
来自今天的爱可可AI前沿推介
[LG] Debiasing Vision-Language Models via Biased Prompts
C Chuang, V Jampani, Y Li, A Torralba, S Jegelka
[MIT CSAIL & Google Research]
通过有偏提示纠偏视觉-语言模型
要点:
-
提出一种简单通用的方法,通过在文本嵌入中投影出有偏差的方向来对视觉-语言模型进行纠偏; -
不需要额外的训练、数据或标签,使得它在计算上对基础模型的使用非常有效; -
闭式解可以轻松地集成到大规模管道中。
一句话总结:
提出一种简单而通用的视觉-语言模型去偏的方法,通过在文本嵌入中投影出有偏的方向来消除偏差,计算效率高,不需要额外的训练、数据或标签。
摘要:
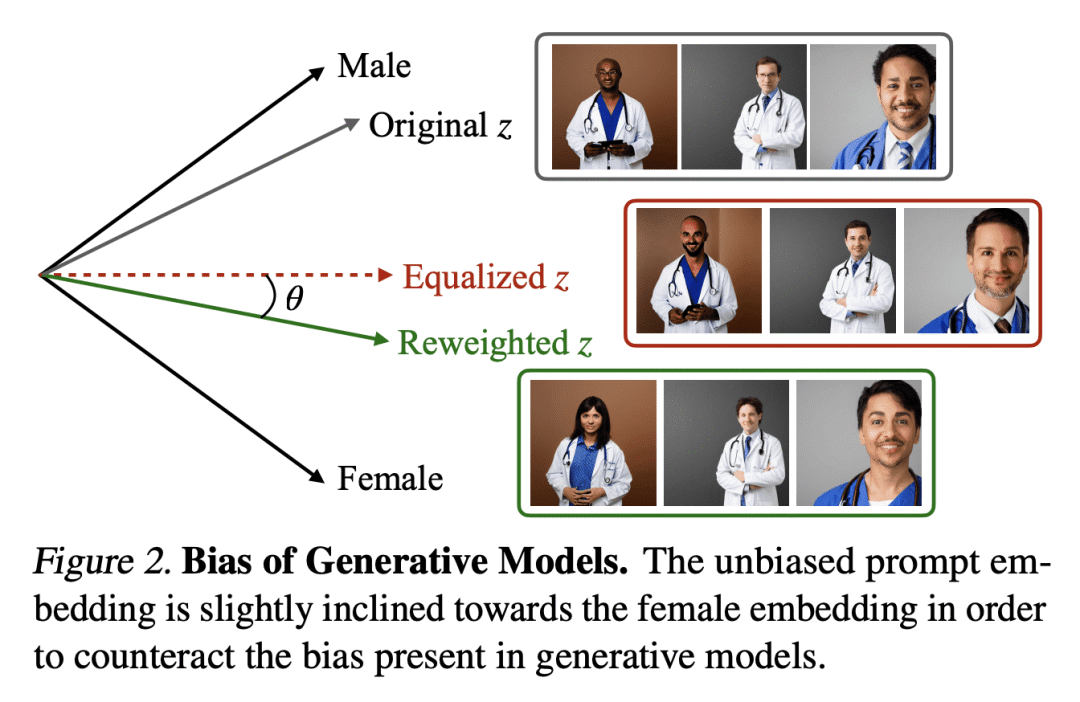
机器学习模型已被证明会从其训练数据集中继承偏差,这对于在从互联网上爬取的未经整理的数据集上训练的视觉-语言基础模型来说,可能特别有问题。这些偏差可以被放大并传播到下游应用中,如零样本分类器和文本到图像生成模型。本文提出一种通用的方法,通过投影分解出文本嵌入中的偏差来消除视觉语言基础模型的偏差。特别是,只用一个校准的投影矩阵对文本嵌入进行去偏,就足以产生鲁棒的分类器和公平的生成模型。闭式解可以很容易地集成到大规模的管道中,实证结果表明,所提出方法可以有效地减少鉴别性和生成性视觉语言模型的社会偏差和虚假相关性,而不需要额外的数据或训练。
Machine learning models have been shown to inherit biases from their training datasets, which can be particularly problematic for vision-language foundation models trained on uncurated datasets scraped from the internet. The biases can be amplified and propagated to downstream applications like zero-shot classifiers and text-to-image generative models. In this study, we propose a general approach for debiasing vision-language foundation models by projecting out biased directions in the text embedding. In particular, we show that debiasing only the text embedding with a calibrated projection matrix suffices to yield robust classifiers and fair generative models. The closed-form solution enables easy integration into large-scale pipelines, and empirical results demonstrate that our approach effectively reduces social bias and spurious correlation in both discriminative and generative vision-language models without the need for additional data or training.
论文链接:https://arxiv.org/abs/2302.00070


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢