
作者:Rongjie Huang, Jiawei Huang, Dongchao Yang,等
推荐理由:本文研究在“文本到音频”领域应用当前流行的扩散模型,而且本文是业界首次尝试在用户定义的模态输入下生成高清、高保真音频。
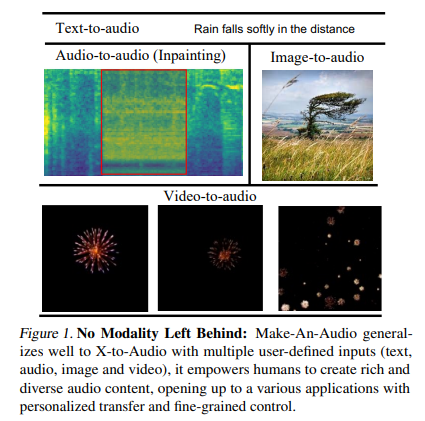
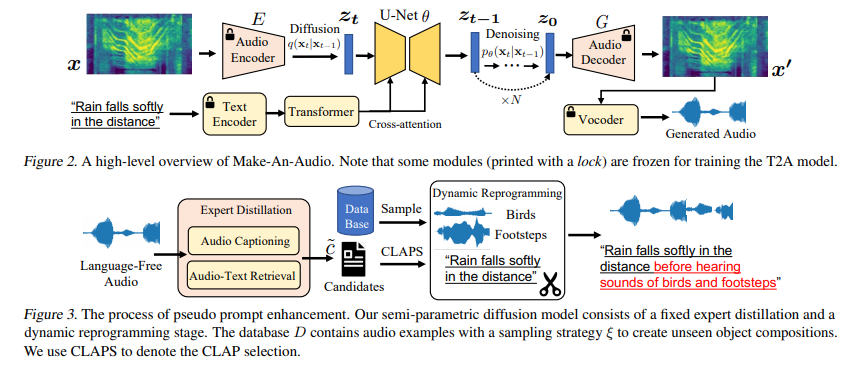
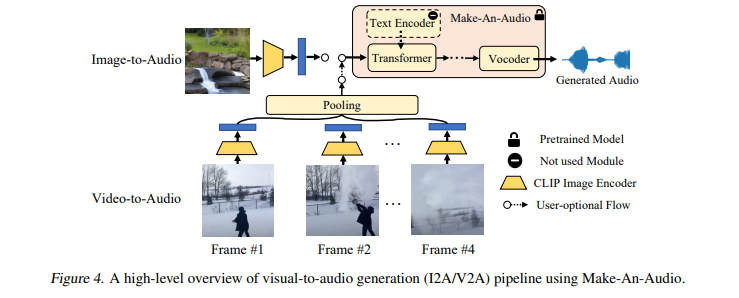
简介:大规模多模态生成建模在文本到图像和文本到视频生成方面创造了里程碑,但在音频方面的应用仍然落后。主要原因有两个:缺乏具有高质量文本-音频对的大规模数据集,以及对长时间连续音频数据建模的复杂性。在这项工作中,作者提出了具有提示增强扩散模型的 Make-An-Audio,该模型通过以下方式解决了这些差距:1) 通过蒸馏然后重新编程方法引入伪提示增强,其通过使用无语言音频;2)利用频谱图自动编码器来预测自监督音频表示而不是波形。连同强大的对比语言-音频预训练 (CLAP) 表示,Make-An-Audio 在客观和主观基准评估中均取得了最先进的结果。此外,作者展示了对 X-to-Audio 的可控性和泛化性,“不落模态”:首次解锁了在给定用户定义的模态输入的情况下生成高清、高保真音频的能力。
论文下载:https://arxiv.org/pdf/2301.12661.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢