
StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis
A Sauer, T Karras, S Laine, A Geiger, T Aila
[University of Tubingen & NVIDIA]
StyleGAN-T: 基于改进 GAN 的快速大规模文本到图像合成
要点:
-
所提出的模型 StyleGAN-T 解决了大规模文本到图像合成的具体要求,如大容量、在不同数据集上的稳定训练、强文本对齐和可控的变化与文本对齐的权衡; -
StyleGAN-T 在样本质量和速度方面比之前的 GAN 有明显的改进,超过了蒸馏扩散模型——在此之前快速文本到图像合成的最先进技术; -
GAN 在文本-图像合成方面比其他模型更快,因为只需要一个前向通道。
一句话总结:
提出的 StyleGAN-T 模型解决了大规模文本到图像合成的具体要求,在样本质量和速度方面优于之前的 GAN 和蒸馏扩散模型,GAN比其他模型的文本到图像合成速度更快。
摘要:
由于大型预训练语言模型、大规模训练数据以及可扩展模型族(如扩散模型和自回归模型)的引入,文本-图像合成最近取得了重大进展。然而,表现最好的模型,需要迭代评估以生成一个样本。相比之下,生成对抗网络(GAN)只需要一次前向传播。因此速度要快得多,但目前在大规模文本到图像合成方面仍然远落后于最先进的水平。本文旨在确定重新获得竞争力的必要步骤。所提出的模型 StyleGAN-T 解决了大规模文本-图像合成的具体要求,如大容量、在不同数据集上的稳定训练、强文本对齐和可控的变化与文本对齐的权衡。StyleGAN-T在样本质量和速度方面明显优于之前的 GAN,且优于蒸馏扩散模型——这是之前快速文本到图像合成的最先进技术。
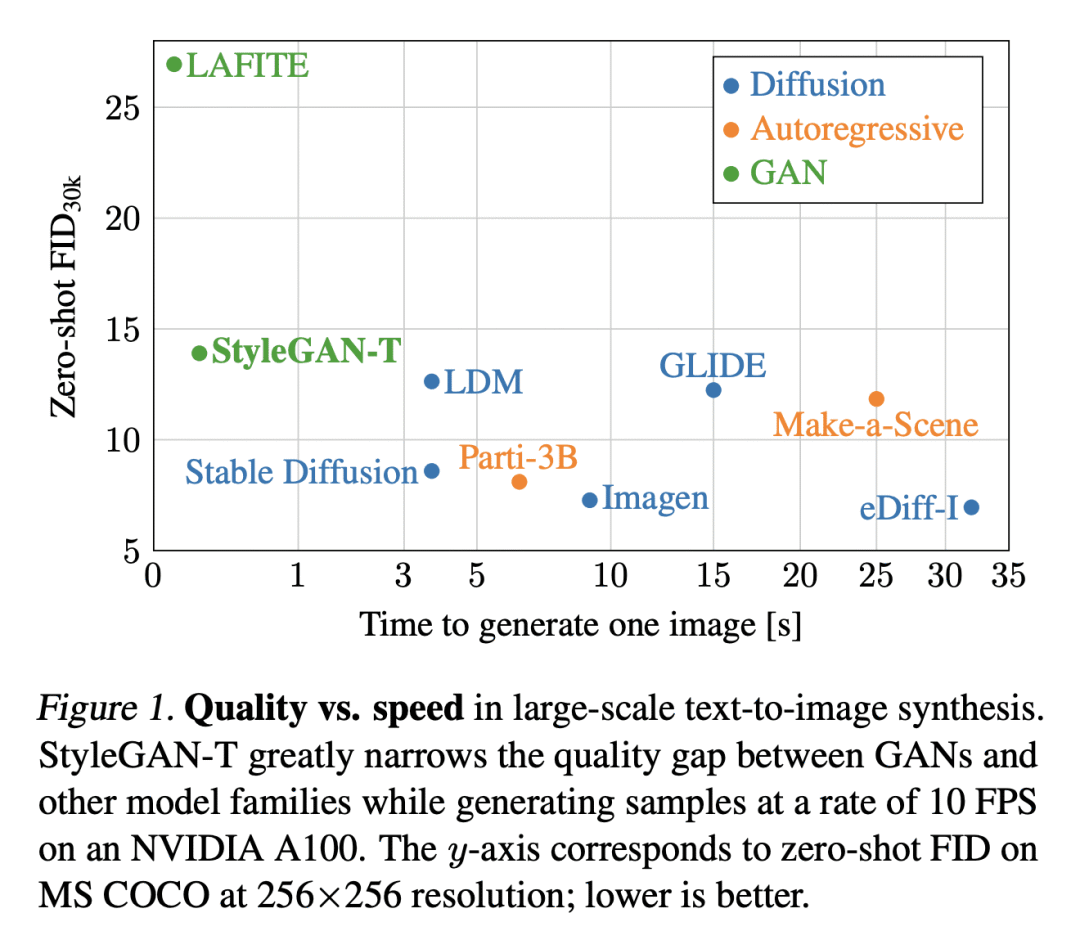
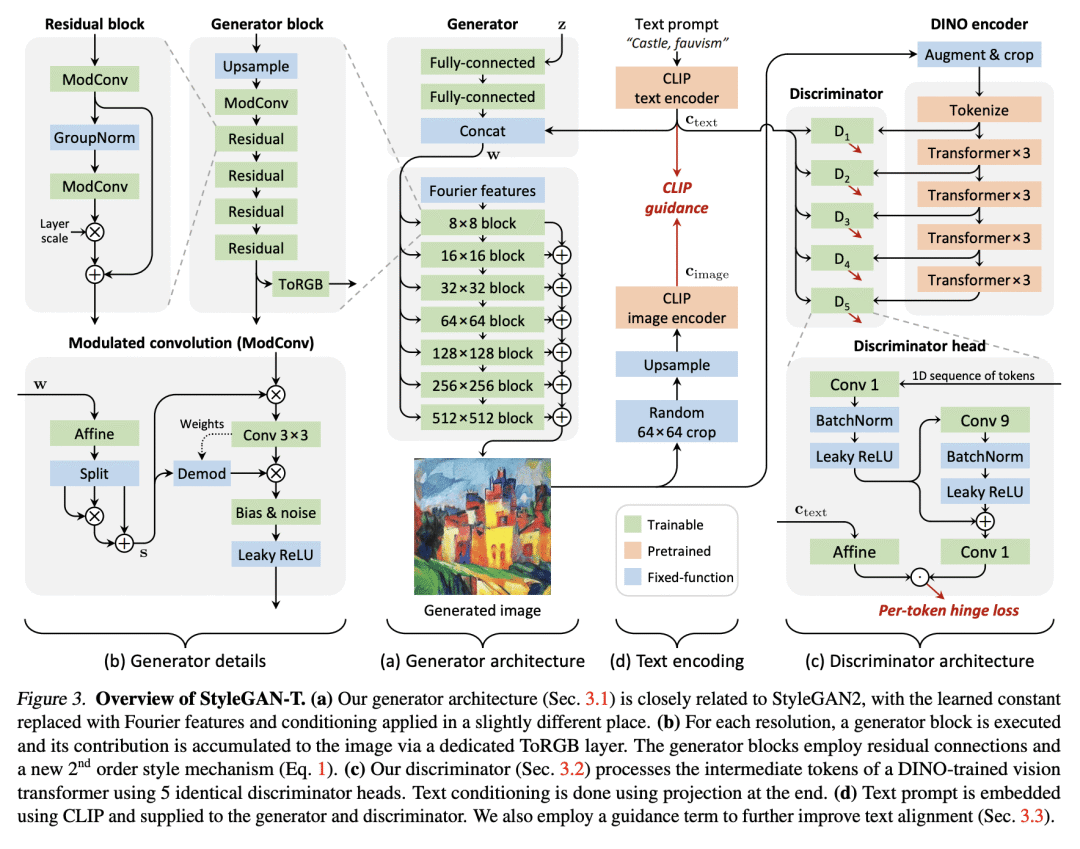
Text-to-image synthesis has recently seen significant progress thanks to large pretrained language models, large-scale training data, and the introduction of scalable model families such as diffusion and autoregressive models. However, the best-performing models require iterative evaluation to generate a single sample. In contrast, generative adversarial networks (GANs) only need a single forward pass. They are thus much faster, but they currently remain far behind the state-of-the-art in large-scale text-to-image synthesis. This paper aims to identify the necessary steps to regain competitiveness. Our proposed model, StyleGAN-T, addresses the specific requirements of large-scale text-to-image synthesis, such as large capacity, stable training on diverse datasets, strong text alignment, and controllable variation vs. text alignment tradeoff. StyleGAN-T significantly improves over previous GANs and outperforms distilled diffusion models - the previous state-of-the-art in fast text-to-image synthesis - in terms of sample quality and speed.
https://arxiv.org/abs/2301.09515

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢