
来自今天的爱可可AI前沿推介
[CL] Accelerating Large Language Model Decoding with Speculative Sampling
C Chen, S Borgeaud, G Irving, J Lespiau, L Sifre, J Jumper
[DeepMind]
用投机采样加速大型语言模型解码
要点:
-
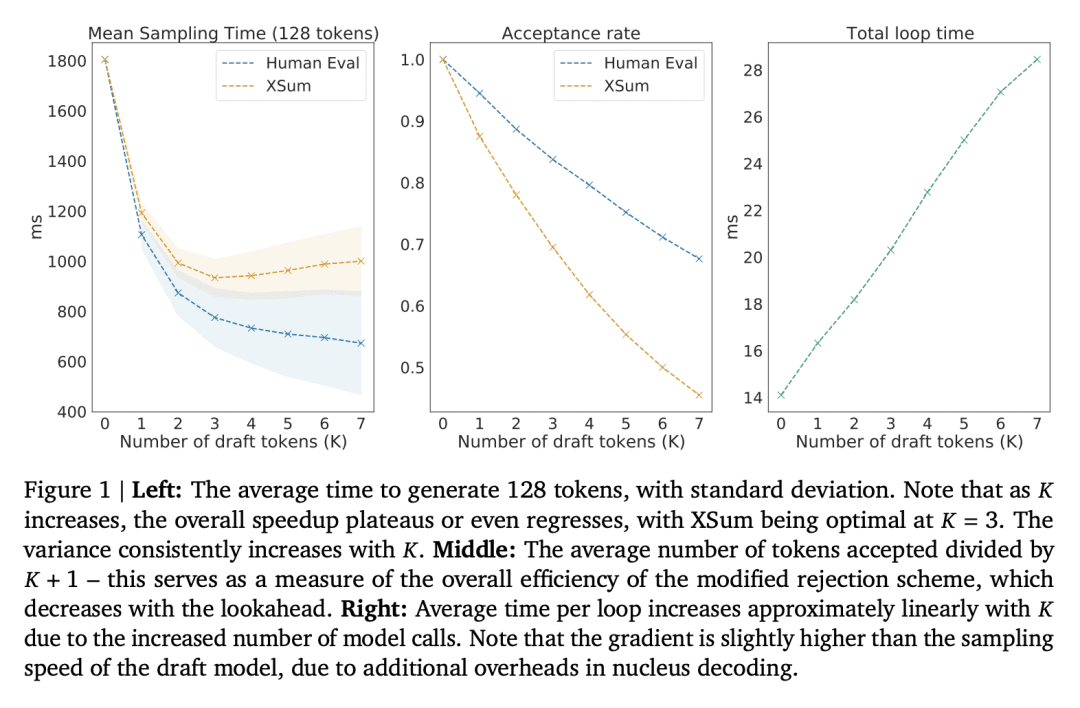
提出一种叫做投机采样的新算法,在不影响样本质量的情况下加快了 Transformer 解码的速度; -
从每个 Transformer 调用产生多个token,使用由草案模型产生的短连续的并行评分; -
采用修改过的拒绝采样方案被来保留目标模型在硬件数值中的分布。
一句话总结:
提出投机取样,一种通过从每个 Transformer 调用中生成多个令牌来加速 Transformer 解码的算法,在不影响采样质量或修改目标模型的情况下实现了2-2.5倍的速度。
We present speculative sampling, an algorithm for accelerating transformer decoding by enabling the generation of multiple tokens from each transformer call. Our algorithm relies on the observation that the latency of parallel scoring of short continuations, generated by a faster but less powerful draft model, is comparable to that of sampling a single token from the larger target model. This is combined with a novel modified rejection sampling scheme which preserves the distribution of the target model within hardware numerics. We benchmark speculative sampling with Chinchilla, a 70 billion parameter language model, achieving a 2-2.5x decoding speedup in a distributed setup, without compromising the sample quality or making modifications to the model itself.
论文链接:https://arxiv.org/abs/2302.01318
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢