
Zorro: the masked multimodal transformer
A Recasens, J Lin, J Carreira, D Jaegle, L Wang, J Alayrac, P Luc, A Miech, L Smaira, R Hemsley, A Zisserman
[DeepMind]
Zorro: 掩码多模态 Transformer
要点:
-
提出 Zorro,一种新的 Transformer 掩码配置,可以同时进行单模态和多模态的训练和推理,以及对比预训练;
-
提出了用ViT、SWIN和HiP等最先进模型的基于Zorro的架构;
-
Zorro 可以以自监督的方式,在大规模音频-视觉数据集上进行预训练,也可以在单模态数据集上进行预训练。
一句话总结:
提出一种用于多模态处理的新型 Transformer 掩码配置 Zorro,在基准上展示了最先进的性能,并可同时进行单模态和多模态训练和推理。
摘要:
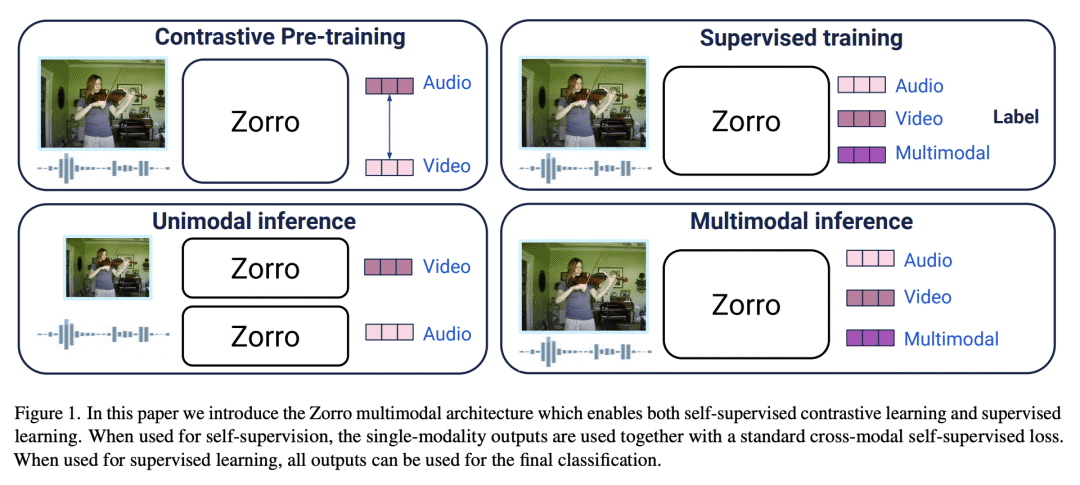
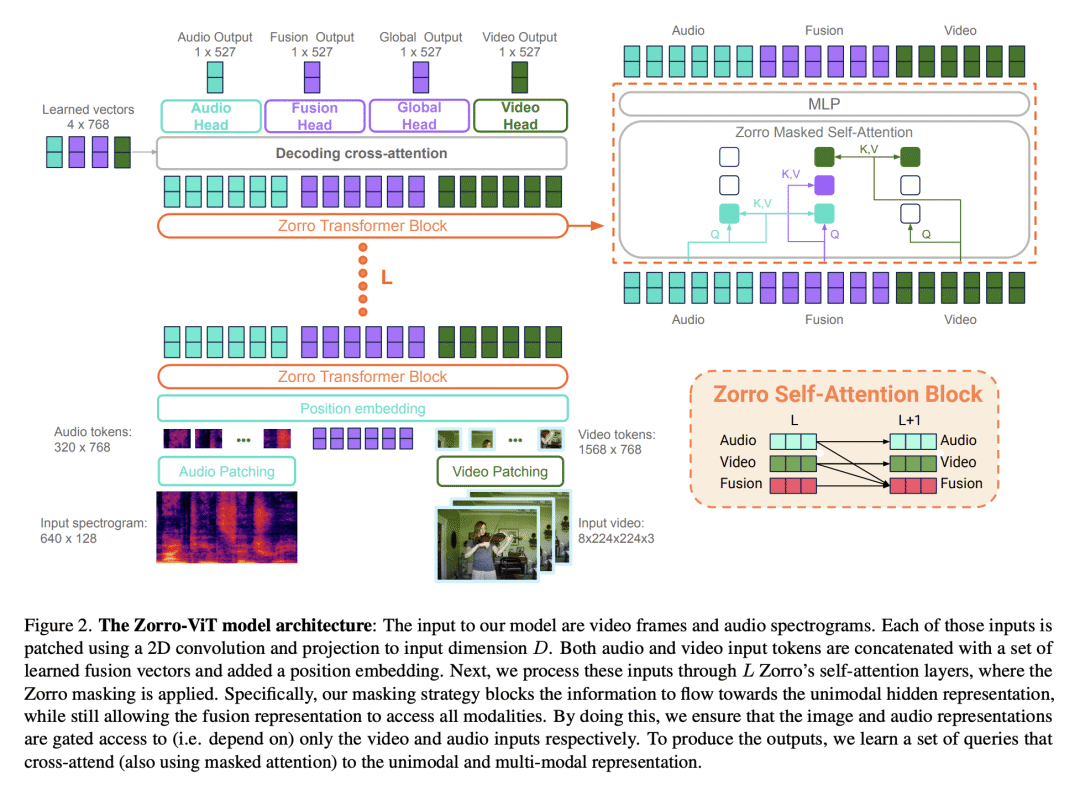
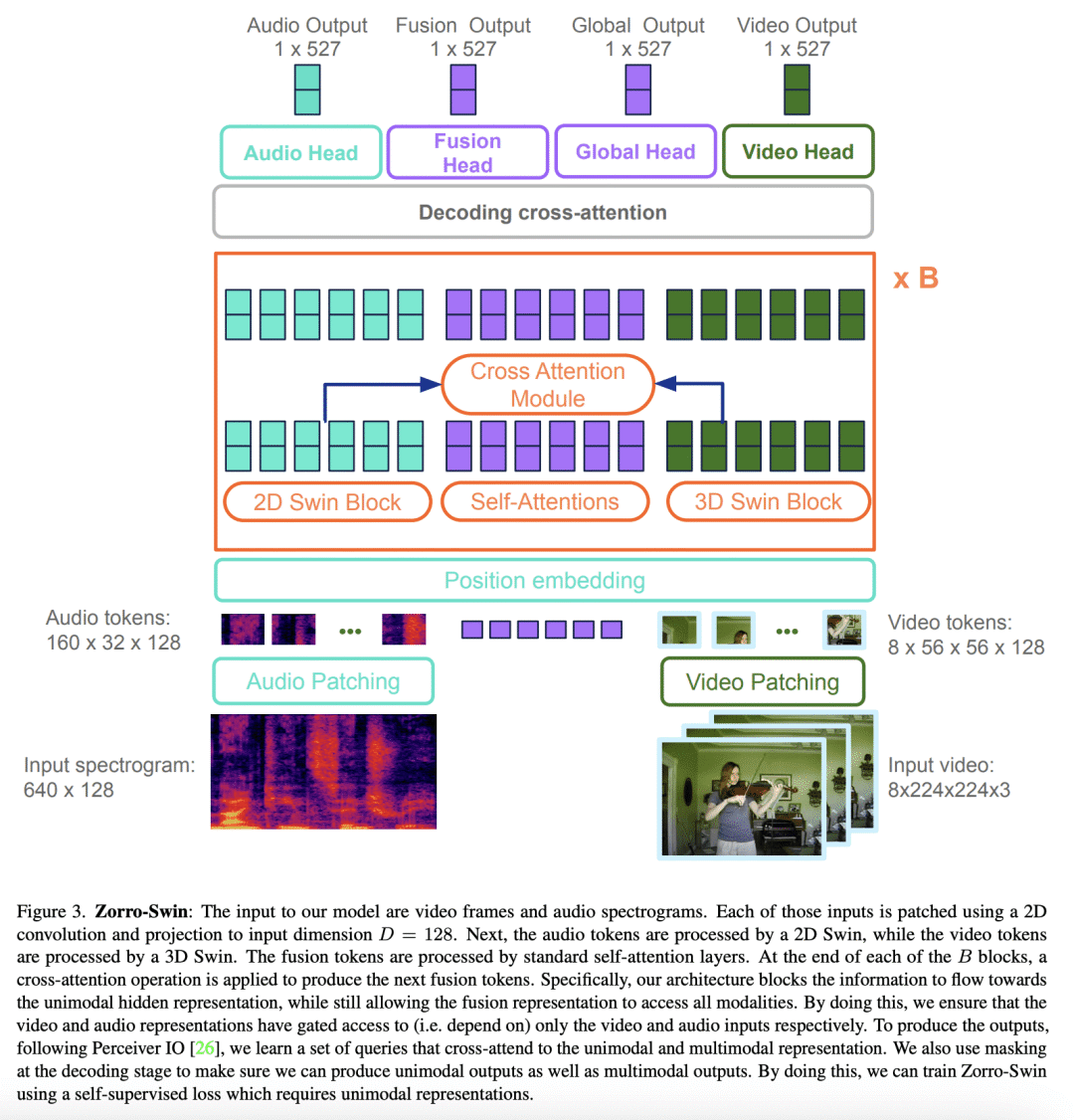
基于注意力的模型对多模态处理很有吸引力,因为来自多种模态的输入可以被串联起来,并输入到一个主干网络中——因此需要很少的融合工程。然而,所产生的表示在整个网络中是完全纠缠在一起的,可能并不总是可取的:在学习中,对比性的音频-视觉自监督学习,需要独立的音频和视觉特征来操作,否则学习会坍缩;在推理中,音频-视觉模型的评估应该可以在只有音频或只有视频的基准上进行。本文提出 Zorro,一种使用掩码来控制每种模态输入如何在 Transformer 内被路由的技术,以保持表示的某些部分是纯模态的。将这种技术应用于三种流行的基于 Transformer 的架构(ViT、Swin和HiP),并表明在对比性预训练下,Zorro在大多数相关的多模态任务(AudioSet和VGGSound)的基准上取得了最先进的结果。此外,所得到的模型能在视频和音频基准上进行单模态推理,如Kinetics-400或ESC-50。
Attention-based models are appealing for multimodal processing because inputs from multiple modalities can be concatenated and fed to a single backbone network - thus requiring very little fusion engineering. The resulting representations are however fully entangled throughout the network, which may not always be desirable: in learning, contrastive audio-visual self-supervised learning requires independent audio and visual features to operate, otherwise learning collapses; in inference, evaluation of audio-visual models should be possible on benchmarks having just audio or just video. In this paper, we introduce Zorro, a technique that uses masks to control how inputs from each modality are routed inside Transformers, keeping some parts of the representation modality-pure. We apply this technique to three popular transformer-based architectures (ViT, Swin and HiP) and show that with contrastive pre-training Zorro achieves state-of-the-art results on most relevant benchmarks for multimodal tasks (AudioSet and VGGSound). Furthermore, the resulting models are able to perform unimodal inference on both video and audio benchmarks such as Kinetics-400 or ESC-50.
https://arxiv.org/abs/2301.09595
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢