
来自今天的爱可可AI前沿推介
[LG] Encoding Recurrence into Transformers
将循环编码到Transformer
要点:
-
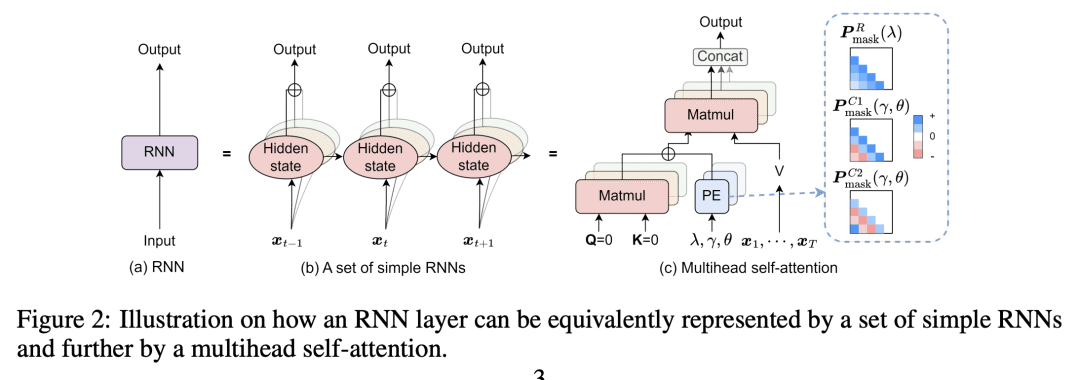
证明了线性激活 RNN 层等同于基于可忽略近似损失的多头自注意力(MHSA); -
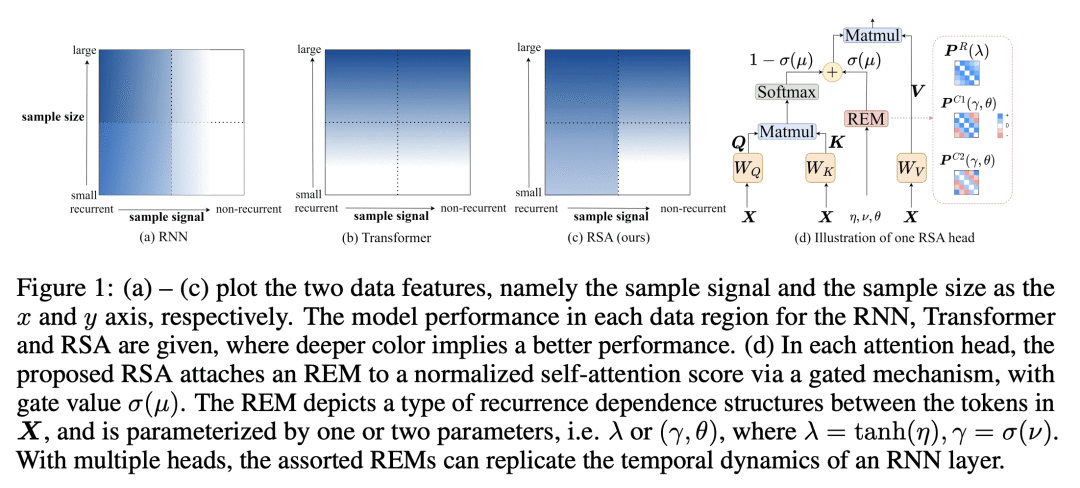
RNN 层的循环动态完全封装在位置编码中,称为循环编码矩阵(REM),使得将REM添加到任意现有基于自注意力机制的 Transformer 架构成为可能,从而形成循环自注意力(RSA)模块; -
在四个序列任务上的实验表明,所提出的 RSA 模块可以提高基线 Transformer 的采样效率,并得到明显改善的性能支持。
一句话总结:
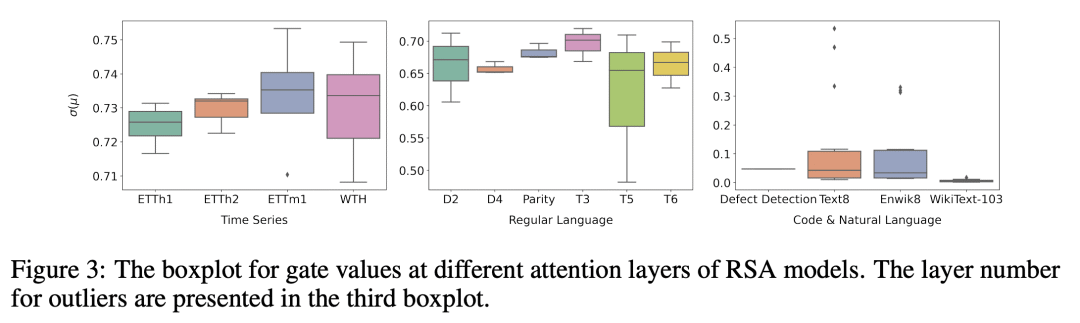
本文提出了一个名为循环自注意力(RSA)的新模块,使用循环编码矩阵(REM)和门控机制将 RNN 的循环动力学无缝集成到 Transformer 中,提高了序列任务的样本效率和性能,发现时间序列数据比常规语言具有更强的循环信号。
摘要:
本文以可忽略的损失将 RNN 层分解为一连串简单的 RNN,每个 RNN 都可以进一步改写为一个轻量的自注意力的位置编码矩阵,称为循环编码矩阵(REM)。由 RNN 层引入的循环动态可以被封装到多头自注意力的位置编码中,使得将这些循环动态无缝地纳入到 Transformer 中成为可能,从而形成一个新的模块——循环自注意力(RSA)模块。所提出的模块可以利用REM的循环归纳偏差,以达到比其相应的基线 Transformer 更好的采样效率,而自注意力则用于对其余的非循环信号进行建模。这两部分的相对比例由数据驱动的门控机制控制,四个连续学习任务上的实验证明了 RSA 模块的有效性。
This paper novelly breaks down with ignorable loss an RNN layer into a sequence of simple RNNs, each of which can be further rewritten into a lightweight positional encoding matrix of a self-attention, named the Recurrence Encoding Matrix (REM). Thus, recurrent dynamics introduced by the RNN layer can be encapsulated into the positional encodings of a multihead self-attention, and this makes it possible to seamlessly incorporate these recurrent dynamics into a Transformer, leading to a new module, Self-Attention with Recurrence (RSA). The proposed module can leverage the recurrent inductive bias of REMs to achieve a better sample efficiency than its corresponding baseline Transformer, while the self-attention is used to model the remaining non-recurrent signals. The relative proportions of these two components are controlled by a data-driven gated mechanism, and the effectiveness of RSA modules are demonstrated by four sequential learning tasks.
论文链接:https://openreview.net/forum?id=7YfHla7IxBJ
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢