
来自Google Core ML组的工作。对开源的大模型的指令调优方法进行了评测,结果Flan-T5性能最优:
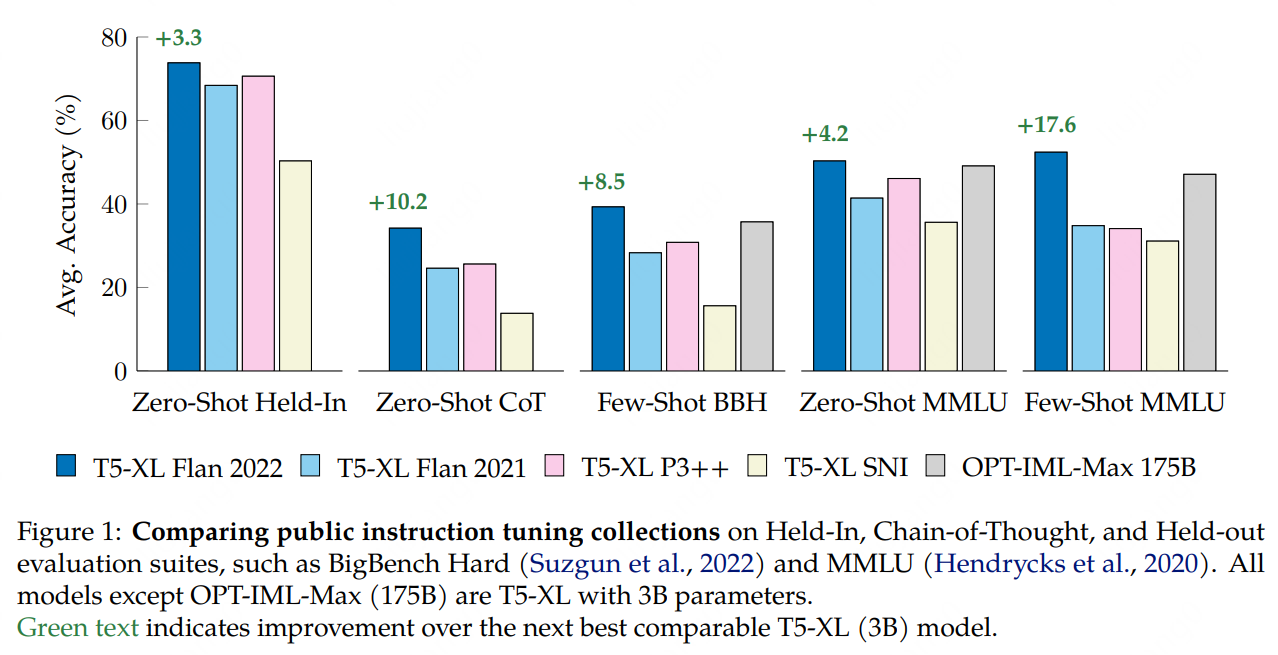
Flan-T5 3B > T0++ 3B> OPT-IML 175B > GLM-130B > Flan 2021 3B > NIv2 3B
一作是Shayne Longpre,MIT在读博士。他在Twitter上的主题帖有很多信息:
https://twitter.com/ShayneRedford/status/1620805305801261058
作者中还包括Le Hou、Yi Tay、Quoc V. Le、Barret Zoph、Jason Wei等熟悉的名字。
论文:The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
arxiv: https://arxiv.org/abs/2301.13688
所用方法、数据已开源: https://github.com/google-research/FLAN/tree/main/flan/v2
摘要
We study the design decisions of publicly available instruction tuning methods, and break down the development of Flan 2022 (Chung et al., 2022). Through careful ablation studies on the Flan Collection of tasks and methods, we tease apart the effect of design decisions which enable Flan-T5 to outperform prior work by 3-17%+ across evaluation settings. We find task balancing and enrichment techniques are overlooked but critical to effective instruction tuning, and in particular, training with mixed prompt settings (zero-shot, few-shot, and chain-of-thought) actually yields stronger (2%+) performance in all settings. In further experiments, we show Flan-T5 requires less finetuning to converge higher and faster than T5 on single downstream tasks, motivating instruction-tuned models as more computationally-efficient starting checkpoints for new tasks. Finally, to accelerate research on instruction tuning, we make the Flan 2022 collection of datasets, templates, and methods publicly available at this https URL.
我们研究了已公开的指令调优方法的设计决策,并仔细分析了 Flan 2022 (Chung et al., 2022) 的开发。 通过对 Flan 任务和方法的仔细消融研究,我们梳理了设计决策的影响,这些决策使 Flan-T5 在评估设置中比之前的工作高出 3%-17%+。我们发现任务平衡和丰富技术被忽视了,但对于有效的指令调整至关重要,特别是混合提示设置(零样本、少量样本和思维链)的训练实际上在所有设置中获得了更强的 (2%+) 性能。 在进一步的实验中,我们表明 Flan-T5 在单个下游任务上比 T5 需要更少的微调来收敛得更高更快,从而激励指令调优模型作为新任务的计算效率更高的起始检查点。 最后,为了加速对指令调优的研究,我们在这个网址上公开了 Flan 2022 数据集、模板和方法的集合。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢