
作者:Zeyu Huang, Yikang Shen, Xiaofeng Zhang, 等
推荐理由:本文研究基于Transformer的语言模型的顺序模型编辑实用方法、并获取SOTA性能,该方法可以连续纠正大型PLM中的严重错误、包括产生偏见的预测和仇恨言论,从而产生积极广泛的社会影响。
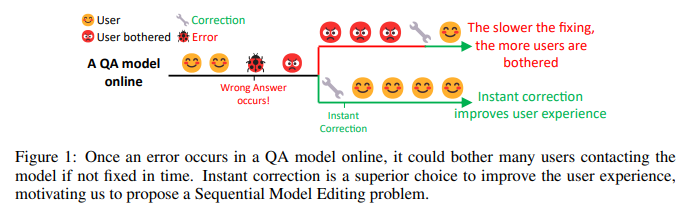
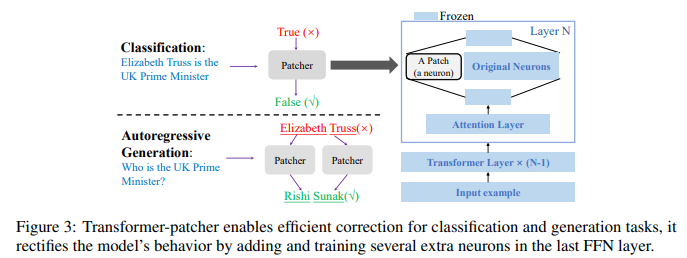
简介:基于大型 Transformer 的预训练语言模型 (PLM) 主导了几乎所有的自然语言处理 (NLP) 任务。尽管如此,他们仍然不时犯错误。对于部署在工业环境中的模型,快速而稳健地修复这些错误对于改善用户体验至关重要。以前的工作将模型编辑(ME)等问题形式化,并且主要集中在修复一个错误上。然而,一次错误修复场景并不是对现实世界挑战的准确抽象。在人工智能服务部署中,错误层出不穷,如果不及时改正,同样的错误可能会重演。因此,更好的解决方案是:一旦错误出现就立即纠正。因此,作者将现有的 ME 扩展为 Sequential Model Editing (SME),以帮助开发更实用的模型编辑方法。作者的研究表明:大多数当前的 ME 方法在这种情况下可能会产生不令人满意的结果。然后作者提出了 Transformer-Patcher:一种新颖的模型编辑器、可以通过简单地在最后一个前馈网络层中添加和训练神经元、以改变基于 transformer 的模型的行为。分类和生成任务的实验结果表明:Transformer-Patcher 可以连续纠正多达数千个错误(可靠性)并泛化到它们的等效输入(通用性),同时保持模型对不相关输入的准确性(局部性)。作者的方法优于以前的微调和基于 HyperNetwork 的方法,并实现了顺序模型编辑 (SME) 的最先进性能。
论文下载:https://arxiv.org/pdf/2301.09785.pdf
源码下载:https://github.com/ZeroYuHuang/Transformer-Patcher
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢