
来自今天的爱可可AI前沿推介
[CL] Grounding Language Models to Images for Multimodal Generation
J Y Koh, R Salakhutdinov, D Fried
[CMU]
面向多模态生成的语言模型到图像Grounding
要点:
-
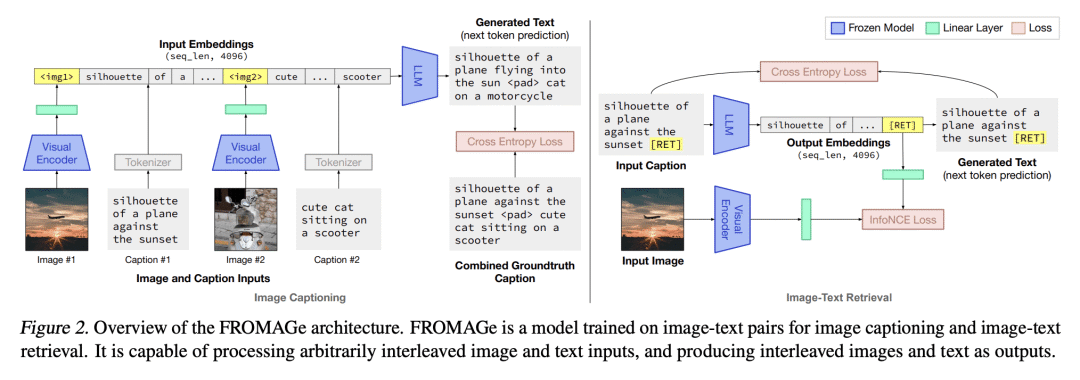
提出多模态数据冻结检索自回归生成(FROMAGe)模型,通过图像描述和对比学习的视觉 grounding 大规模语言模型进行高效训练; -
证明自回归大规模语言模型可以在对输入文本更敏感的情况下执行文本到图像检索; -
表明预训练的纯文本大规模语言模型的现有功能可以用于视觉 grounded 任务。
一句话总结:
提出一种通过图像描述和对比学习的视觉 grounding 大规模语言模型进行高效训练,使它们能够处理和产生任意交错的图像和文本数据。FROMAGe 模型能产生连贯的多模态输出,并在各种任务中显示出强大的零样本性能。
摘要:
本文提出一种有效的方法,将预训练的纯文本语言模型用于视觉领域,使其能处理和生成任意交错的图像-文本数据。所提出方法利用了从大规模纯文本预训练中学到的语言模型的能力,如上下文学习和自由格式文本生成。保持语言模型的冻结,并对输入和输出线性层进行微调,以实现跨模态的交互。这使得该模型能处理任意交错的图像-文本输入,并生成与检索图像交错的自由格式文本。在诸如上下文图像检索和多模态对话等 grounded 任务上取得了强大的零样本性能,并展示了引人注目的交互能力。该方法适用于任意现有的语言模型,并为在视觉 grounded 设置中利用预训练的语言模型的有效、通用解决方案铺平了道路。
We propose an efficient method to ground pretrained text-only language models to the visual domain, enabling them to process and generate arbitrarily interleaved image-and-text data. Our method leverages the abilities of language models learnt from large scale text-only pretraining, such as in-context learning and free-form text generation. We keep the language model frozen, and finetune input and output linear layers to enable cross-modality interactions. This allows our model to process arbitrarily interleaved image-and-text inputs, and generate free-form text interleaved with retrieved images. We achieve strong zero-shot performance on grounded tasks such as contextual image retrieval and multimodal dialogue, and showcase compelling interactive abilities. Our approach works with any off-the-shelf language model and paves the way towards an effective, general solution for leveraging pretrained language models in visually grounded settings.
论文链接:https://arxiv.org/abs/2301.13823


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢