
文本到4D动态场景生成,来自爱可可的前沿推介
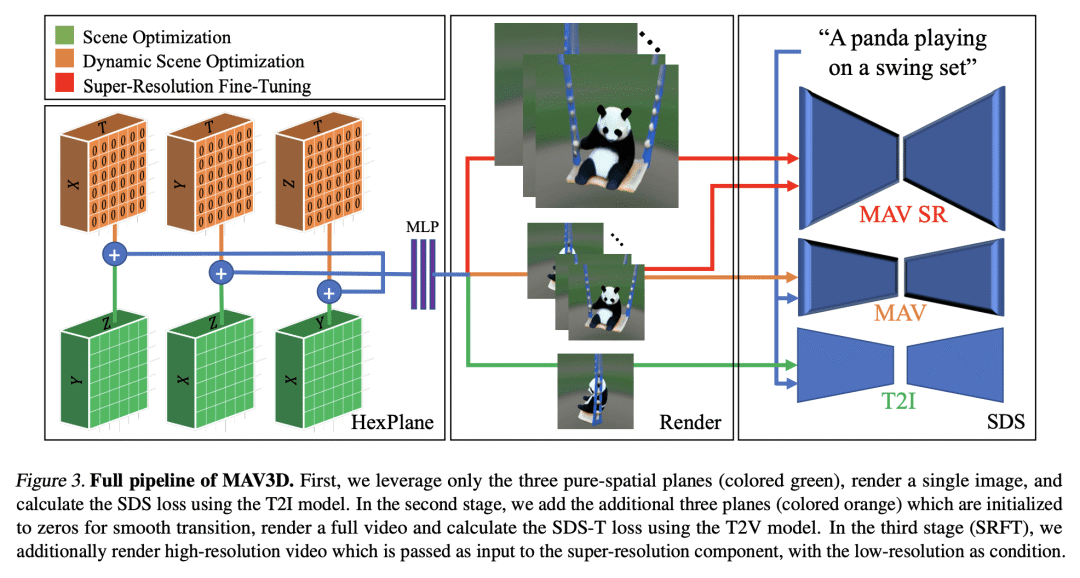
提出MAV3D,一种有效方法,利用 4D 动态神经辐射场和基于文本到视频的扩散模型,从文本描述中生成 3D 动态场景,采用多阶段静态到动态的优化方案,通过实验证明,它是第一个不需要3D或4D数据生成4D场景的方法。
Text-To-4D Dynamic Scene Generation
U Singer, S Sheynin, A Polyak, O Ashual, I Makarov, F Kokkinos, N Goyal, A Vedaldi, D Parikh, J Johnson, Y Taigman
要点:
-
提出MAV3D,一种利用 4D 动态神经辐射场(NeRF)和基于文本到视频(T2V)扩散模型,从文本描述中生成 3D 动态场景的有效方法; -
提出一个多阶段的从静态到动态的优化方案,逐步纳入静态、时间和超分辨率模型的梯度信息,以增强 4D 场景表示; -
通过全面的定量和定性实验证明了该方法的有效性,比之前建立的内部基线有所改进。
论文地址:https://arxiv.org/abs/2301.11280
摘要:
本文提出了MAV3D(Make-A-Video3D),一种从文本描述生成 3D 动态场景的方法,用 4D 动态神经辐射场(NeRF),通过查询基于文本到视频(T2V)的扩散模型,对场景外观、密度和运动一致性进行优化。从提供的文本中产生的动态视频输出,可以从任意相机位置和角度观看,并可以合成到任意 3D 环境中。MAV3D不需要任何 3D 或 4D 数据,T2V模型仅在文本-图像对和未标记视频上训练。用全面的定量和定性实验证明了该方法的有效性,并显示出比之前建立的内部基线有改进。
We present MAV3D (Make-A-Video3D), a method for generating three-dimensional dynamic scenes from text descriptions. Our approach uses a 4D dynamic Neural Radiance Field (NeRF), which is optimized for scene appearance, density, and motion consistency by querying a Text-to-Video (T2V) diffusion-based model. The dynamic video output generated from the provided text can be viewed from any camera location and angle, and can be composited into any 3D environment. MAV3D does not require any 3D or 4D data and the T2V model is trained only on Text-Image pairs and unlabeled videos. We demonstrate the effectiveness of our approach using comprehensive quantitative and qualitative experiments and show an improvement over previously established internal baselines. To the best of our knowledge, our method is the first to generate 3D dynamic scenes given a text description.


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢