

论文链接:https://arxiv.org/pdf/2203.06844.pdf
源码链接:https://github.com/implus/RecursiveMix-pytorch
背景
数据增强一直是图像领域的基本操作,能够在数据量不变的情况下,增强神经网络的泛化性能,尤其是对Transformer等大参数量的模型来说,数据量不够很容易导致欠拟合。
混合增广算法是一种常用的增广策略,常用于提升深度模型的泛化能力。知名算法包括MixUp和CutMix。
现在的混合增广算法只关注于混合当前训练周期的数据样本,忽略了之前训练过程中累计的知识。本文介绍的增广方法RecursiveMix可以较好地利用历史训练过程得到的样本-预测-标签三元组。
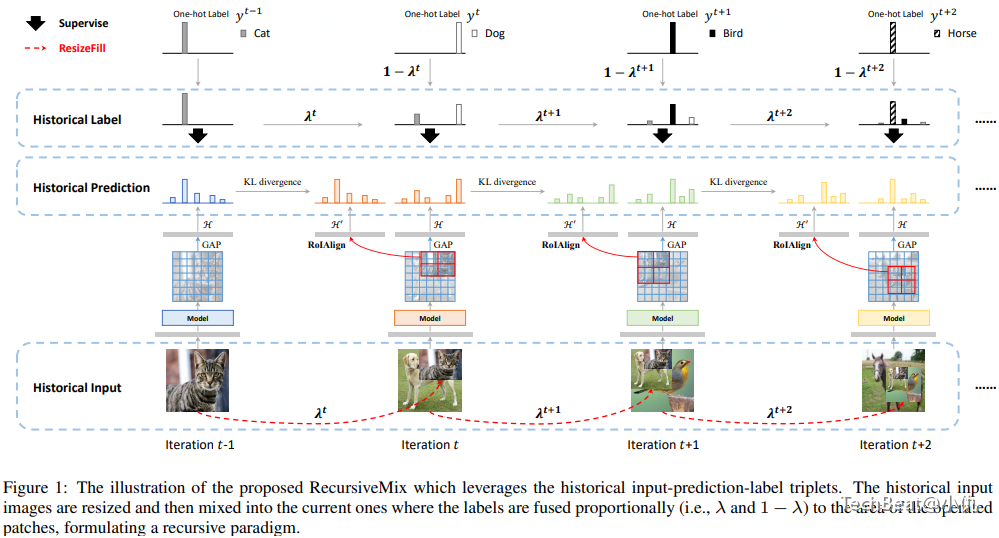
方法
本文方法主要思想是重用历史训练过程中得到的输入-预测-标签三元组与当前训练样本混合。历史训练图片重新调整大小后,然而将其填充入当前图片中。
这里定义在 t 周期训练样本 \( (\hat{x}^t,\hat{y}^t) \) ,通过组合当前训练样本 \( (x^t,y^t) \) 和历史样本 \( (x^h,y^t) \) 。新生成的样本 \( (\hat{x}^t,\hat{y}^t) \) 参与使用CE损失函数的训练中。生成样本过程可以描述为:
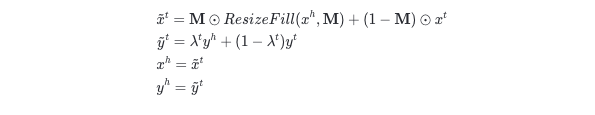
其中 是描述历史样本填充位置的二进制掩码。 在采样的矩形框区域 B=(rx,ry,rw,rh) 内都设置为1。
另外重新调整大小后填充如输入图片的部分应该与原先历史样本除了尺寸和比例是语义一致的。这里需要优化跨周期相应区域预测结果间的KL散度。特殊的,这里需要记录历史训练过程中得到的预测结果。
这里使用 1× 的RoIAlign层提取填充后图像对应区域的局部特征。训练本文模型的损失函数
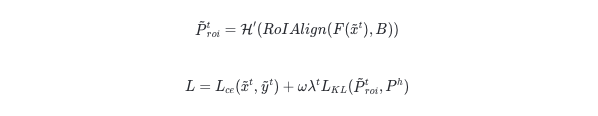
与MixUp和CutMix增广算法类似,本文的增广策略也只需要引入少量的计算成本。相对于整个模型,数据集和特征,历史训练得到的预测带来的存储成本几乎是可以忽略的。
本文提出的增广方法主要优势是:
-
由于尽可能的探索多个实例间的组合和更丰富的训练信号,本文方法鼓励数据空间的多样化,
-
显示地为具有多尺度和多空间变体视图的实例提供连续的监督信号,
-
通过对比学习利用相邻两个迭代的输入的一致性。
实验
表1给出了PyramidNet-200模型与不同增广算法在CIFAR10数据集上性能比较。本文的RecursiveMix算法取得了比baseline高出1.5%的精度。同时比广泛使用的MixUp与CutMix算法高出0.74%,0.53%
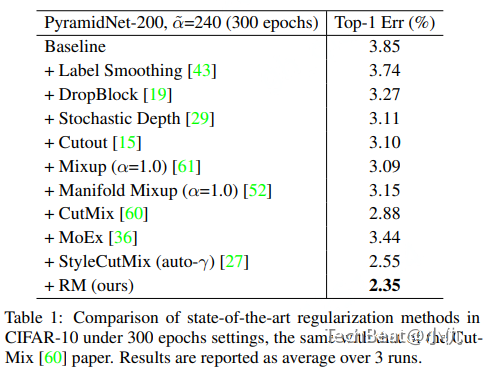
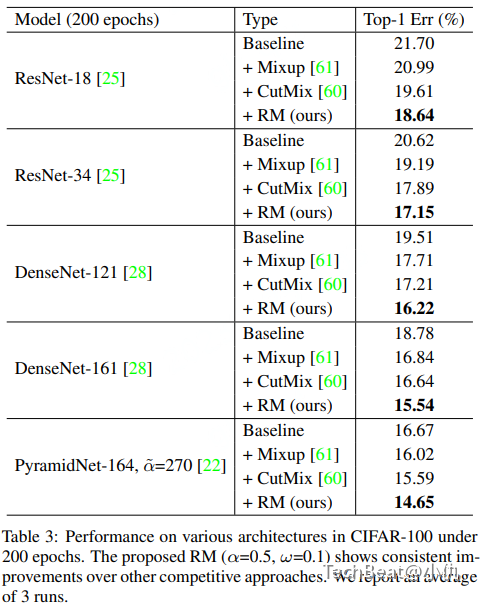
表1给出了ResNet-18,ResNet-34,DenseNet-121,DenseNet-161与PyramidNet-161模型与不同增广算法在CIFAR100数据集上性能比较。可以看出本文方法在各模型上都有提升。特别是在DenseNet-161上,比baseline方法提升了3.2%,另外比CutMix提升了1.1%。
关于超参数一致性损失项系数 ω 的消融实验:图3给出了实验结果。可以看出0.1达到的最优的性能。另外在CIFAR10数据集上不同的 ω 值对性能不敏感。
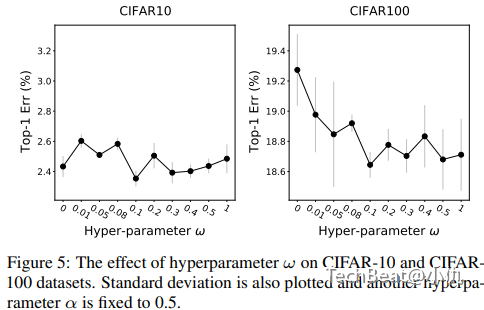
表5给出了ImageNet数据集上的实验结果。文本方法也取得了更高的精度。
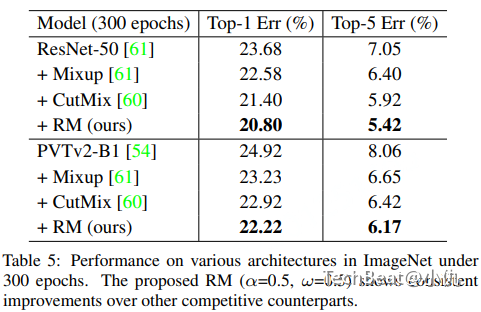
表7给出了在目标检测任务上不同模型与不同增广算法结合的性能比较。比较的目标检测模型包括ATSS和GFL。ATSS模型下在ResNet-50作为backbone比baseline提升了2.1%,PVTv2-B1作为backbone比baseline提升了3.0。与CutMix算法相比分别提升了1.4%和0.5%。
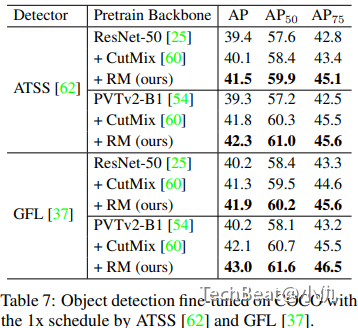
表8给出了在实例分割任务上不同模型与不同增广算法结合的性能比较。实例分割模型包括Mask R-CNN和HTC。本文的方法在bbox mAP和mask mAP指标上分别提升了大约2.8%和2.0%。
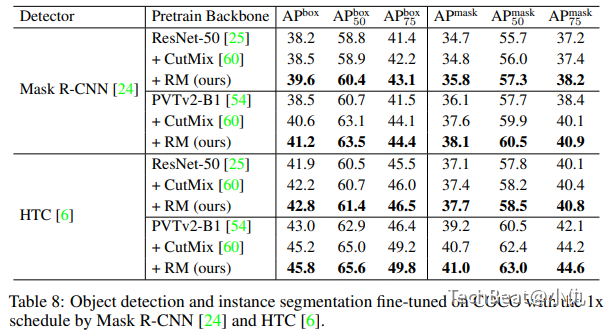
表9给出了在语义分割任务上不同模型与不同增广算法结合的性能比较。语义分割模型包括PSPNet和UperNet。结果表明本文方法在各种组合下都超过了baseline和CutMix.值得注意的,在UperNet与ResNet-50组合条件下,本文方法在mIOU指标上超过baseline和CutMix1.9%和1.1%。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢