

论文地址:https://arxiv.org/abs/2203.08777
导读
自监督学习(SSL)旨在利用大量无标签数据来解决复杂任务。虽然在简单的、图像级的学习方面已经取得了很好的进展,但最近的方法显示了包括图像结构知识的优势。然而,通过引入手工标注的图像分割来定义感兴趣区域,或专门的增强策略,这些方法牺牲了使SSL如此强大的简单性和通用性。本文提出一种自监督学习范式,可以自己发现这些先验编码的结构。所提出的方法Odin,结合了目标发现和表示网络,在没有任何监督的情况下发现有意义的图像分割。由此产生的学习范式更简单,更鲁棒,更通用,并在COCO上的目标检测和实例分割以及PASCAL和Cityscapes上的语义分割中取得了最先进的迁移学习结果,同时在DAVIS上的视频分割中强烈超越了有监督预训练。
方法
以往的自我监督学习(SSL)方法能够很好地描述整个大的场景,但是很难区分出单个的物体。
现在,Odin方法做到了,并且是在没有任何监督的情况下做到的。
能够很好地区分出图像中的各个物体,主要归功于Odin学习框架的“自我循环”。
Odin学习了两组协同工作的网络,分别是目标发现网络和目标表示网络。
目标发现网络以图像的一个裁剪部分作为输入,裁剪的部分应该包含图像的大部分区域,且这部分图像并没有在其他方面进行增强处理。
然后对输入图像生成的特征图进行聚类分析,根据不同的特征对图像中各个物体的进行分割。
目标表示网络的输入视图是目标发现网络中所生成的分割图像。
视图输入之后,对它们分别进行随机预处理,包括翻转、模糊和点级颜色转换等。
这样就能够获得两组掩模,它们除了剪裁之外的差异,其他信息都和底层图像内容相同。
而后两个掩模会通过对比损失,进而学习能够更好地表示图像中物体的特征。
具体来说,就是通过对比检测,训练一个网络来识别不同目标物体的特征,同时还有许多来自其他不相干物体的“负面”特征。
然后,最大化不同掩模中同一目标物体的相似性,最小化不同目标物体之间的相似性,进而更好地进行分割以区别不同目标物体。
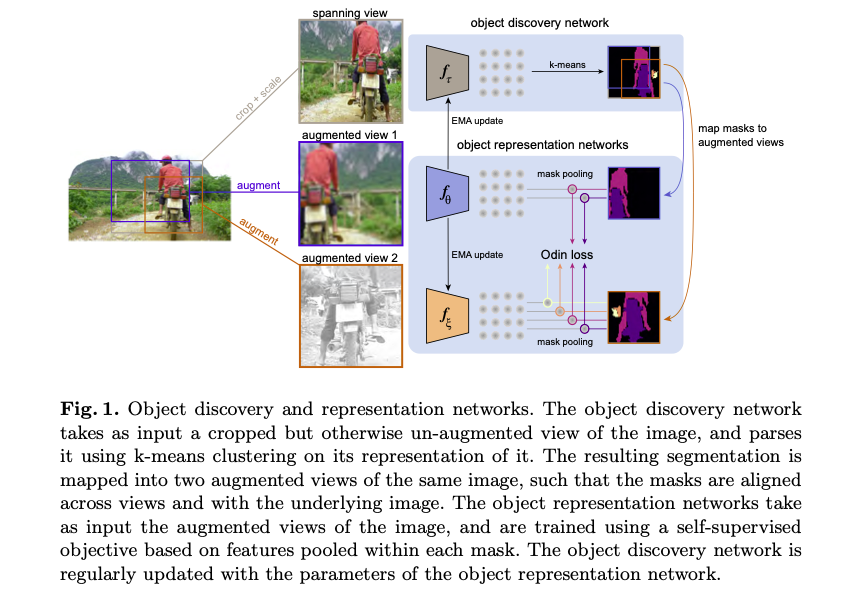
与此同时,目标发现网络会定期根据目标表示网络的参数进行相应的更新。
最终的目的是确保这些对象级的特性在不同的视图中大致不变,换句话说就是将图像中的物体分隔开来。
实验
Odin方法在场景分割时,没有先验知识的情况下迁移学习的性能也很强大。
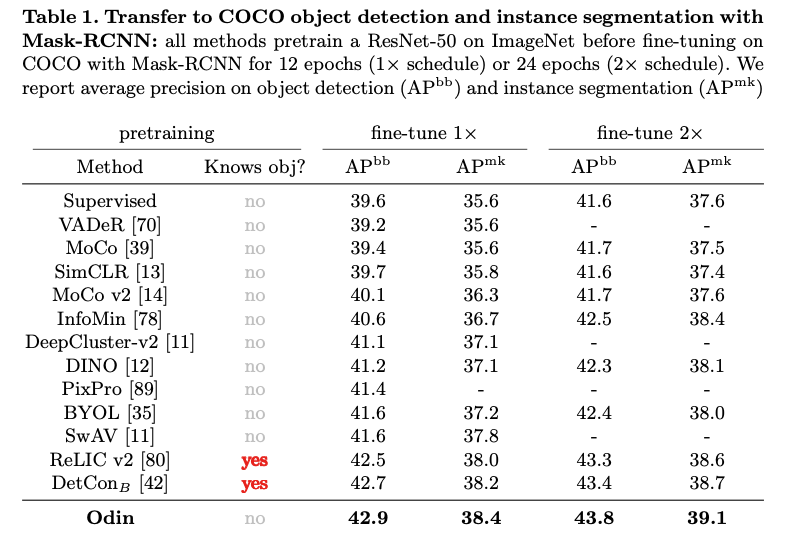
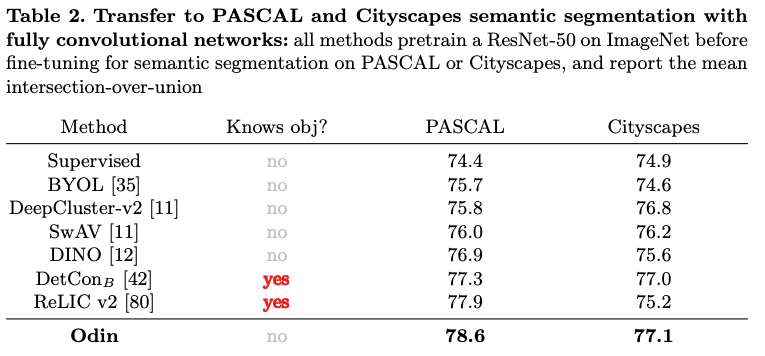
首先,使用Odin方法在ImageNet数据集上进行预训练,然后评估其在COCO数据集以及PASCAL和Cityscapes语义分割上的效果。
已经知道目标物体,即获得先验知识的方法在进行场景分割时,效果要明显好于其他未获得先验知识的方法。
而Odin方法即使未获得先验知识,其效果也要优于获得先验知识的DetCon和ReLICv2。
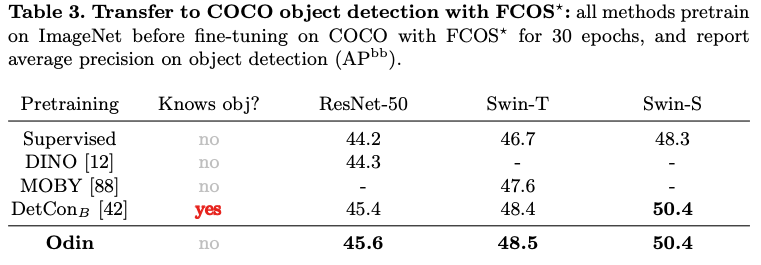
除此之外,Odin方法不仅可以应用在ResNet模型中,还可以应用到更复杂的模型中,如Swim Transformer。
在数据上,Odin框架学习的优势很明显,那在可视化的图像中,Odin的优势在何处体现了呢?
将使用Odin生成的分割图像与随机初始化的网络(第3列),ImageNet监督的网络(第4列)中获得的分割图像进行比较。
第3、4列都未能清晰地描绘出物体的边界,或者缺乏现实世界物体的一致性和局部性,而Odin生成的图像效果很明显要更好一些。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢