
比较专门针对不同群体训练多个 ML 模型与为所有数据训练一个独特模型的有效性。
我最近听到一家公司宣称:“我们在生产中有60个流失模型。”(注:流失模型是一种通过数学来建模流失对业务的影响。)我问他们为什么这么多。他们回答说,他们拥有 5 个品牌,在 12 个国家/地区运营,并且由于他们想为每个品牌和国家/地区的组合开发一种模型,因此共计 60 种模型。于是,我问他们:“你试过只用一种模型吗?”
他们认为这没有意义,因为他们的品牌彼此之间非常不同,他们经营的目标国家也是如此:“你不能训练一个单一的模型并期望它对品牌 A 的美国客户和对品牌 B 的德国客户”。
由于在业内经常听到这样的说法,我很好奇这个论点是否反映在数据中,或者只是没有事实支持的猜测。
这就是为什么在本文中,我将系统地比较两种方法:
-
将所有数据提供给一个模型,也就是一个通用模型(general model);
-
为每个细分市场构建一个模型(在前面的示例中,品牌和国家/地区的组合),也就是许多专业模型(specialized models)。
我将在流行的Python库Pycaret提供的12个真实数据集上测试这两种策略。
通用模型与专用模型
这两种方法究竟是如何工作的?
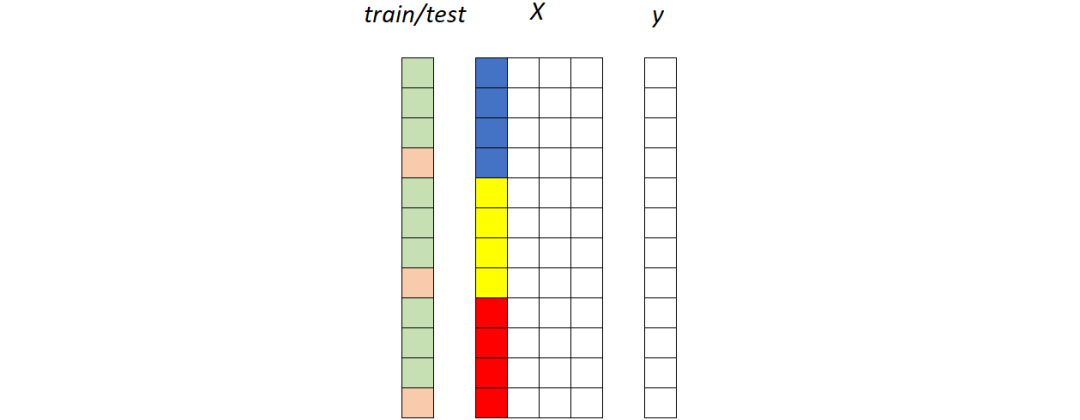
假设我们有一个数据集。数据集由预测变量矩阵(称为X)和目标变量(称为y)组成。此外,X包含一个或多个可用于分割数据集的列(在前面的示例中,这些列是“品牌”和“国家/地区”)。
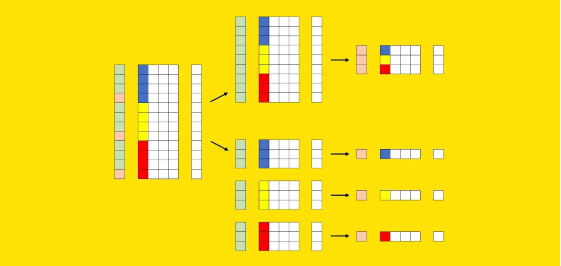
现在让我们尝试以图形方式表示这些元素。我们可以使用X的其中一列来可视化这些段:每种颜色(蓝色、黄色和红色)标识不同的段。我们还需要一个额外的向量来表示训练集(绿色)和测试集(粉色)的划分。
鉴于这些要素,以下是这两种方法的不同之处。
第一种策略:通用模型
在整个训练集上拟合一个独特的模型,然后在整个测试集上测量其性能:
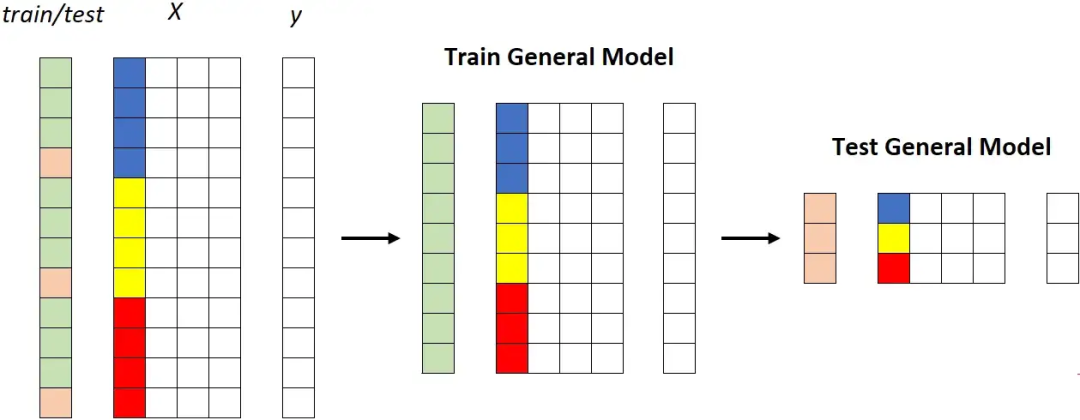
通用模型。所有片段(蓝色、黄色和红色)都被馈送到同一个模型。图源作者
第二个策略:专业模型
第二种策略涉及为每个段建立模型,这意味着重复训练/测试过程k次(其中k是片段数,在本例中为 3)。
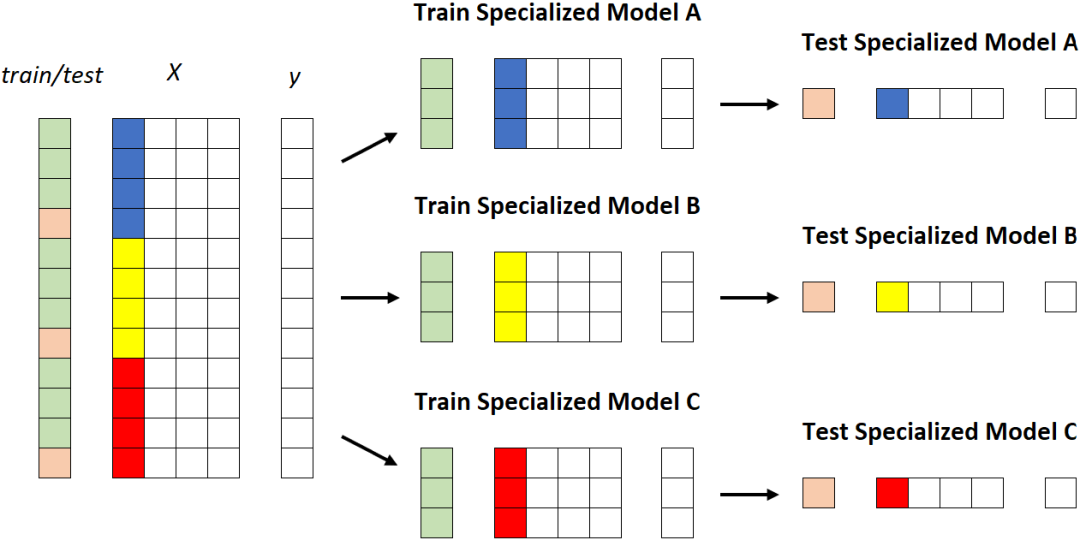
 专用模型。每个段被馈送到不同的模型。[作者图片]
专用模型。每个段被馈送到不同的模型。[作者图片]
请注意,在实际用例中,分段的数量可能是相关的,从几十个到数百个不等。因此,与使用一个通用模型相比,使用专用模型存在几个实际缺点,例如:
-
更高的维护工作量;
-
更高的系统复杂度;
-
更高的(累积的)培训时间;
-
更高的计算成本:
-
更高的存储成本。
那么,为什么会有人想要这样做呢?
对通用模型的偏见
专用模型的支持者声称,独特的通用模型在给定的细分市场(比如美国客户)上可能不太精确,因为它还了解了不同细分市场(例如欧洲客户)的特征。
我认为这是因使用简单模型(例如逻辑回归)而产生的错误认识。让我用一个例子来解释。
假设我们有一个汽车数据集,由三列组成:
-
汽车类型(经典或现代);
-
汽车时代;
-
车价。
我们想使用前两个特征来预测汽车价格。这些是数据点:
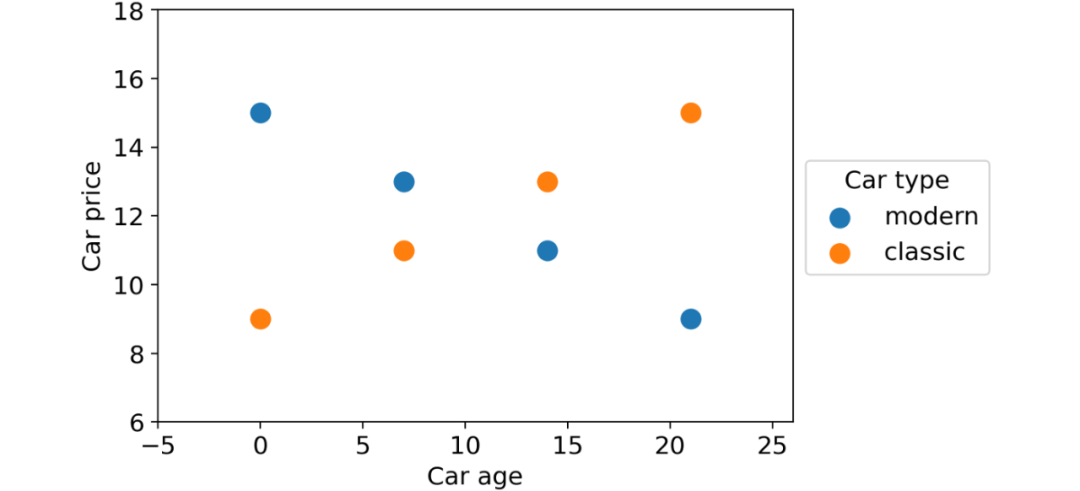
具有两个部分(经典汽车和现代汽车)的数据集,显示出与目标变量相关的非常不同的行为。图源作者
如您所见,根据汽车类型,有两种完全不同的行为:随着时间的推移,现代汽车贬值,而老爷车价格上涨。
现在,如果我们在完整数据集上训练线性回归:
linear_regression = LinearRegression().fit(df[[ "car_type_classic" , "car_age" ]], df[ "car_price" ])得到的系数是:
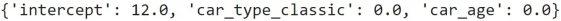
这意味着模型将始终为任何输入预测相同的值12。
通常,如果数据集包含不同的行为(除非您进行额外的特征工程),简单模型将无法正常工作。因此,在这种情况下,人们可能会想训练两种专门的模型:一种用于经典汽车,一种用于现代汽车。
但是让我们看看如果我们使用决策树而不是线性回归会发生什么。为了使比较公平,我们将生成一棵有3个分支的树(即3个决策阈值),因为线性回归也有3个参数(3个系数)。
decision_tree = DecisionTreeRegressor(max_depth= 2 ).fit(df[[ "car_type_classic" , "car_age" ]], df[ "car_price" ])
这是结果:
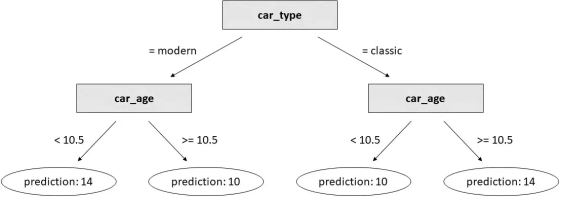
这比我们用线性回归得到的结果要好得多!
关键是基于树的模型(例如 XGBoost、LightGBM 或 Catboost)能够处理不同的行为,因为它们天生就可以很好地处理特征交互。
这就是为什么在理论上没有理由比一个通用模型更喜欢几个专用模型的主要原因。但是,一如既往,我们并不满足于理论解释。我们还想确保这一猜想得到真实数据的支持。
实验细节
在本段中,我们将看到测试哪种策略效果更好所需的 Python 代码。如果您对细节不感兴趣,可以直接跳到下一段,我将在这里讨论结果。
我们的目标是定量比较两种策略:
-
训练一个通用模型;
-
训练许多个专用模型。
比较它们的最明显方法如下:
1. 获取数据集;
2. 根据一列的值选择数据集的一部分;
3. 将数据集拆分为训练数据集和测试数据集;
4. 在整个训练数据集上训练通用模型;
5. 在属于该段的训练数据集部分上训练专用模型;
6. 比较通用模型和专用模型在属于该段的测试数据集部分上的性能。
图形化:
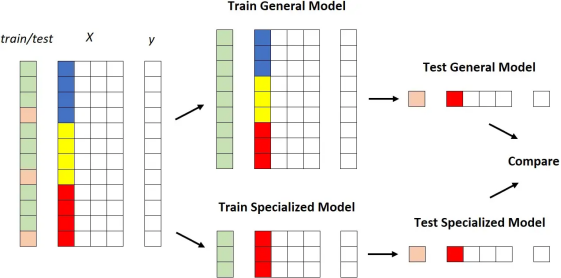
这工作得很好,但是,由于我们不想被随机性愚弄,我们将重复这个过程:
-
对于不同的数据集;
-
使用不同的列来分割数据集本身;
-
使用同一列的不同值来定义段。
换句话说,这就是我们要用伪代码做的:
for each dataset:train general model on the training setfor each column of the dataset:for each value of the column:train specialized model on the portion of the training set for which column = valuecompare performance of general model vs. specialized model
实际上,我们需要对这个过程做一些微小的调整。
首先,我们说过我们正在使用数据集的列来分割数据集本身。这适用于分类列和具有很少值的离散数字列。对于剩余的数字列,我们必须通过分箱(binning)使它们分类。
其次,我们不能简单地使用所有的列。如果我们这样做,我们将会惩罚专用模型。事实上,如果我们根据与目标变量无关的列选择细分,就没有理由相信专门的模型可以表现得更好。为避免这种情况,我们将只使用与目标变量有某种关系的列。
此外,出于类似的原因,我们不会使用所有细分列的值。我们将避免过于频繁(超过50%)的值,因为期望在大多数数据集上训练的模型与在完整数据集上训练的模型具有不同的性能是没有意义的。我们还将避免测试集中少于100个案例的值,因为结果肯定不会很重要。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢