
ChatGPT的推出在学界和业界引起了广泛的关注和讨论,人们对ChatGPT的强大能力产生了极大的兴趣,同时也引起了社会对于AIGC(AI-generated content)潜在风险的担忧。
在这样的背景下,我们一群来自上海财经大学、哈尔滨工业大学(深圳)、北京语言大学、西安电子科技大学、加拿大皇后大学以及万得信息技术有限公司的博士生或工程师,共同组建了一个研究团队,展开了一项名为「ChatGPT对比&检测」的研究项目。项目组成立于2022年12月9日,距离ChatGPT推出仅仅过去了10天,可能是国际上最早展开ChatGPT与人类对比分析研究和开发ChatGPT内容检测器的团队。
今年1月19日,我们将初步研究成果发布于Arxiv,并开源了相关的数据集和模型。
-
论文标题:How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection -
论文链接:https://arxiv.org/pdf/2301.07597.pdf -
项目主页:https://github.com/Hello-SimpleAI/chatgpt-comparison-detection
欢迎大家关注并提出宝贵意见!
下面由「ChatGPT对比&检测」项目负责人,上海财经大学AI Lab博士生——郭必扬,对论文内容进行简要解读:

一、研究背景和主要贡献
ChatGPT的强大能力想必熟悉NLP的人已经十分了解,除了传统的文本分类、实体抽取、文本翻译等任务,ChatGPT可以成功应对各种十分具有挑战性的任务,比如根据自然语言编写代码、根据关键词写出丰富的故事、可以模仿各种风格和口吻进行创作等等。ChatGPT推出不到一周,全球注册用户就超过100万,已经被广泛用于日常问答和专业咨询。
在这样的背景下,人们一方面对ChatGPT如何做到这么强大抱有强烈兴趣,例如我们好奇ChatGPT和人类专家的距离到底还有多远;另一方面人们又开始对诸如ChatGPT这样的大模型对社会造成的潜在冲击产生担忧,例如著名程序员问答平台Stack Overflow已经禁止用户使用ChatGPT进行回答。
在这样的背景下,我们团队的项目从以下几个方面做出为学界、产业界做出了贡献:
-
我们收集了近4万条和问题和对应的人类以及ChatGPT的回答,包含了开放域、计算机、金融、医疗、法律、心理等多个领域,并且兼顾了中文和英文。我们称这个数据集为 Human ChatGPT Comparison Corpus (HC3),这个数据集可用于大型语言模型(LLMs)相关的研究,尤其是研究人类跟LLMs的差异。 -
我们进行了大量的人工测评和语言学分析,发现了很多有意思的结论,这些发现有助于我们思考未来大型语言模型应走向何方; -
根据我们的HC3数据集和分析,我们开发了多种ChatGPT内容检测器,应对不同的场景。这些检测器可用于UGC(User-generated Content)平台的监管,提升内容的可靠性、安全性。
二、人类专家-ChatGPT 对比语料集
我们收集的人类回答主要来自两方面:
-
领域专家的回答(例如医疗领域的医生回答,法律领域的律师解答等) -
UGC平台的高赞回答(例如Reddit、知乎等平台的高点赞回答)
由于高赞回答也是进过网友推选出来的,内容一般是比较可靠和专业的,因此我们也称之为专家回答。
我们的大部分人类回答,是采集于公开数据集,还有一部分则是通过对WIkipedia、百度百科的词条进行构造而形成。
ChatGPT的回答则是通过OpenAI开放的ChatGPT预览网页进行获取。
我们总共收集了超过3万7千个问题,以及对应的超过8万条人类专家回答和超过4万条ChatGPT回答。覆盖了开放域、计算机、金融、医疗、法律、心理学等多个领域。下面是我们收集的数据的总览:
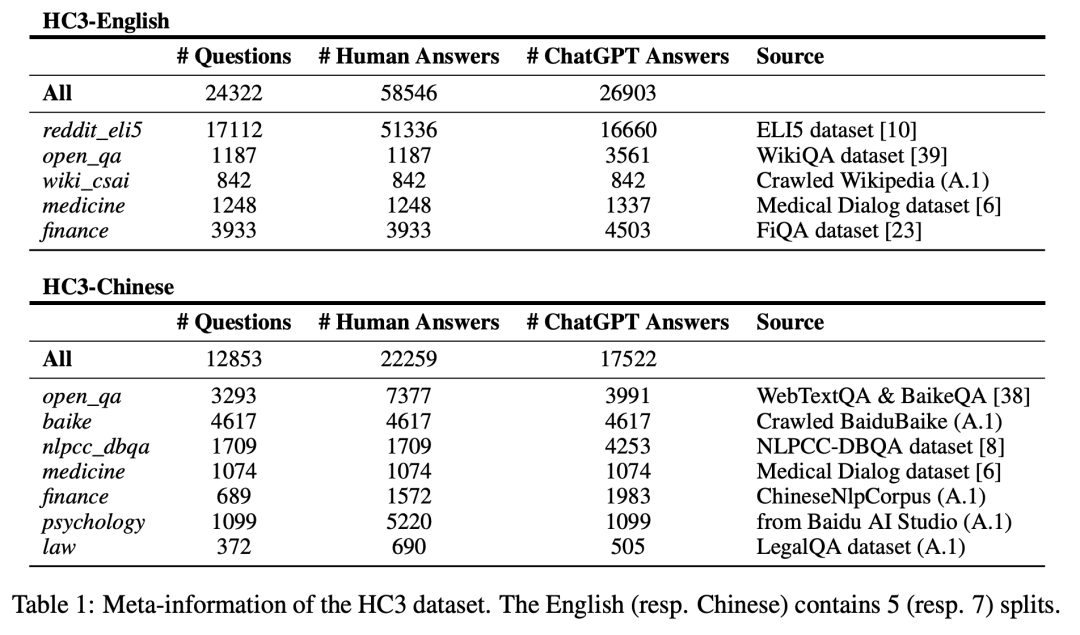
我们的数据都以JSON字典的格式进行存储,方便大家进行使用:

通过这个数据集,我们可以做很多种任务。我们论文中展示的人工测评、语言学分析、检测模型开发只是很小的一部分使用场景,未来还可以探索更多有趣的研究。
三、人工测评
我们做了4种有趣的人工测评,包括3组图灵测试,和1组“有用性”测试。分别是:
-
给专家的有人机对比测试(一个问题,两个回答,一条来自ChatGPT一条来自人类,需要判断哪个是ChatGPT,专家指的是很熟悉ChatGPT的人) -
给专家的单条测试(一个问题,只有一个回答,然后判断回答是不是ChatGPT写的) -
给业余选手的单条测试(找完全没听说过ChatGPT的志愿者做的) -
有用性测试,看对于一个问题是人类回答更有帮助,还是ChatGPT更有帮助。
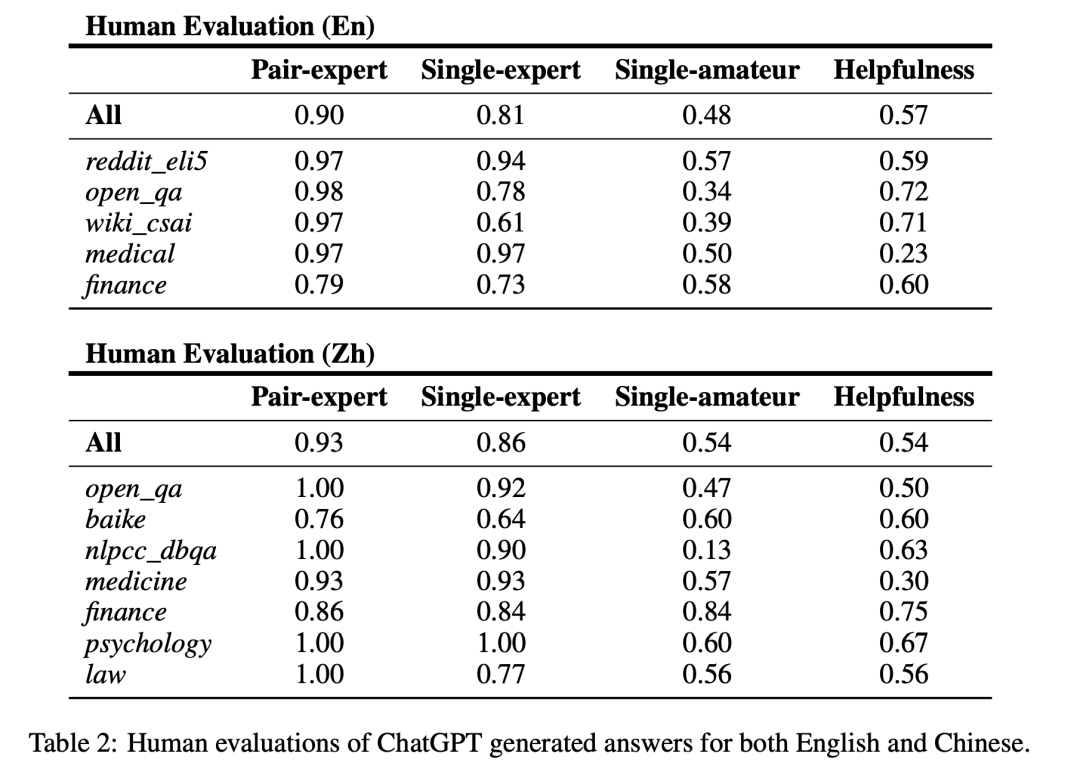
结果如上图所示,我们可以得出如下结论:
- 专家来判断,那简直是太容易了,给专家的对比测试,很多数据集直接100%正确,这说明经常使用ChatGPT的人,已经深谙它的套路了,尤其跟人的回答可以直接对比的情况下;
- 对于专家,如果只给一条文本,这时准确率就下降了,差不多降低了10%,但依然很高;
- 一旦一个人不知道ChatGPT,那可就麻烦大了,基本一半的情况下都可能猜错,有些数据集,甚至准确率可能低到不到20%(有可能是那个数据集的人类回答太差了,让我们的志愿者觉得这个像机器,但这也说明,普通大众对于机器文本生成的水平,还了解很有限)。
更有趣的则是一个“有用性测试”,即图中的helpfulness,我们是受到OpenAI的InstructGPT论文的启发,他们一直在强调InstructGPT提升了有用性,我们就想看看,到底这方面咋样。所以在测试时,我们给出一个人的回答一个ChatGPT的(当然具体谁是谁是不告知的),然后要求志愿者回答“你认为哪个回答对于这个问题更有帮助?”,没想到啊,ChatGPT在这方面,还真的挺不错,但也没有那么不错:微微超过一半的情况,ChatGPT的回答被认为是更有用的,比方金融问题中,ChatGPT的回答一般十分专业、详细,甚至能让人学到很多知识。但是对于有些领域则不太行,比如医疗领域,这可能是涉及的知识过于专业,在ChatGPT训练语料中并不很多,导致ChatGPT回答有时候过于模糊,而人类专家则直击痛点,所以被认为更有帮助。
四、语言学分析
我们对人类和ChatGPT各自的回答,做了词汇量、词汇密度、词性、依存关系、情感分析和模型困惑度等方面的分析,下面我简单介绍两个方面的结果,其他方面如果读者感兴趣,请阅读我们的论文。
词汇特征:
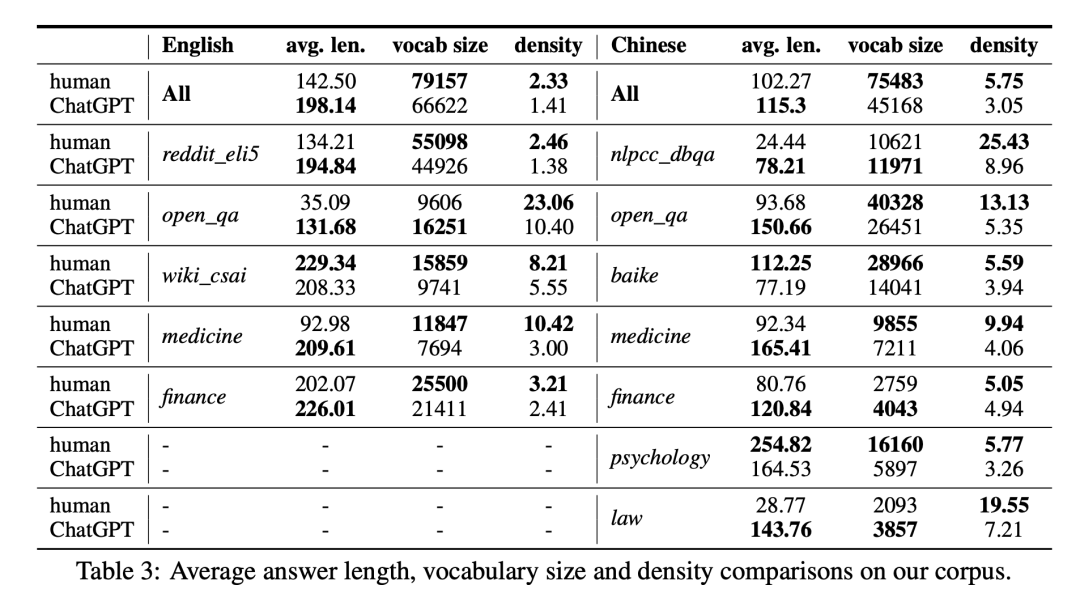
我们统计了平均长度、词汇量还有词语密度三个特征。具体看上表。我们对上面的结论,总结了一句话:人类的回答一般更短,但却说了更丰富的词汇。具体体现在:我们计算了收集到的所有的领域,发现人类的词汇密度都比ChatGPT高!这是个挺有意思的结论。
究其原因,ChatGPT毕竟是个语言模型,词汇选择本身是有限制和倾向性的,而且ChatGPT在RLHF的过程中还遭受了OpenAI的“严苛的驯化”,已经变得不能乱说话了,这也对词汇量有很大的限制。相比之下,人类则是自由的,而且我们的数据集的人类部分是来自很多不同的人,而不是某个具体的人,因此提现出来的词汇量就大得多。
情感分析:
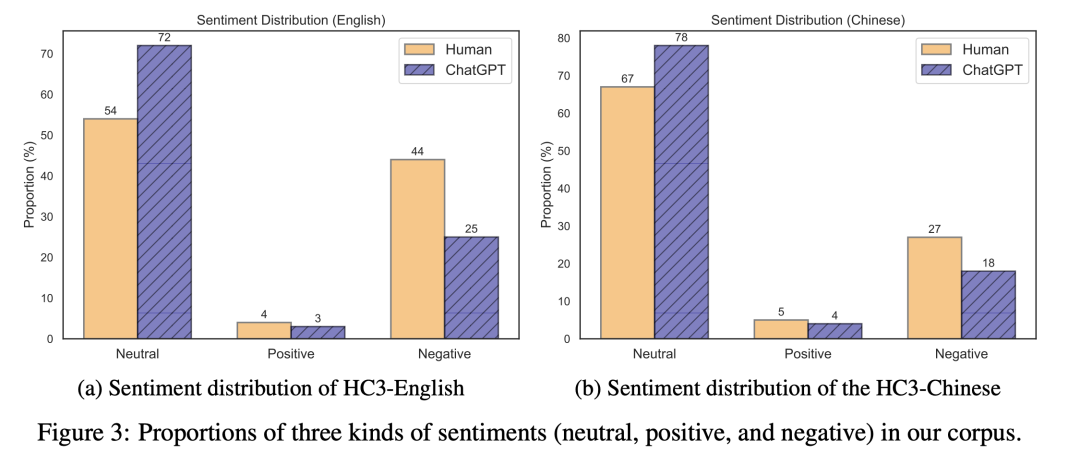
我们使用开源的情感分析模型,对收集的数据进行了情感分析。
可以理解的是ChatGPT相对来说更加“中立”,但不理解的是——人类为啥负面情绪这么大?
当然,这里的负面情绪,并不都是恶意的,有的可能只是情绪较为悲观、不够自信、比较犹豫等等造成的,但从情感分析模型的角度而言,ChatGPT确实更加理性甚至“正能量”一点。
其他方面的研究也很有意思,欢迎大家移步论文查看细节。
五、ChatGPT检测器
ChatGPT生成内容逐渐风靡各大平台,很多平台都面临着内容可靠性的考验,因此无论从平台角度还是从用户角度,我们都需要有AI生成内容的检测器,来帮助我们判断内容是否是由AI生成的,从而避免潜在的风险。
我们开发了三种类型的检测器,用于不同的场景:
-
QA version / 问答版: 判断某个问题的回答是否由ChatGPT生成,使用基于PTM的分类器来开发; -
Sinlge-text version / 独立文本版: 判断单条文本是否由ChatGPT生成,使用基于PTM的分类器来开发; -
Linguistic version / 语言学版: 判断单条文本是否由ChatGPT生成,使用基于语言学特征的模型来开发;
前两种都是基于预训练模型RoBERTa进行微调训练得到的,最后一种则是使用各种语言学特征构建机器学习模型,使用的经典的GLTR方法。实际训练的时候,我们还需要考虑做一些数据的清洗,比如ChatGPT或者人会有一些明显pattern词汇,那我们就会对这些pattern进行清理,实验也证明这个可以一定程度提升泛化性能。然后我们还试验了使用不用粒度的数据来训练,因为我们发现如果仅仅在全文上训练,在单个句子上的泛化性能就比较差。所以这么一来,就涉及很多种不同模型设置,下面是我们主要的实验结果:
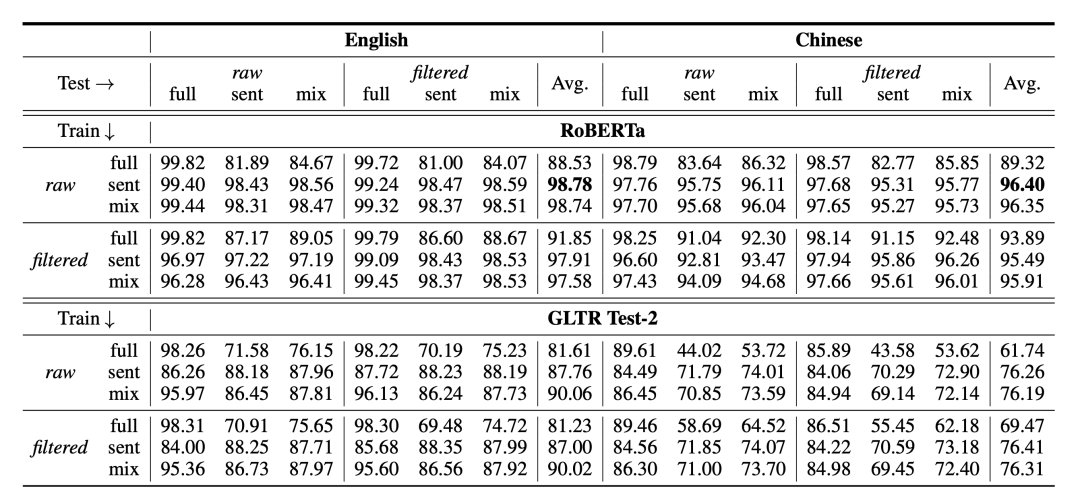
我们发现几下一些结论:
-
基于深度学习的方法,效果明显优于机器学习的方法; -
在句子层面进行检测的难度明显高于全文层面 -
对指示词进行过滤,可以帮助全文提升检测性能,但是却可能影响句子层面的检测效果
我们还对比了QA版本和单文本版的性能差异,发现如果能提供对应的问题,检测性能也可以明显提高。我们还对不同的数据来源的检测效果进行了对比,发现不同领域的检测效果也存在显著差别,这些实验都在论文中进行了详细地讨论,欢迎大家阅读论文。
大家可以直接通过以下链接来访问我们的检测器:
-
QA版本检测器:https://huggingface.co/spaces/Hello-SimpleAI/chatgpt-detector-qa -
单文本版:https://huggingface.co/spaces/Hello-SimpleAI/chatgpt-detector-single -
语言学版:https://huggingface.co/spaces/Hello-SimpleAI/chatgpt-detector-ling
总结
这项工作提出了首个「人类-ChatGPT」问答对比语料集,并开发了首套支持双语的ChatGPT检测器,并且进行了广泛的人工测评、语言学分析、检测实验,得出了很多有意思的结论。希望我们的研究能对LLMs,AIGC等方面的研究和应用有一定启发借鉴作用。最后希望大家关注我们的项目,并提出宝贵意见:
项目主页:https://github.com/Hello-SimpleAI/chatgpt-comparison-detection

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢