
来自今天的爱可可AI前沿推介
[LG] A Watermark for Large Language Models
J Kirchenbauer, J Geiping, Y Wen, J Katz, I Miers, T Goldstein
[University of Maryland]
大型语言模型的水印
要点:
-
提出一种用于专有语言模型的水印框架,将信号嵌入到生成的文本中,这些信号对人来说是不可见的,但通过算法可从短跨度的 token 中检测出来; -
提出一种高效的开源算法,用于检测水印,无需了解模型参数或访问语言模型API; -
提出检测水印的统计测试,并提供可解释的P值,以及分析水印敏感性的信息论框架。
一句话总结:
提出一个大型语言模型的水印框架,将信号嵌入生成的文本中,无需访问模型参数或 API 即可通过算法进行检测,可以在不重新训练的情况下改装到任何现有的模型中,对文本质量的影响可以忽略不计,还可以通过可解释的P值进行检测的统计测试。
摘要:
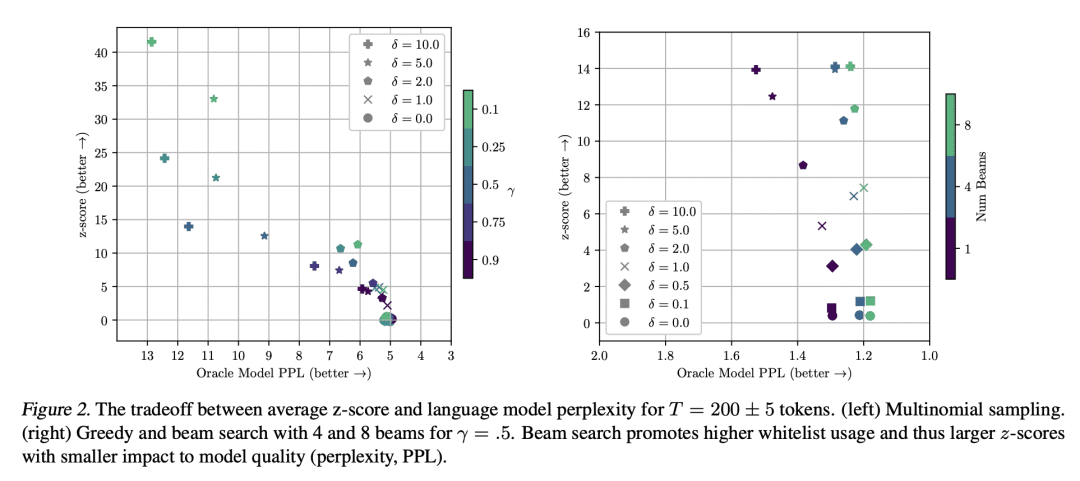
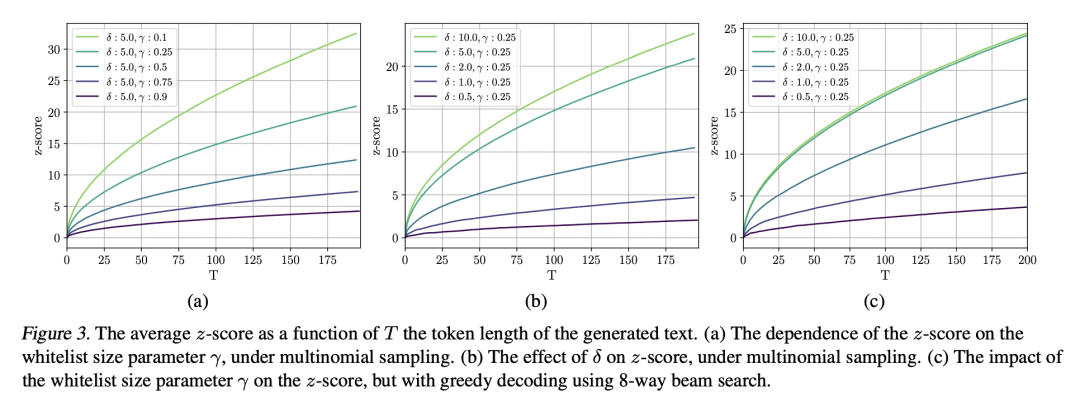
大型语言模型的潜在危害,可通过给模型输出加水印来缓解,也就是把信号嵌入到生成的文本中,这些信号对人来说是不可见的,但从短跨度的 token 中可以通过算法检测出来。本文提出一种专有语言模型的水印框架。水印的嵌入对文本质量的影响可以忽略不计,可以使用高效的开源算法进行检测,而无需访问语言模型的 API 或参数。水印的工作原理是在一个词生成之前选择一组随机的白名单 token,然后在采样过程中软性地促进白名单 token 的使用。提出一个具有可解释 p 值的检测水印的统计测试,并推导出一个分析水印敏感性的信息论框架。用开放预训练 Transformer(OPT)族的数十亿参数模型测试水印,并讨论了鲁棒性和安全性。
Potential harms of large language models can be mitigated by watermarking model output, i.e., embedding signals into generated text that are invisible to humans but algorithmically detectable from a short span of tokens. We propose a watermarking framework for proprietary language models. The watermark can be embedded with negligible impact on text quality, and can be detected using an efficient open-source algorithm without access to the language model API or parameters. The watermark works by selecting a randomized set of whitelist tokens before a word is generated, and then softly promoting use of whitelist tokens during sampling. We propose a statistical test for detecting the watermark with interpretable p-values, and derive an information-theoretic framework for analyzing the sensitivity of the watermark. We test the watermark using a multi-billion parameter model from the Open Pretrained Transformer (OPT) family, and discuss robustness and security.
论文链接:https://arxiv.org/abs/2301.10226

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢