
来自今天的爱可可AI前沿推介
[CV] Novel-View Acoustic Synthesis
C Chen, A Richard, R Shapovalov, V K Ithapu, N Neverova, K Grauman, A Vedaldi
[University of Texas at Austin & Reality Labs Research at Meta & FAIR]
新视角声学合成
要点:
-
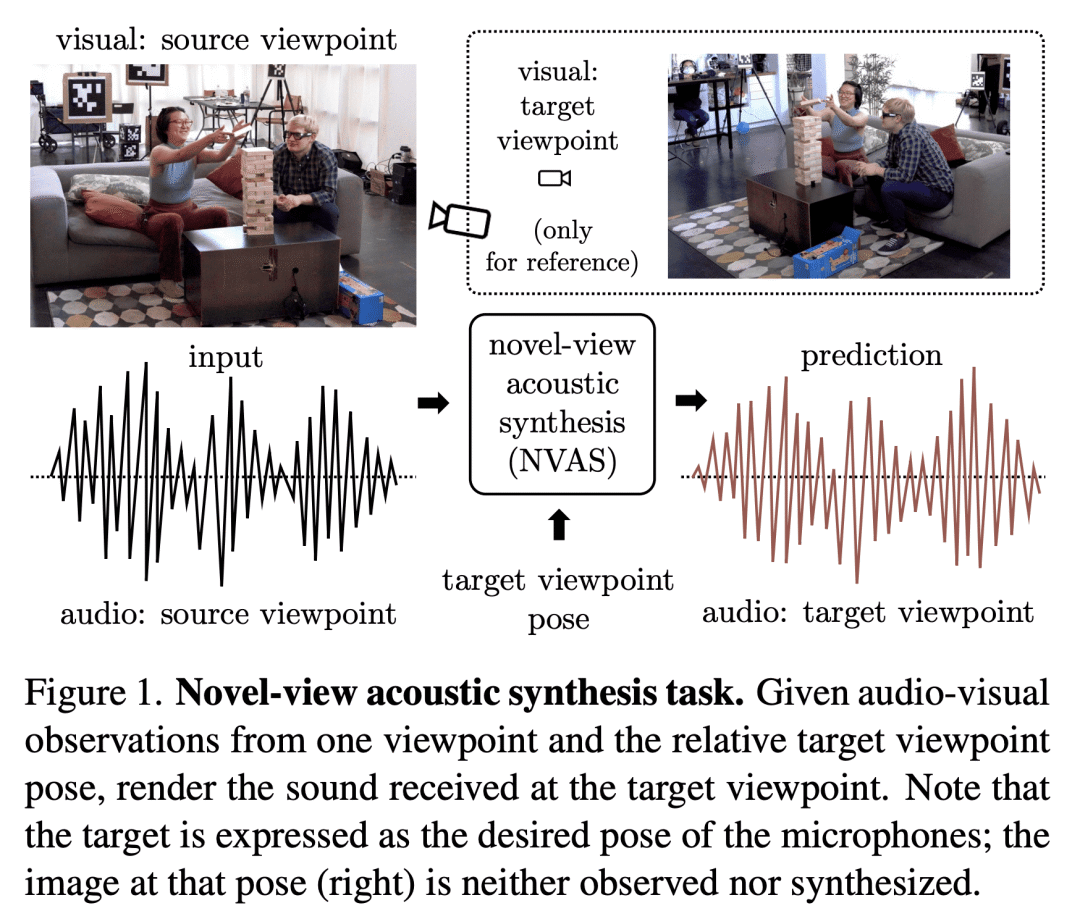
提出新视图声学合成(NVAS)任务:给定在源视图观察到的视觉和声音,能否从一个看不见的目标视图合成该场景的声像? -
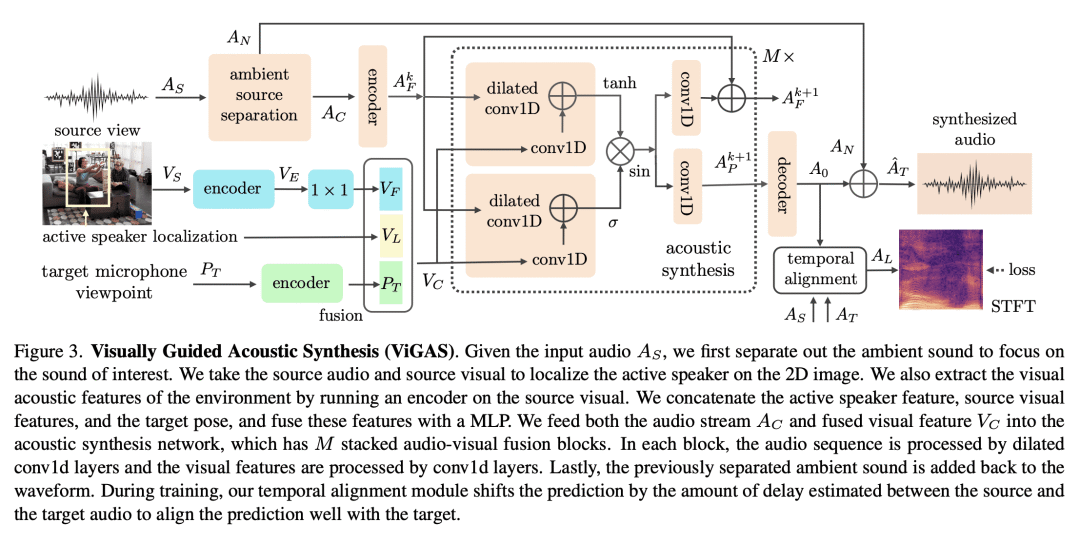
提出一种神经渲染方法,即视觉引导声学合成(ViGAS)网络,通过分析输入的视听线索,学习合成空间中任意点的声音; -
收集了两个大规模多视角视听数据集,一个是合成的,一个是真实的,作为NVAS任务的基准。
一句话总结:
提出了一种新视图声学合成任务,一个神经渲染模型和两个基准数据集,通过对观察到的音频和视觉流进行推理,学习将声音从源视角转换到目标视角,在两个数据集上超越了所有基线,激发了AR/VR和艺术设计中的潜在应用。
摘要:
本文提出新视图声学合成(NVAS)任务:给定在源视图观察到的视觉和声音,能否从一个看不见的目标视图合成该场景的声像?本文提出一种神经渲染方法——视觉引导声学合成(ViGAS)网络,通过分析输入的视听线索来学习合成空间中任意点的声音。为确定这项任务的基准,本文收集了两个大规模多视角视听数据集,一个是合成的,一个是真实的。所提出模型成功地推理了空间线索并在两个数据集上合成了忠实的音频。本文工作代表了解决新视图声学合成任务的第一个范式、数据集和方法,具有令人兴奋的潜在应用,包括AR/VR、艺术和设计。
We introduce the novel-view acoustic synthesis (NVAS) task: given the sight and sound observed at a source viewpoint, can we synthesize the \emph{sound} of that scene from an unseen target viewpoint? We propose a neural rendering approach: Visually-Guided Acoustic Synthesis (ViGAS) network that learns to synthesize the sound of an arbitrary point in space by analyzing the input audio-visual cues. To benchmark this task, we collect two first-of-their-kind large-scale multi-view audio-visual datasets, one synthetic and one real. We show that our model successfully reasons about the spatial cues and synthesizes faithful audio on both datasets. To our knowledge, this work represents the very first formulation, dataset, and approach to solve the novel-view acoustic synthesis task, which has exciting potential applications ranging from AR/VR to art and design. Unlocked by this work, we believe that the future of novel-view synthesis is in multi-modal learning from videos.
论文链接:https://arxiv.org/abs/2301.08730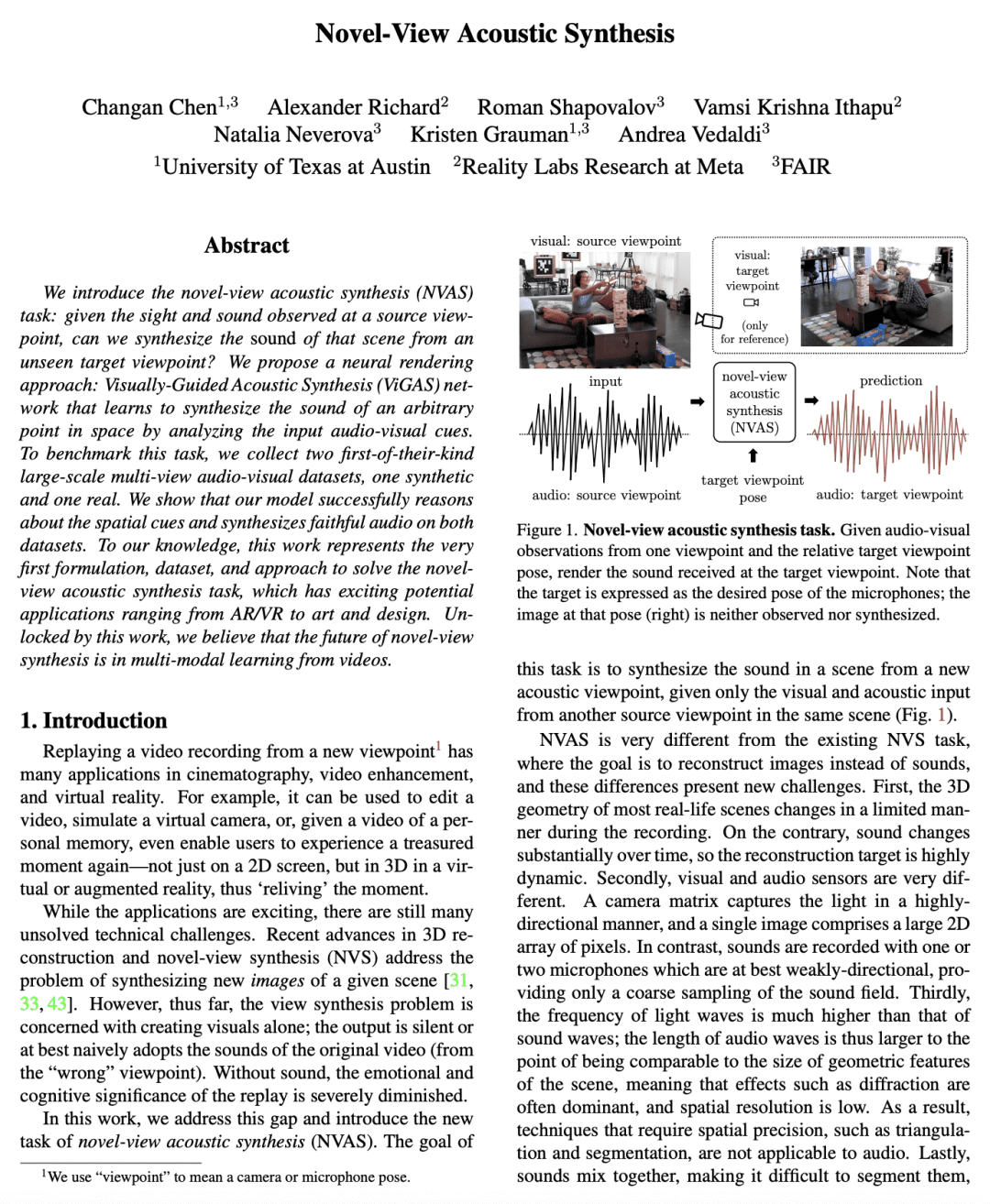

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢