
来自今天的爱可可AI前沿推介
[AS] SingSong: Generating musical accompaniments from singing
C Donahue, A Caillon, A Roberts, E Manilow, P Esling, A Agostinelli, M Verzetti, I Simon, O Pietquin, N Zeghidour, J Engel
[Google Research]
SingSong: 为哼唱生成音乐伴奏
要点:
-
用生成模型为人声输入创建连贯的器乐伴奏; -
用音源分离来创建音频到音频伴奏的训练数据; -
将最先进的非条件音频生成模型修改为条件音频到音频模型。
一句话总结:
SingSong 用生成模型、音源分离和条件音频生成模型为人声输入生成器乐伴奏,以清晰的和声和时间对应实现了强大的定性性能。
摘要:
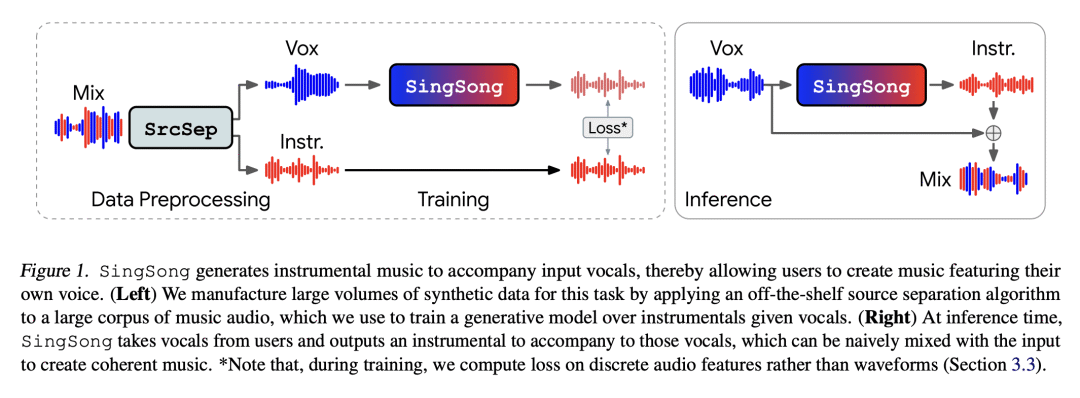
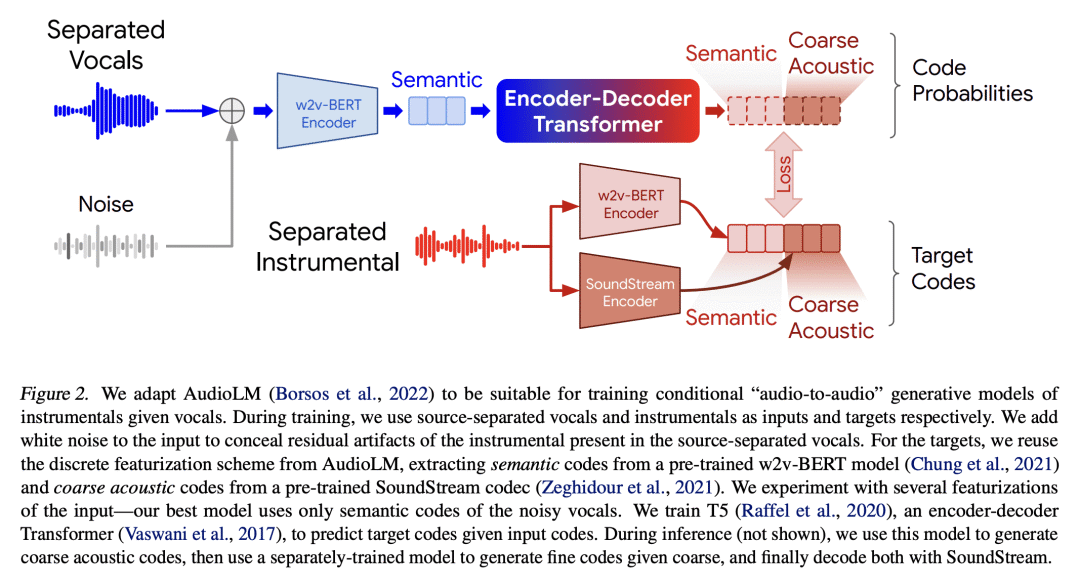
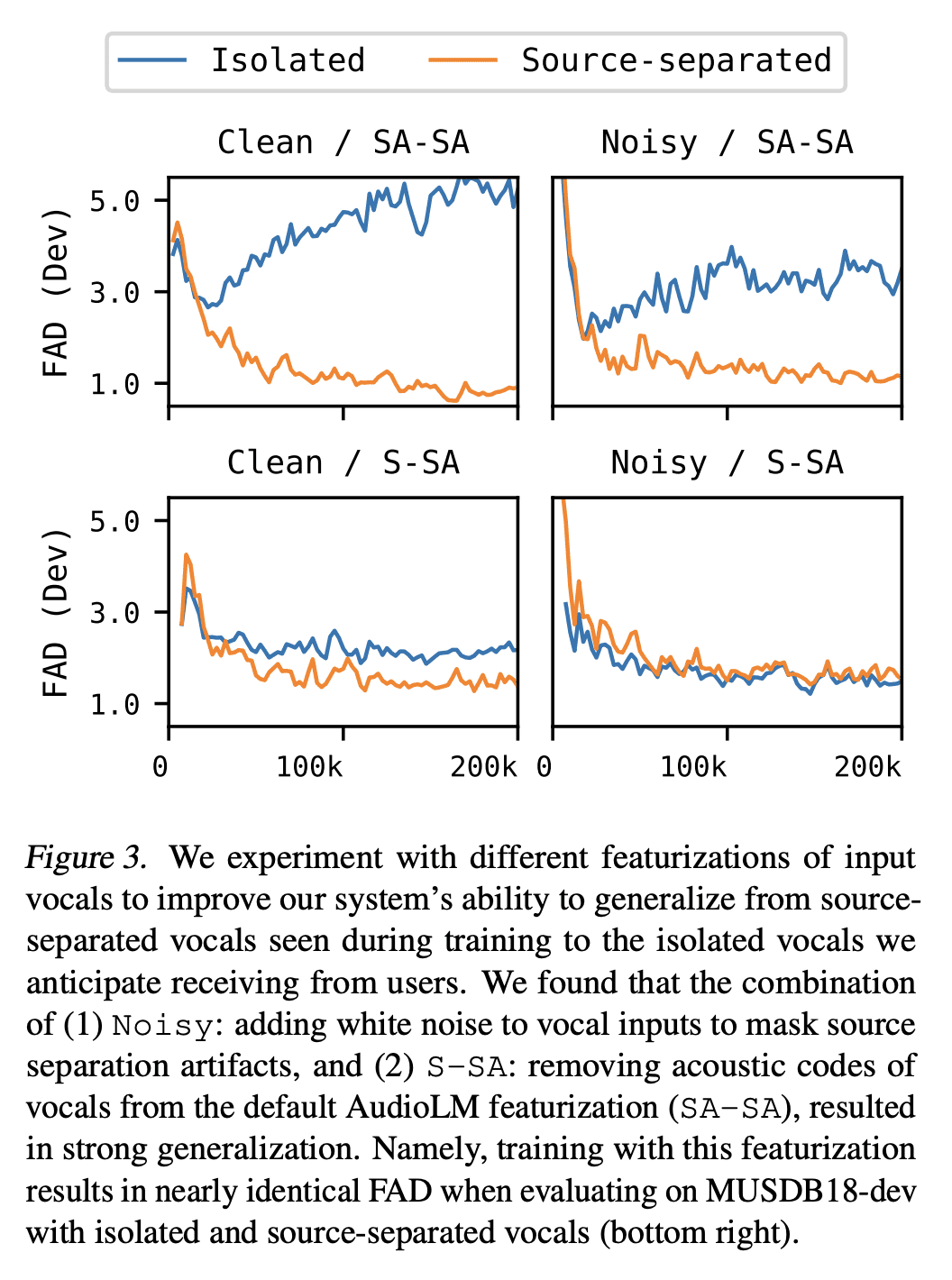
本文提出SingSong,一种可以生成器乐来配合输入人声哼唱的系统,可能为音乐家和非音乐家提供一种直观的新方法来创造具有他们自己声音的音乐。为了实现这一目标,本文在音源分离和音频生成方面的最新发展的基础上,将最先进的音源分离算法应用于大型音乐音频语料库,以产生一致的人声和器乐音源对。对AudioLM —— 一种最先进的非条件音频生成方法——进行调整,使其适用于条件"音频到音频"生成任务,并对分离出的声源(人声、器乐)对进行训练。在与相同的人声输入进行的配对比较中,与来自强检索基线的乐器相比,听众对 SingSong 生成的乐器表示出明显的偏好。
We present SingSong, a system that generates instrumental music to accompany input vocals, potentially offering musicians and non-musicians alike an intuitive new way to create music featuring their own voice. To accomplish this, we build on recent developments in musical source separation and audio generation. Specifically, we apply a state-of-the-art source separation algorithm to a large corpus of music audio to produce aligned pairs of vocals and instrumental sources. Then, we adapt AudioLM (Borsos et al., 2022) -- a state-of-the-art approach for unconditional audio generation -- to be suitable for conditional "audio-to-audio" generation tasks, and train it on the source-separated (vocal, instrumental) pairs. In a pairwise comparison with the same vocal inputs, listeners expressed a significant preference for instrumentals generated by SingSong compared to those from a strong retrieval baseline.
论文链接:https://arxiv.org/abs/2301.12662
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢