
来自今天的爱可可AI前沿推介
[LG] Deep Power Laws for Hyperparameter Optimization
A Kadra, M Janowski, M Wistuba, J Grabocka
[University of Freiburg & Amazon Web Services]
基于深度幂律的超参数优化
要点:
-
提出一种基于深度幂律函数集成的新的灰盒超参数优化的概率代用方法; -
一种简单的机制,将代用指标与贝叶斯优化结合起来; -
通过一组大规模的超参数优化实验,证明了该方法与当前最先进的深度学习超参数优化相比的经验优势。
一句话总结:
提出深度幂律(DPL),深度学习灰盒超参数优化的一种新的概率代用方法,采用幂律函数集成和贝叶斯优化,性能优于目前最先进的方法。
摘要:
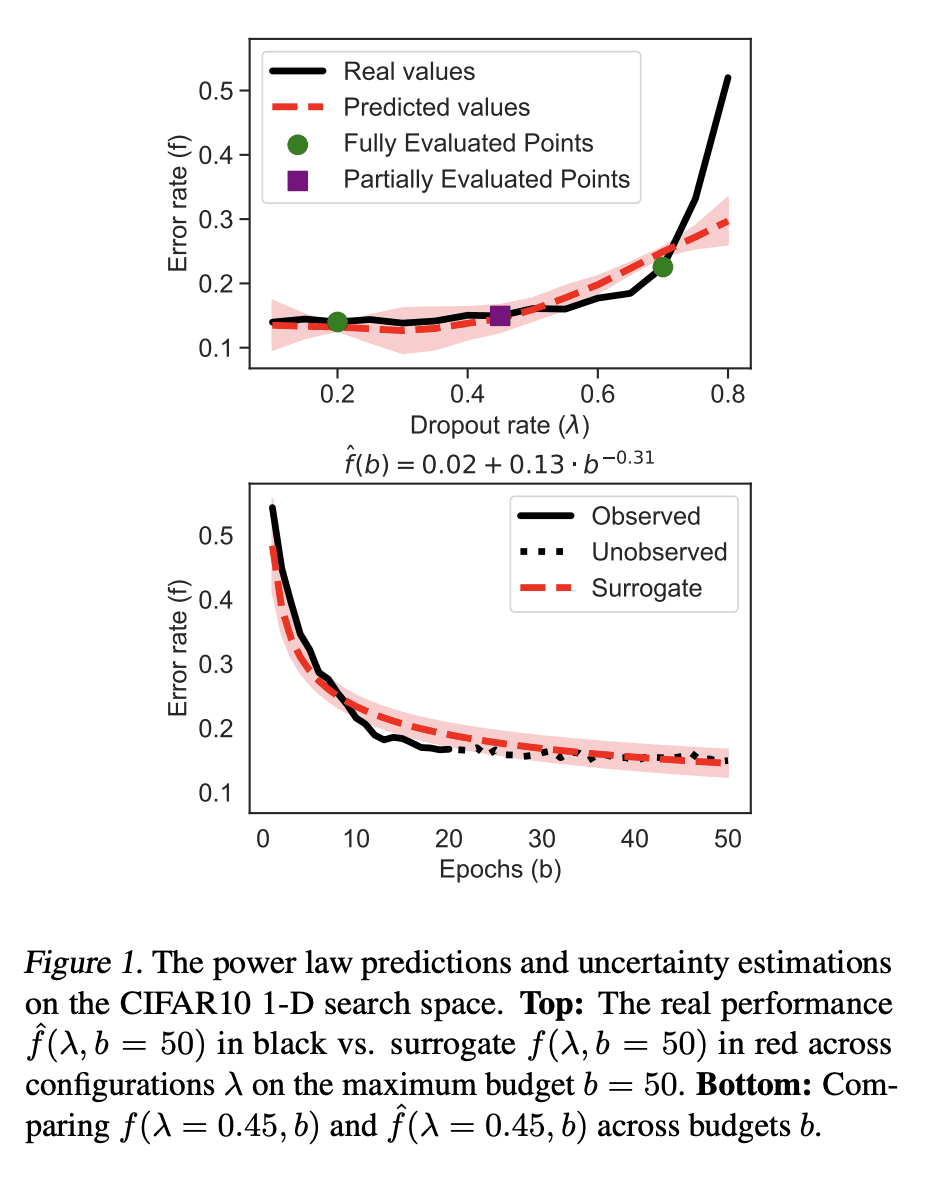
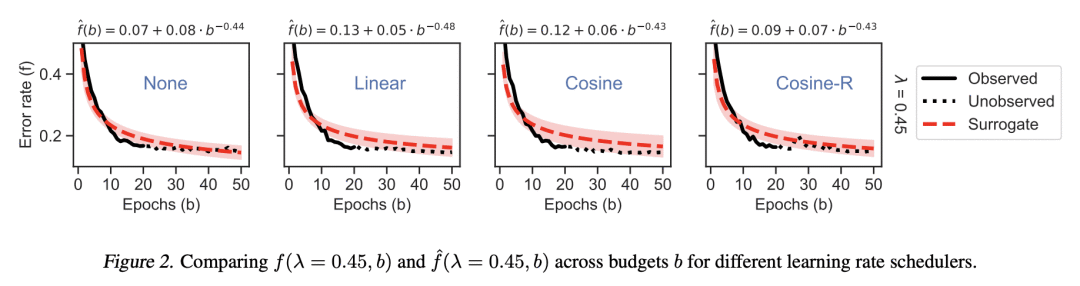
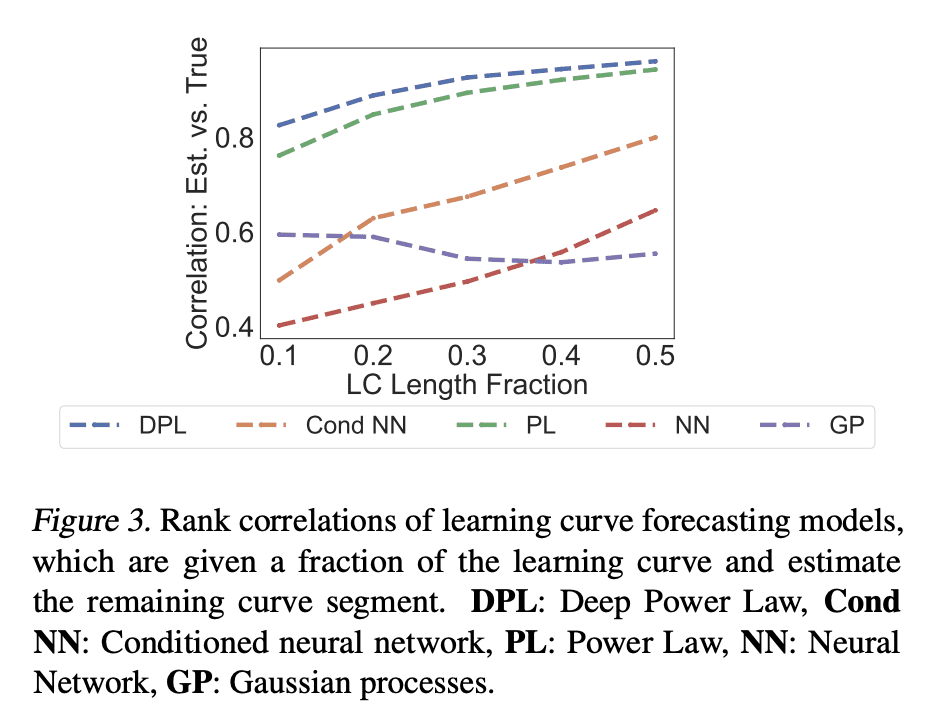
超参数优化是机器学习的一个重要子领域,侧重于调整所选算法的超参数以达到峰值性能。最近,解决超参数优化问题的方法层出不穷,然而,大多数方法没有利用学习曲线的缩放律特性。本文提出深度幂律(DPL),一种神经网络模型集成,其条件是产生遵循幂律扩展模式的预测。通过利用灰盒评估,动态地决定哪些配置需要暂停和增量训练。将该方法与7个最先进的竞争方法在3个与表格、图像和NLP数据集有关的基准上进行了比较,涵盖了57个不同的任务。与所有竞争方法相比,所提出方法通过获得最佳的任意时刻结果,在所有基准中取得了最好的结果。
Hyperparameter optimization is an important subfield of machine learning that focuses on tuning the hyperparameters of a chosen algorithm to achieve peak performance. Recently, there has been a stream of methods that tackle the issue of hyperparameter optimization, however, most of the methods do not exploit the scaling law property of learning curves. In this work, we propose Deep Power Laws (DPL), an ensemble of neural network models conditioned to yield predictions that follow a power-law scaling pattern. Our method dynamically decides which configurations to pause and train incrementally by making use of gray-box evaluations. We compare our method against 7 state-of-the-art competitors on 3 benchmarks related to tabular, image, and NLP datasets covering 57 diverse tasks. Our method achieves the best results across all benchmarks by obtaining the best any-time results compared to all competitors.
论文链接:https://arxiv.org/abs/2302.00441
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢