
传统的文本语言模型倾向于两阶段的训练模式,即首先在大规模语料库上进行预训练,然后在目标下游任务上进行微调,这种方式会受数据标注质量和过拟合等多方面的影响。最近兴起并流行的大型语言模型(large language models,LLM)已经克服了这类问题,并且会展现出惊人的ICL能力(In-Context Learning),无需对其进行明确的下游任务微调训练,即可执行上下文相关的小样本学习任务。这一观察使语言模型研究者们抛出了这样一个问题:到底是训练阶段中的哪些方面导致了这种上下文学习呢?
论文链接:https://arxiv.org/abs/2205.05055
代码链接:https://github.com/deepmind/emergent_in_context_learning
本文对ICL的发生机制进行了探索,与其他工作不同的是,作者以数据分布作为切入点进行研究,并且也获得了不小的理论发现。实验证明,数据中越是蕴藏着丰富的语义变化和差异,ICL进行的也越顺利。作者也进一步研究了ICL与传统权重学习之间的关系,同时提出了一种折中方案使模型能够同时具备这两种学习模式的优势。此外,作者强调了模型架构对ICL的决定性作用,基于Transformer的架构设计天然契合ICL的优化环境,这也是Transformer相比传统递归模型的优势体现。作者还考虑了发展ICL可以对社区产生更加广泛的影响,例如我们也可以从数据层面入手来设计和收集新领域的数据集,以求在语言理解以外的方向中也实现ICL,例如在图像领域也设计一个具备快速上下文学习能力的ICL视觉模型。
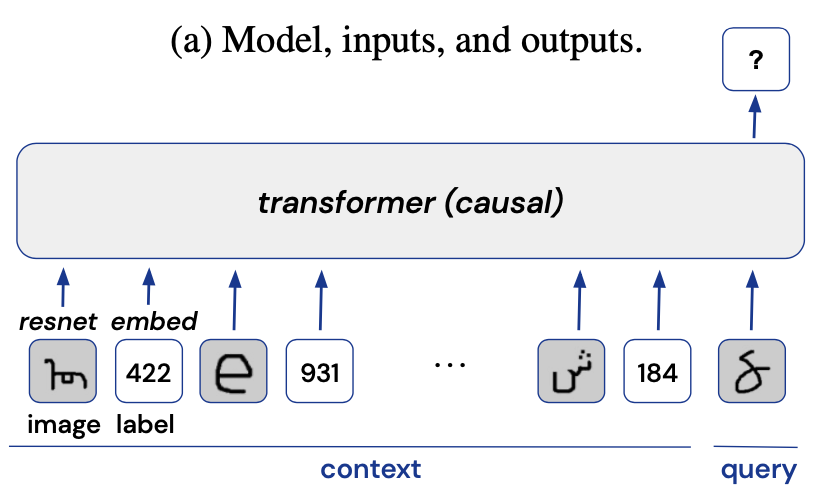
本文的实验模型设计简单直观,输入序列的每个元素首先通过两个编码器(一个用于对整数标签编码的标准嵌入层,一个用于对图像进行编码的ResNet)生成嵌入。随后这些嵌入的tokens被送入到一个因果Transformer模型[3]中,如下图所示。这里作者设置了12层且嵌入向量大小为64的Transformer层,模型最终对输入图像的预测使用softmax交叉熵损失函数进行优化。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢