
来自今天的爱可可AI前沿推介
[AS] Moûsai: Text-to-Music Generation with Long-Context Latent Diffusion
F Schneider, Z Jin, B Schölkopf
[ETH Zürich & Max Planck Institute for Intelligent Systems]
Moûsai: 基于长程上下文潜扩散的文本到音乐生成
要点:
-
开发了 Moûsai,用于文本到音乐的生成,基于长上下文潜扩散; -
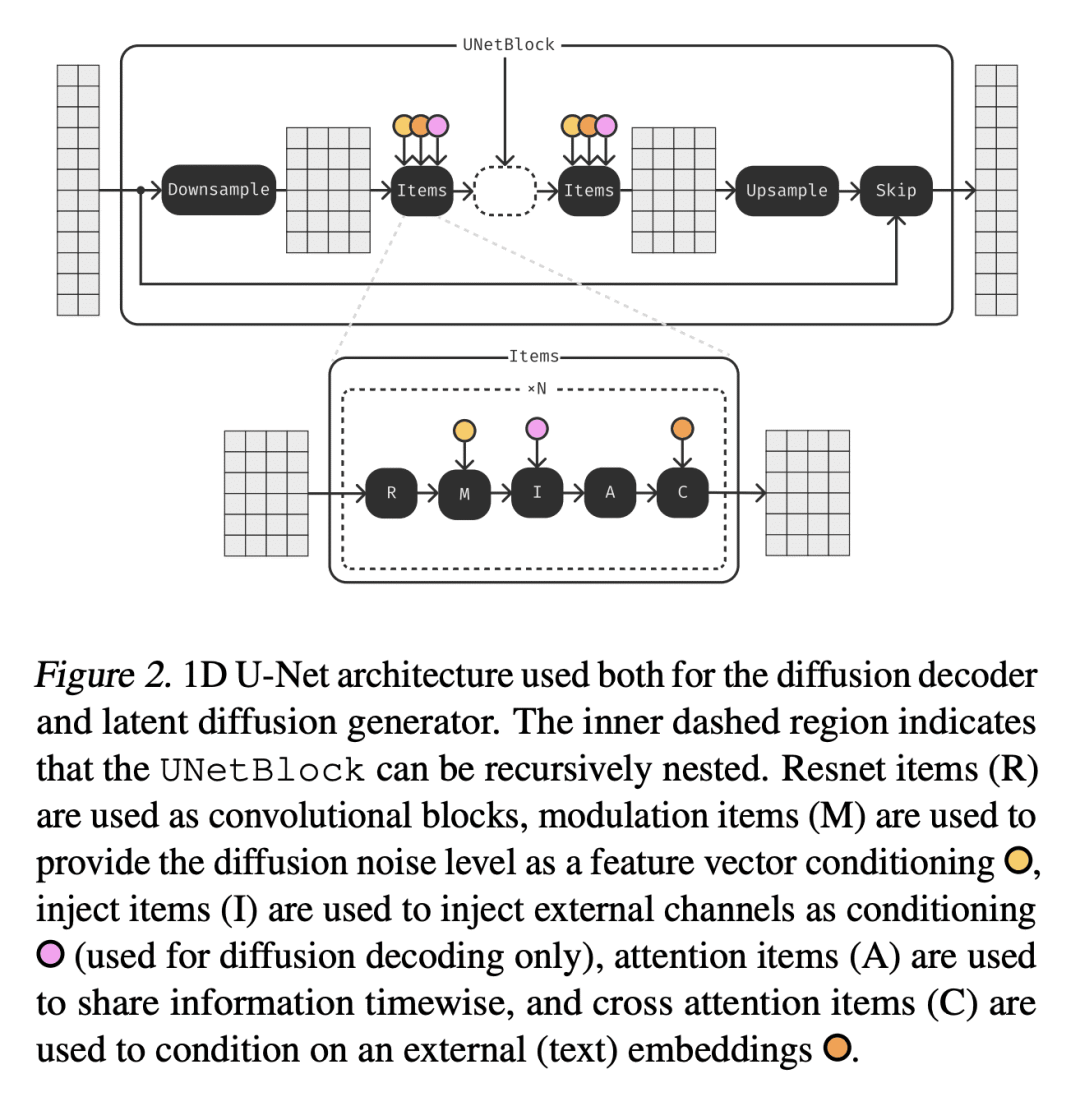
提出高效的 1D U-Net 架构,用于在消费级GPU上实时生成音频; -
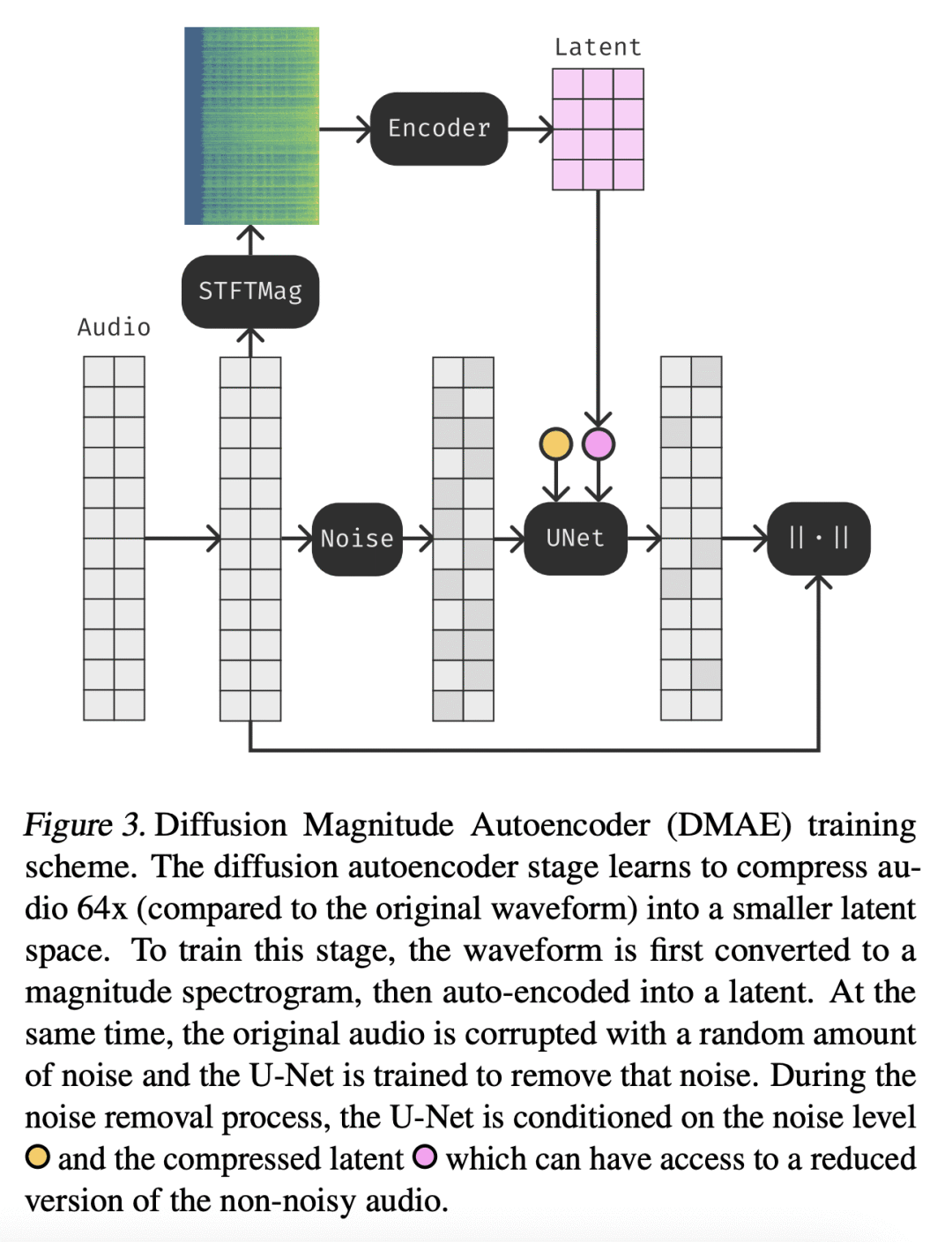
使用扩散自编码器,将频谱压缩至64倍。
一句话总结:
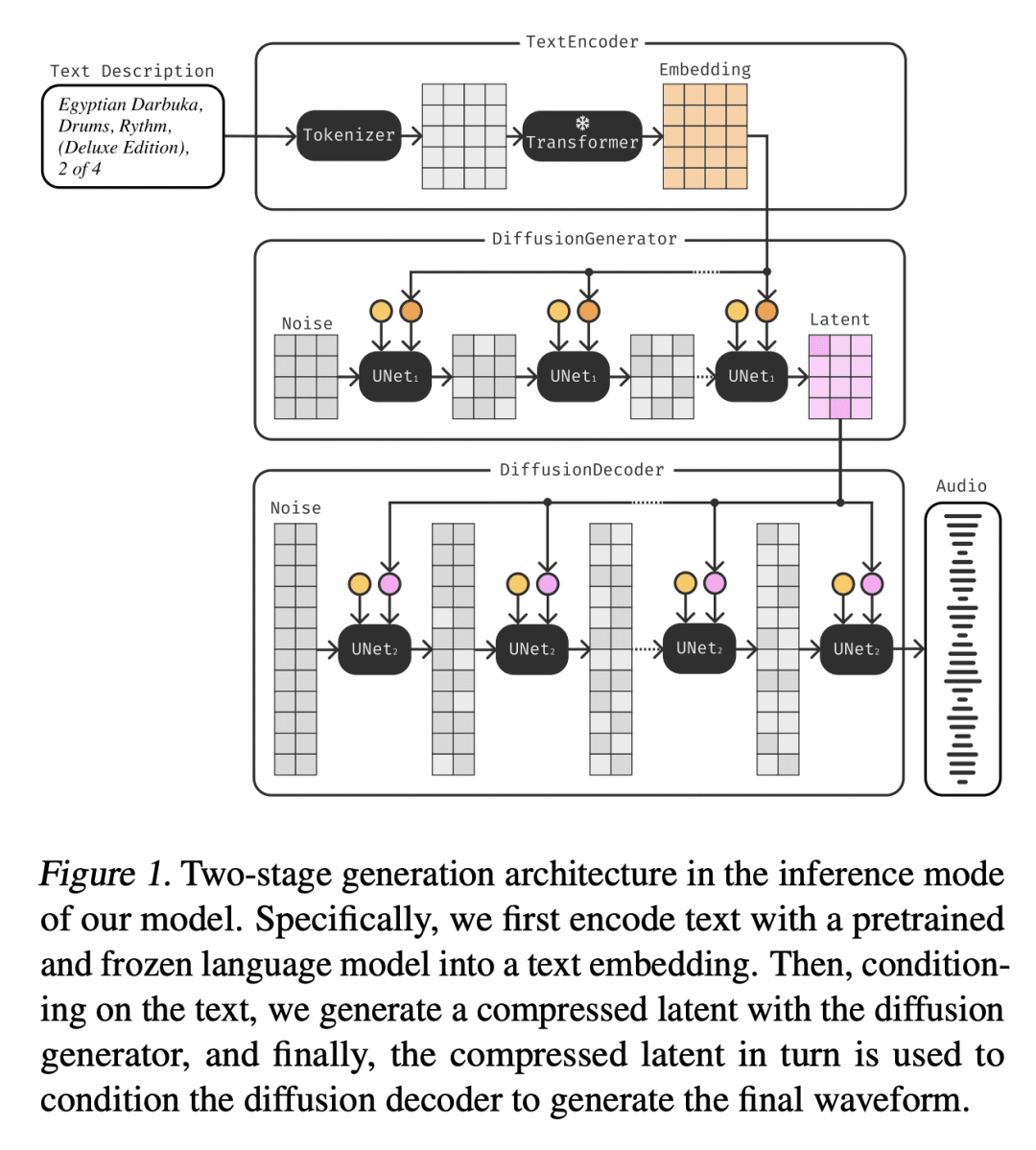
Moûsai 是一种文本到音乐的生成方法,使用基于两个扩散模型和自定义 1D U-Net 架构的级联潜扩散方法实时生成高质量、长程上下文的立体声音乐。
摘要:
最近,用于图像生成的扩散模型大受欢迎,使人们重新关注这些模型在媒体合成的其他领域的潜力。一个尚未被充分探索的领域是将扩散模型应用于音乐生成。音乐生成需要处理多个方面,包括时间维度、长程结构、多层叠加的声音,以及只有受过训练的听众才能发现的细微差别。本文研究了扩散模型的文本条件音乐生成的潜力,开发了一种级联潜伏扩散方法,可以从文本描述中生成长达多分钟的48kHz的高质量立体声音乐。对每个模型,努力保持合理的推理速度,目标是在单个消费级GPU上实现实时。
The recent surge in popularity of diffusion models for image generation has brought new attention to the potential of these models in other areas of media synthesis. One area that has yet to be fully explored is the application of diffusion models to music generation. Music generation requires to handle multiple aspects, including the temporal dimension, long-term structure, multiple layers of overlapping sounds, and nuances that only trained listeners can detect. In our work, we investigate the potential of diffusion models for text-conditional music generation. We develop a cascading latent diffusion approach that can generate multiple minutes of high-quality stereo music at 48kHz from textual descriptions. For each model, we make an effort to maintain reasonable inference speed, targeting real-time on a single consumer GPU. In addition to trained models, we provide a collection of open-source libraries with the hope of facilitating future work in the field.
论文链接:https://arxiv.org/abs/2301.11757
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢