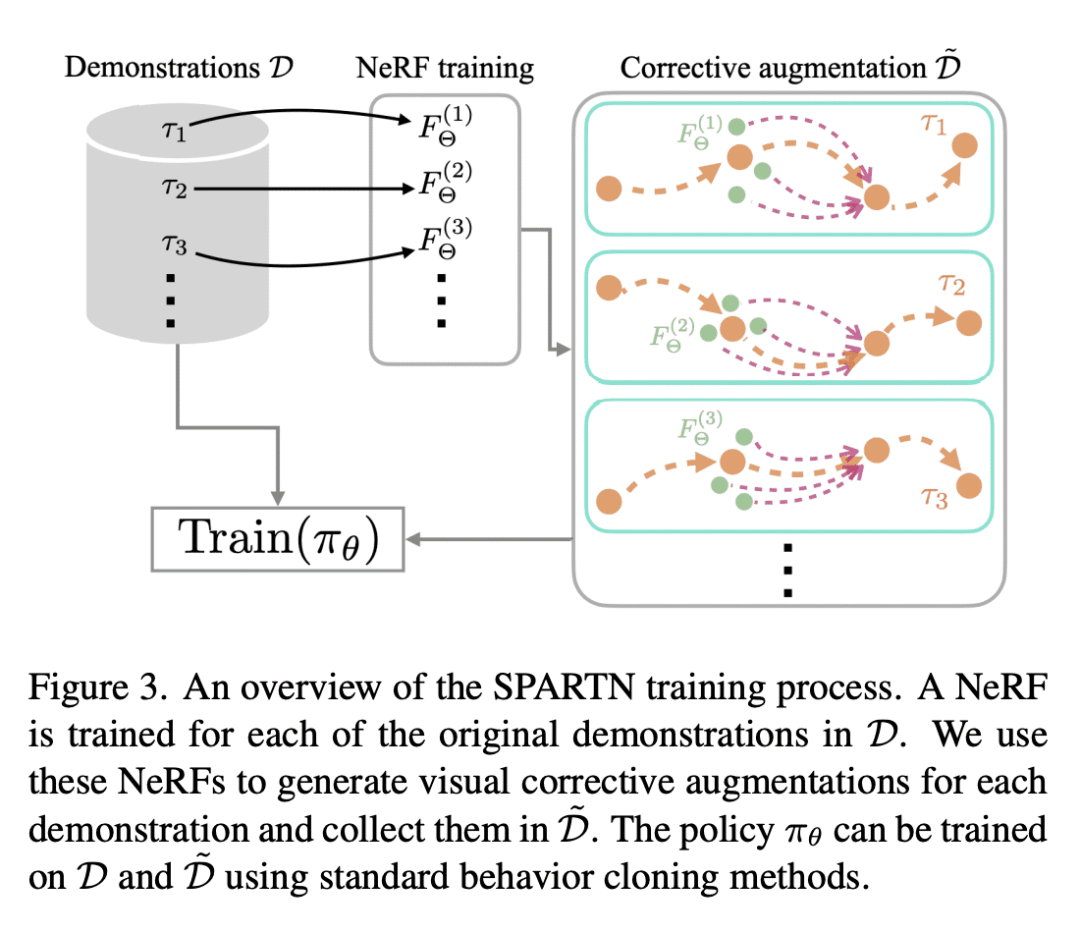
提出 SPARTN(Synthetic Perturbations for Augmenting Robot Trajectories via NeRF),一种完全离线的数据增强方案,用于改进使用手眼(eye-in-hand)相机的机器人策略; -
使用神经辐射场(NeRF)向视觉演示合成性注入纠正噪声,产生扰动的视角,同时计算纠正性行动; -
在模拟 6-DoF 视觉抓取基准上,SPARTN 比没有纠正增强的模仿学习提高了2.8倍的成功率,甚至超过了一些使用在线监督的方法。
一句话总结:
SPARTN是一种基于NeRF的数据增强技术,通过在视觉演示中合成性注入纠正噪声来改进6-DoF视觉抓取策略,从而提高了模拟世界和真实世界抓取任务的性能,不需要额外的专家监督或环境互动。
摘要:
专家演示是训练视觉机器人操纵策略的丰富监督来源,但模仿学习方法往往需要大量的演示或昂贵的在线专家监督来学习反应性闭环行为。本文提出SPARTN(Synthetic Perturbations for Augmenting Robot Trajectories via NeRF):一种完全离线的数据增强方案,用于改善使用手眼(eye-in-hand)相机的机器人策略。该方法利用神经辐射场(NeRF)在视觉演示中合成性注入纠正噪声,用 NeRF 生成扰动性视角,同时计算纠正性行动。不需要额外的专家监督或环境互动,并将 NeRF 的几何信息提炼成实时反应的纯RGB策略。在一个模拟的 6DoF 视觉抓取基准中,SPARTN 比没有纠正性增强的模仿学习提高了2.8倍的成功率,甚至超过了一些在线监督的方法。此外,它还缩小了纯 RGB 和 RGB-D 成功率之间的差距,消除了之前对深度传感器的需求。在现实世界的 6DoF 机器人抓取实验中,所提出方法平均提高了22.5%的绝对成功率,包括那些传统上对基于深度的方法具有挑战性的物体。
Expert demonstrations are a rich source of supervision for training visual robotic manipulation policies, but imitation learning methods often require either a large number of demonstrations or expensive online expert supervision to learn reactive closed-loop behaviors. In this work, we introduce SPARTN (Synthetic Perturbations for Augmenting Robot Trajectories via NeRF): a fully-offline data augmentation scheme for improving robot policies that use eye-in-hand cameras. Our approach leverages neural radiance fields (NeRFs) to synthetically inject corrective noise into visual demonstrations, using NeRFs to generate perturbed viewpoints while simultaneously calculating the corrective actions. This requires no additional expert supervision or environment interaction, and distills the geometric information in NeRFs into a real-time reactive RGB-only policy. In a simulated 6-DoF visual grasping benchmark, SPARTN improves success rates by 2.8× over imitation learning without the corrective augmentations and even outperforms some methods that use online supervision. It additionally closes the gap between RGB-only and RGB-D success rates, eliminating the previous need for depth sensors. In real-world 6-DoF robotic grasping experiments from limited human demonstrations, our method improves absolute success rates by 22.5% on average, including objects that are traditionally challenging for depth-based methods.
论文链接:https://arxiv.org/abs/2301.08556


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢