
Sparsity May Cry: Let Us Fail (Current) Sparse Neural Networks Together!
本文提出一个新基准 SMC-Bench,以评估神经网络中稀疏算法的有效性,发现目前最先进的方法在其上的表现不尽如人意,强调了该领域需要更具挑战性的基准和研究。
Sparsity May Cry: 用于评估稀疏神经网络的SMC-Bench基准
论文地址:https://openreview.net/forum?id=J6F3lLg4Kdp
要点:
-
提出"Sparsity May Cry”基准(SMC-Bench),包含一组精心策划的任务和数据集,旨在评估稀疏算法的有效性,并捕获广泛的领域特定知识;
-
观察到目前最先进的(SOTA)稀疏算法在 SMC-Bench 上的表现都很差,即使是稀疏度低至5%的情况下;
-
发现需要更多困难和多样化的基准来探索稀疏神经网络的局限性,并促进下一代算法的发展,这些算法有可能在复杂和实际的任务中得到推广。
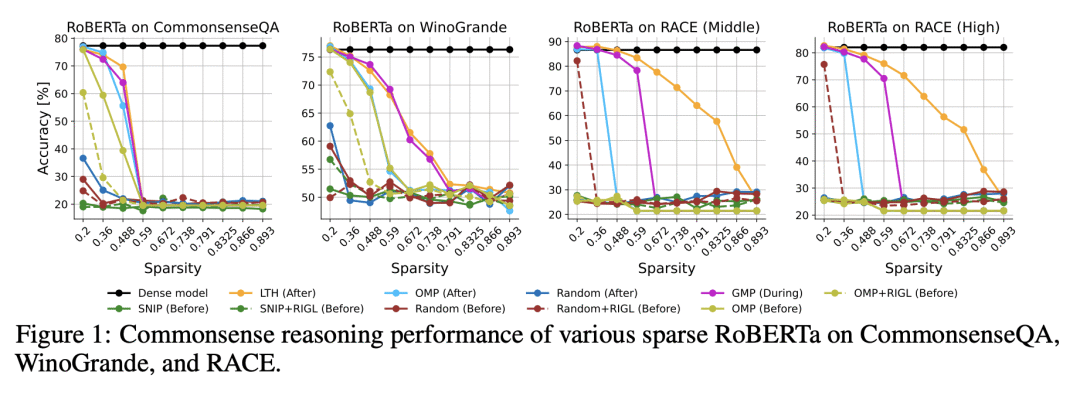
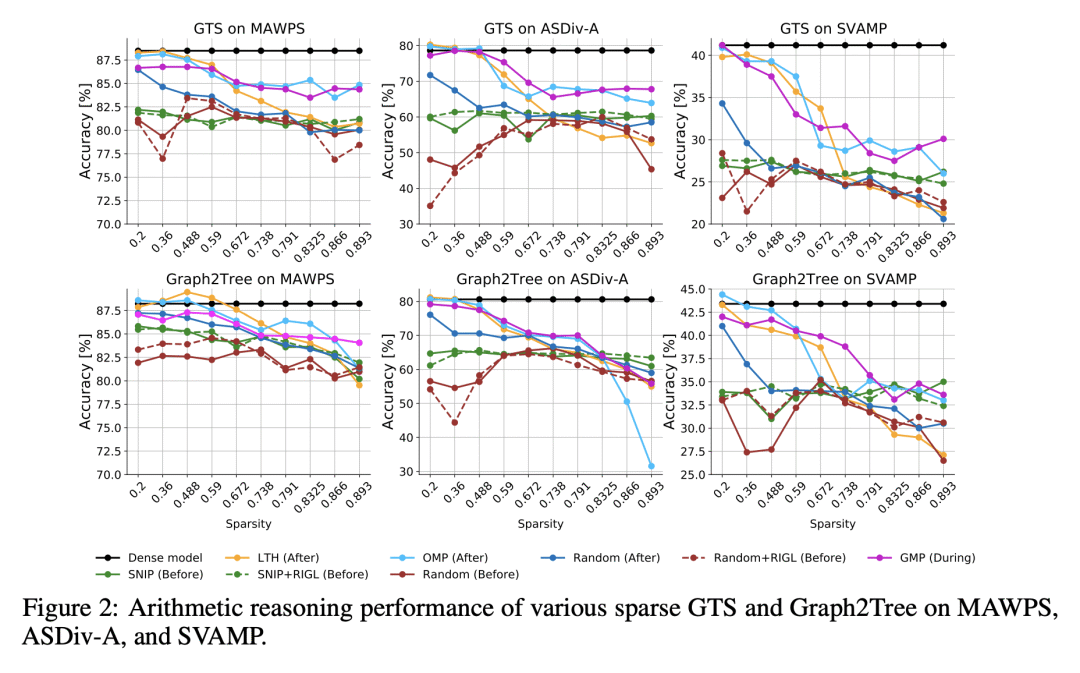
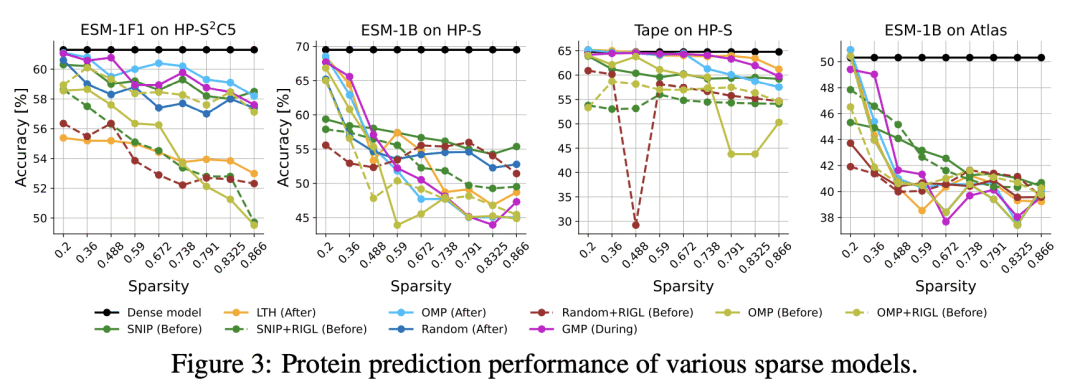
稀疏神经网络(SNN)受到了大量的关注,主要是由于大规模模型中不断爆炸的参数数量,带来了越来越多的计算和内存(碳)足迹。与密集型网络类似,最近的稀疏神经网络也有很好的泛化能力,并具有许多有利的优势(如低复杂性、高可扩展性和鲁棒性),有时甚至比原来的密集型网络更好。随着研究工作集中在开发越来越复杂的稀疏算法上,令人吃惊的是,评估这些算法有效性的综合基准被高度忽视了。在缺乏精心设计的评估基准的情况下,大多数(即使不是全部)稀疏算法都是针对相当简单和天真的任务(例如CIFAR-10/100、ImageNet、GLUE等)进行评估的,这可能会掩盖 SNN 的许多优势和意外的困境。为了追求更普遍的评估和揭示稀疏算法的真正潜力,本文提出"Sparsity May Cry”基准(SMC-Bench),一个精心策划的包含4种不同任务和12个数据集的集合,用于捕获广泛的特定领域知识。对具有代表性的SOTA稀疏算法进行了系统的评估,发现了一个重要的不明显的现象:所有的SOTA稀疏算法在 SMC-Bench 上的表现都很差,即使是稀疏度低至5%的情况下,这引起了稀疏社区的立即关注,重新思考 SNN 被高调宣扬的好处。通过纳入这些深思熟虑的各种任务,SMC-Bench 被设计用来支持和鼓励高度通用的稀疏算法的发展。
Sparse Neural Networks (SNNs) have received voluminous attention predominantly due to growing computational and memory footprints of consistently exploding parameter count in large-scale models. Similar to their dense counterparts, recent SNNs generalize just as well and are equipped with numerous favorable benefits (e.g., low complexity, high scalability, and robustness), sometimes even better than the original dense networks. As research effort is focused on developing increasingly sophisticated sparse algorithms, it is startling that a comprehensive benchmark to evaluate the effectiveness of these algorithms has been highly overlooked. In absence of a carefully crafted evaluation benchmark, most if not all, sparse algorithms are evaluated against fairly simple and naive tasks (eg. CIFAR-10/100, ImageNet, GLUE, etc.), which can potentially camouflage many advantages as well unexpected predicaments of SNNs. In pursuit of a more general evaluation and unveiling the true potential of sparse algorithms, we introduce "Sparsity May Cry" Benchmark (SMC-Bench), a collection of carefully curated 4 diverse tasks with 12 datasets, that accounts for capturing a wide-range of domain-specific knowledge. Our systemic evaluation of representative SOTA sparse algorithms reveals an important obscured observation: all of the SOTA sparse algorithms bluntly fail to perform on SMC-Bench, sometimes at significantly trivial sparsity as low as 5%, which sought immediate attention of sparsity community to reconsider the highly proclaimed benefits of SNNs. By incorporating these well-thought and diverse tasks, SMC-Bench is designed to favor and encourage the development of highly generalizable sparse algorithms. We plan to open-source SMC-Bench evaluation suite to encourage sparsity researchers and assist them in building next-generation sparse algorithms with the potential to generalize on complex and practical tasks.

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢