
近期,微软亚洲研究院从深度学习基础理论出发,研发并推出了 TorchScale 开源工具包。TorchScale 工具包通过采用 DeepNet、Magneto 和 X-MoE 等最先进的建模技术,可以帮助研究和开发人员提高建模的通用性和整体性能,确保训练模型的稳定性及效率,并允许以不同的模型大小扩展 Transformer 网络。
如今,在包括自然语言处理(NLP)、计算机视觉(CV)、语音、多模态模型和 AI for Science 等领域研究中,Transformer 已经成为一种通用网络结构,加速了 AI 模型的大一统。与此同时,越来越多的实践证明大模型不仅在广泛的任务中能产生更好的结果、拥有更强的泛化性,还可以提升模型的训练效率,甚至衍生出新的能力。因此,学术界和产业界都开始追求更大规模的模型。
然而随着模型的不断扩大,其训练过程也变得更加困难,比如会出现训练不收敛等问题。这就需要大量的手动调参工作来解决,而这不仅会造成资源浪费,还会产生不可预估的计算成本。
与其扬汤止沸,不如釜底抽薪。微软亚洲研究院从深度学习基础理论出发,创新推出了 TorchScale 工具包,并已将其开源。TorchScale 是一个 PyTorch 库,允许科研和开发人员更高效地训练 Transformer 大模型。同时,它有效地提升了建模的性能和通用性,提高了 Transformer 的稳定性和训练效率。
TorchScale GitHub 页面:
https://github.com/microsoft/torchscale
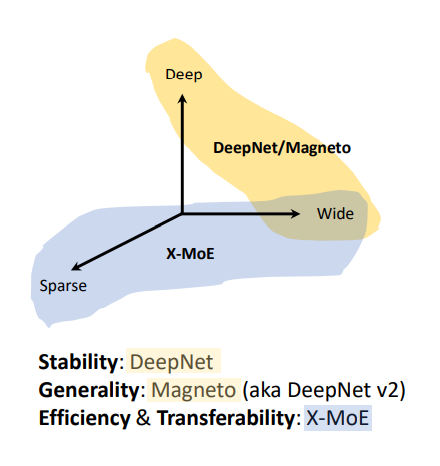
“我们希望通过 TorchScale 的系列工作从更底层出发做一些基础性的研究创新,通过数学或者理论上的指导和启发,在 Transformer 模型扩展的工作中取得更好的效果,而不是单纯的调参或仅从工程层面去部分缓解某些问题。TorchScale 能够支持任意的网络深度和宽度,实验验证它可以轻松扩大模型规模,而且只需要几行代码就能够实现多模态模型的训练。”微软亚洲研究院自然语言计算组首席研究员韦福如表示。
TorchScale 主要从三个方面帮助科研人员克服了扩展 Transformer 大模型时的困难:
-
DeepNet:提升模型的稳定性。
-
Magneto:提升模型的通用性。
-
X-MoE:提升模型训练的高效性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢