
来自爱可可的前沿推介
Diffusion Models for Causal Discovery via Topological Ordering
P Sanchez, X Liu, A Q O'Neil, S A. Tsaftaris
[The University of Edinburgh & Canon Medical Research Europe]
基于扩散模型的拓扑排序因果发现
要点:
-
提出 DiffAN,一种因果发现算法,利用扩散概率模型(DPM)进行拓扑排序;
-
用对数似然 Hessian 方差识别因果图叶节点,用于更普遍的噪声分布族;
-
提出一种高效的拓扑排序算法,不依赖于每次摘叶迭代后的重训练得分。
一句话总结:
提出 DiffAN,一种因果发现算法,使用扩散概率模型(DPM),通过识别 Hessian 对角线元素,在数据样本间方差为零的情况下找到因果图叶节点,实现高效的拓扑排序,可扩展到高维图和大数据集。
论文地址:https://arxiv.org/abs/2210.06201
摘要:
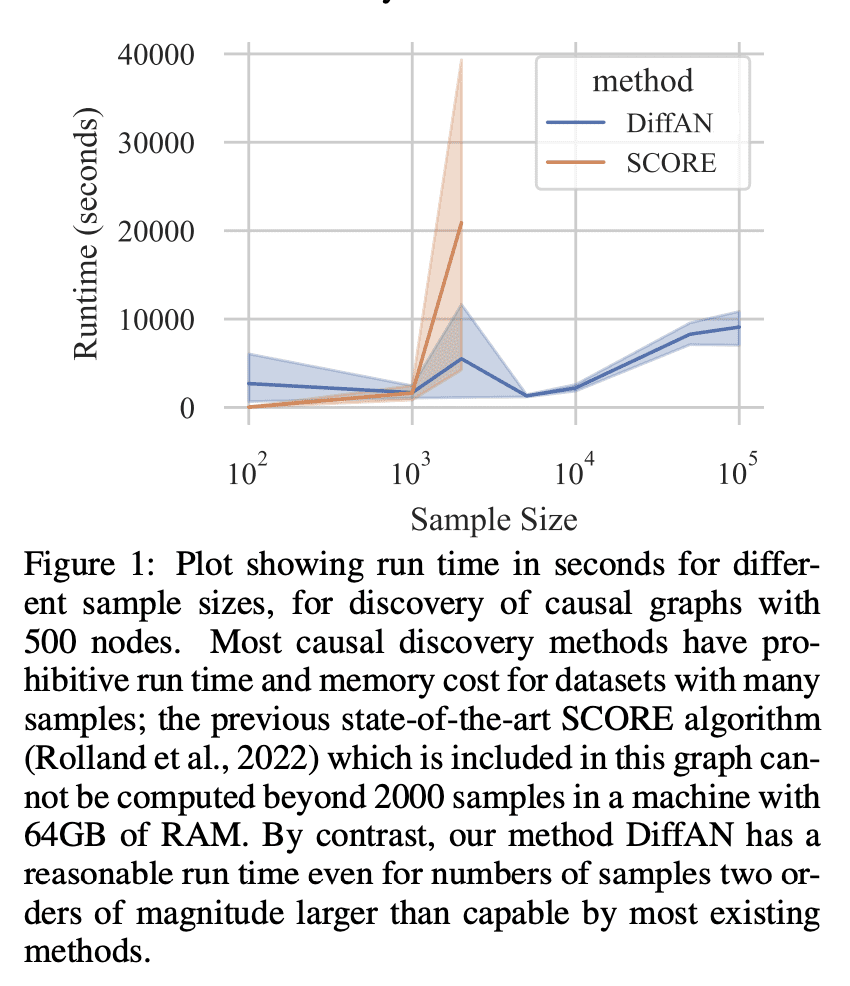
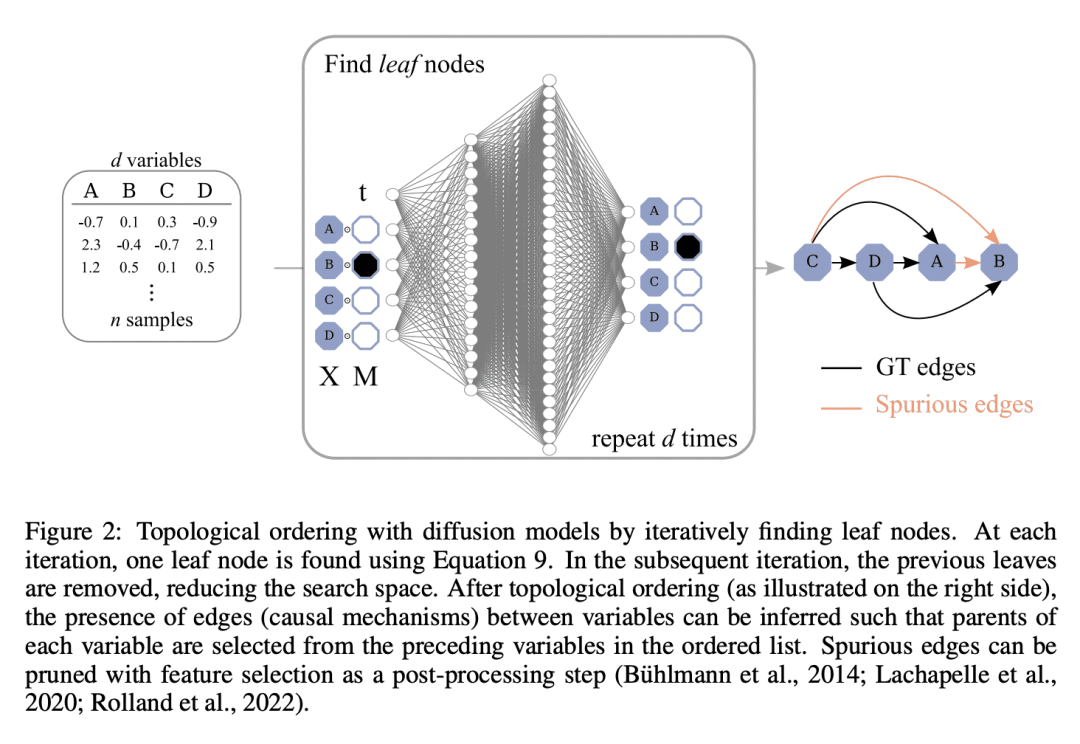
从观察数据中发现因果关系,在附加假设下成为可能,例如将函数关系视为带有加性噪声的非线性约束。这种情况下,数据对数似然的 Hessian 可以用来寻找因果图中的叶节点。因果发现的拓扑排序方法利用了这一点,分两步进行图的发现,首先按深度的倒序识别节点(拓扑排序),其次是修剪潜在关系。这样做更有效率,因为搜索是在一个排列组合而不是一个图空间上进行的。然而,现有的获取 Hessian 的计算方法仍然不能随着变量数量和样本数量的增加而扩展。因此,受最近扩散概率模型(DPM)的创新启发,本文提出 DiffAN,利用 DPM 的拓扑排序算法。本文提出了在不重新训练神经网络的情况下更新所学 Hessian 的理论,本文表明,用一个样本子集进行计算可以得到一个准确的排序近似值,允许扩展到具有更多样本和变量的数据集。经验表明,所提出方法可以很好地扩展到有500个节点和105个样本的数据集,同时在小数据集上的表现仍与最先进的因果发现方法相当。
Discovering causal relations from observational data becomes possible with additional assumptions such as considering the functional relations to be constrained as nonlinear with additive noise. In this case, the Hessian of the data log-likelihood can be used for finding leaf nodes in a causal graph. Topological ordering approaches for causal discovery exploit this by performing graph discovery in two steps, first sequentially identifying nodes in reverse order of depth (topological ordering), and secondly pruning the potential relations. This is more efficient since the search is performed over a permutation rather than a graph space. However, existing computational methods for obtaining the Hessian still do not scale as the number of variables and the number of samples are increased. Therefore, inspired by recent innovations in diffusion probabilistic models (DPMs), we propose DiffAN, a topological ordering algorithm that leverages DPMs. Further, we introduce theory for updating the learned Hessian without re-training the neural network, and we show that computing with a subset of samples gives an accurate approximation of the ordering, which allows scaling to datasets with more samples and variables. We show empirically that our method scales exceptionally well to datasets with up to 500 nodes and up to 105 samples while still performing on par over small datasets with state-of-the-art causal discovery methods.

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢