
作者:Shahar Lutati, Eliya Nachmani, Lior Wolf
推荐理由:本文利用当前非常火爆的扩散模型,应用在语音信号分离的任务,并突破了当前的上限。
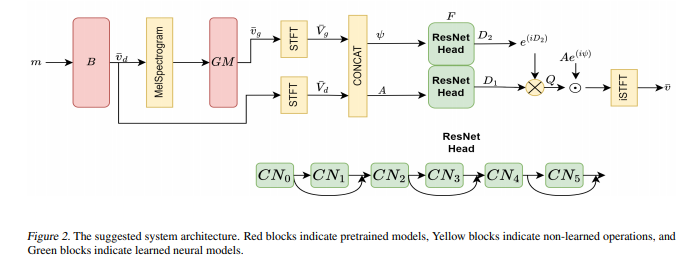
简介:语音分离问题,也称为鸡尾酒会问题,是指从混合语音信号中分离出单个语音信号的任务。先前关于源分离的工作得出了人类语音领域中源分离任务的上限。这个界限是为确定性模型导出的。生成模型的最新进展挑战了这一界限。作者展示了如何将上限推广到随机生成模型的情况。应用经过预训练的扩散模型 Vocoder 在确定性分离模型的输出上对单说话人的声音进行建模,将可以获取导致最先进的分离结果。实验结果表明:这需要将分离模型的输出与扩散模型的输出结合起来。在作者的方法中:在频域中执行线性组合,使用由学习模型推断的权重。作者在多个基准测试中展示了 2、3、5、10 和 20 个扬声器的最新结果。特别是,对于两个说话者的场景,作者的方法能够超越以前认为的性能上限。
论文下载:https://arxiv.org/pdf/2301.10752.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢