
来自今天的爱可可AI前沿推介
[CV] Dreamix: Video Diffusion Models are General Video Editors
E Molad, E Horwitz, D Valevski, A R Acha, Y Matias, Y Pritch, Y Leviathan, Y Hoshen
[Google Research]
Dreamix: 基于视频扩散模型的通用视频编辑器
要点:
-
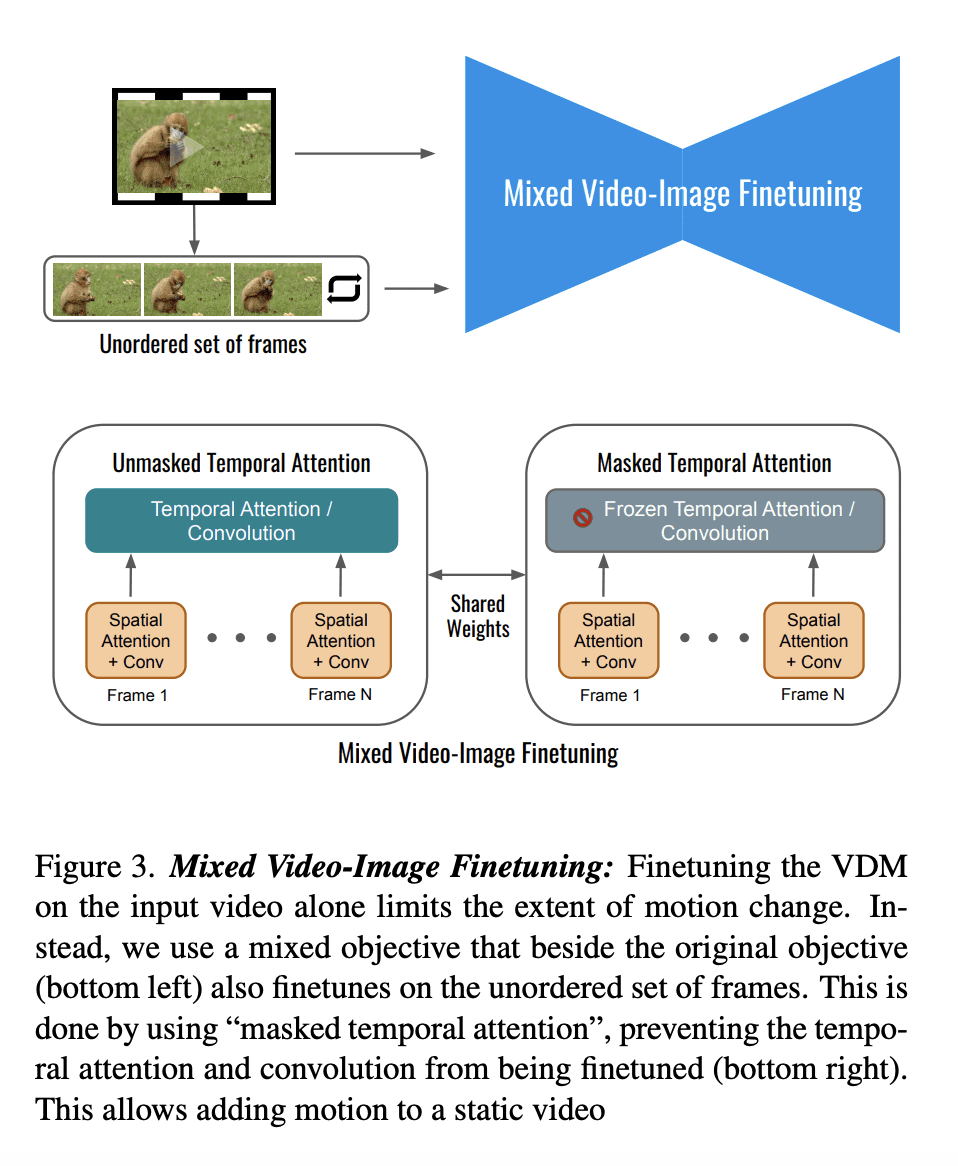
提出第一个基于扩散的方法,用于一般视频的基于文本的运动和外观编辑; -
使用混合微调模型来提高运动编辑的质量; -
通过将简单的图像处理操作与视频编辑方法相结合,为文字引导的图像动画提供了新的框架。
一句话总结:
提出第一个基于扩散的文本视频编辑方法,提高了运动编辑质量,为文本引导的图像动画提供了框架,并演示了使用新型微调方法的主题驱动视频生成。
摘要:
文本驱动的图像和视频扩散模型,最近实现了前所未有的生成真实性。虽然扩散模型已经成功地应用于图像编辑,但很少有作品能在视频编辑中做到这一点。本文提出第一个基于扩散的方法,能够对一般视频进行基于文本的运动和外观编辑。该方法使用视频扩散模型,在推理时将原始视频中的低分辨率时空信息与新的高分辨率信息结合起来,这些信息是由它合成的,与指导性文本提示一致。由于获得原始视频的高保真度需要保留一些高分辨率的信息,在原始视频上增加了一个模型微调的初步阶段,大大提升了保真度。本文提出通过一个新的、混合的目标来提高运动的可编辑性,这个目标是通过完全的基于时间注意力掩码的时间注意力来联合微调。本文进一步介绍了一个新的图像动画框架。首先通过简单的图像处理操作,如复制和透视几何投影,将图像转化为粗略的视频,然后使用所提出的通用视频编辑器来制作动画。作为进一步的应用,可以将该方法用于主题驱动的视频生成。广泛的定性和数值实验展示了所提出方法显著的编辑能力,并确立了它与基线方法相比的卓越性能。
Text-driven image and video diffusion models have recently achieved unprecedented generation realism. While diffusion models have been successfully applied for image editing, very few works have done so for video editing. We present the first diffusion-based method that is able to perform text-based motion and appearance editing of general videos. Our approach uses a video diffusion model to combine, at inference time, the low-resolution spatio-temporal information from the original video with new, high resolution information that it synthesized to align with the guiding text prompt. As obtaining high-fidelity to the original video requires retaining some of its high-resolution information, we add a preliminary stage of finetuning the model on the original video, significantly boosting fidelity. We propose to improve motion editability by a new, mixed objective that jointly finetunes with full temporal attention and with temporal attention masking. We further introduce a new framework for image animation. We first transform the image into a coarse video by simple image processing operations such as replication and perspective geometric projections, and then use our general video editor to animate it. As a further application, we can use our method for subject-driven video generation. Extensive qualitative and numerical experiments showcase the remarkable editing ability of our method and establish its superior performance compared to baseline methods.
论文链接:https://arxiv.org/abs/2302.01329


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢