
来自今天的爱可可AI前沿推介
[LG] Language Quantized AutoEncoders: Towards Unsupervised Text-Image Alignment
H Liu, W Yan, P Abbeel
[UC Berkeley]
语言量化自编码器:无监督文本图像对齐研究
要点:
-
提出了 LQAE,一种用预训练语言模型将图像与未对齐的文本-图像对对齐的方法; -
允许通过标准提示,用大型语言模型进行少少样本图像的分类,而不需要进行任何微调; -
允许使用BERT进行图像线性分类。
一句话总结:
LQAE 用预训练语言模型(如BERT)将图像与没有文本-图像对的文本 token 对齐,实现了用大型语言模型进行少样本图像分类和用BERT文本特征对图像进行线性分类。
摘要:
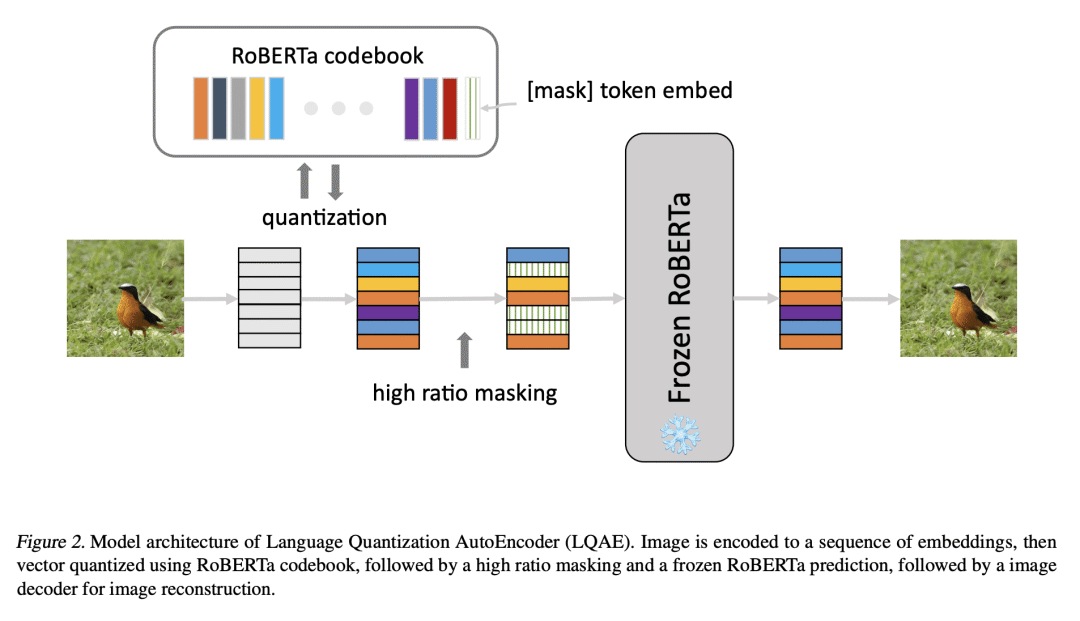
最近在扩展大型语言模型方面的进展,显示了在广泛的基于文本的任务中进行少样本学习的惊人能力。然而,一个关键的限制是,这些语言模型从根本上缺乏视觉感知——这是扩展这些模型以便能与现实世界互动和解决视觉任务所需要的关键属性,例如在视觉问答和机器人方面。之前的工作主要是通过预训练和/或在策划的图像-文本数据集上进行微调,将图像与文本连接起来,这可能是一个昂贵的过程。为解决这一局限性,本文提出一种简单而有效的方法,语言量化自编码器(LQAE),这是VQ-VAE的一种修改,通过用预训练语言模型(如BERT、RoBERTa),以无监督方式学习文本-图像数据对齐。其主要想法是通过用预训练的语言码本直接量化图像嵌入,将图像编码为文本token的序列。在BERT模型之后应用随机掩码,让解码器从 BERT 预测的文本 token 嵌入中重建原始图像。这样,LQAE 学会了用相似的文本 token 簇来表示相似的图像,从而在不使用对齐文本-图像对的情况下将这两种模式对齐。这使得用大型语言模型(如GPT-3)进行少样本图像分类,以及基于BERT文本特征的图像线性分类成为可能。本文工作是第一项通过利用预训练的语言模型的力量将未对齐的图像用于多模态任务的工作。
Recent progress in scaling up large language models has shown impressive capabilities in performing few-shot learning across a wide range of text-based tasks. However, a key limitation is that these language models fundamentally lack visual perception - a crucial attribute needed to extend these models to be able to interact with the real world and solve vision tasks, such as in visual-question answering and robotics. Prior works have largely connected image to text through pretraining and/or fine-tuning on curated image-text datasets, which can be a costly and expensive process. In order to resolve this limitation, we propose a simple yet effective approach called Language-Quantized AutoEncoder (LQAE), a modification of VQ-VAE that learns to align text-image data in an unsupervised manner by leveraging pretrained language models (e.g., BERT, RoBERTa). Our main idea is to encode image as sequences of text tokens by directly quantizing image embeddings using a pretrained language codebook. We then apply random masking followed by a BERT model, and have the decoder reconstruct the original image from BERT predicted text token embeddings. By doing so, LQAE learns to represent similar images with similar clusters of text tokens, thereby aligning these two modalities without the use of aligned text-image pairs. This enables few-shot image classification with large language models (e.g., GPT-3) as well as linear classification of images based on BERT text features. To the best of our knowledge, our work is the first work that uses unaligned images for multimodal tasks by leveraging the power of pretrained language models.
论文链接:https://arxiv.org/abs/2302.00902

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢