
作者:Xinyi Wang, Wanrong Zhu, William Yang Wang
推荐理由:本文以创新的视角(通过贝叶斯视角)理解大型语言模型,并将其假设为从提示中推断潜在概念变量的隐式主题模型。
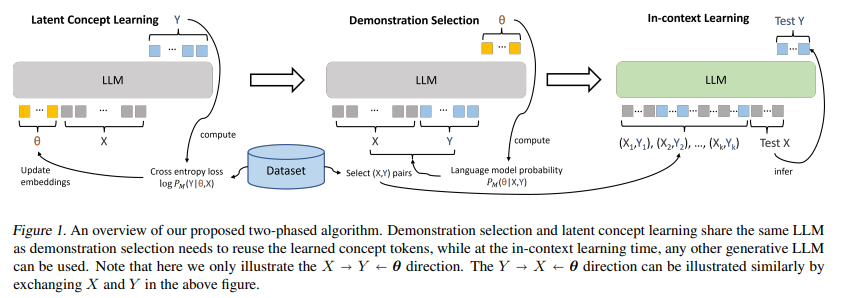
简介:近年来,在实现称为“上下文学习”推理时的小样本学习能力方面,预训练的大型语言模型表现出显着的效率。然而,现有文献强调了这种能力对小样本选择的敏感性。这种能力从常规语言模型预训练目标中产生的潜在机制仍然知之甚少。在这项研究中,作者旨在通过贝叶斯透镜检查上下文学习现象,将大型语言模型视为从演示中隐式推断任务相关信息的主题模型。在此前提下,作者提出了一种从一组带注释的数据中选择最佳演示的算法,并证明相对于随机选择基线有 12.5% 的显着改进,在八个不同的真实世界文本分类数据集上平均超过八个 GPT2 和 GPT3 模型。作者的实证研究结果:支持了作者的假设,即大型语言模型隐含地推断出一个潜在的概念变量。
论文下载:https://arxiv.org/pdf/2301.11916.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢