
2023 年 1 月 21 日,人工智能顶级会议 ICLR 2023(International Conference on Learning Representations)投稿结果正式公布。上海人工智能实验室自动驾驶 OpenDriveLab 团队成果 —— 基于自监督几何建模的自动驾驶策略预训练方法(PPGeo)被正式录用。PPGeo 是一个基于几何建模的自监督预训练框架,利用大量无标注网络驾驶视频,以自监督的方式对驾驶策略进行预训练,将会显著提升下游端到端感知决策任务的性能。

论文地址:https://arxiv.org/abs/2301.01006
项目地址:https://github.com/OpenDriveLab/PPGeo
驾驶策略学习的特殊性
自动驾驶领域中的端到端驾驶策略学习将原始传感器数据(图片,车身信号,点云等)作为输入,直接预测控制信号或规划路线。由于驾驶环境的复杂性和不确定性以及传感器数据中的大量无关信息,对于端到端的驾驶策略模型,从头开始学习是很困难的,它通常需要大量的标注数据或环境交互反馈才能达到令人满意的性能。
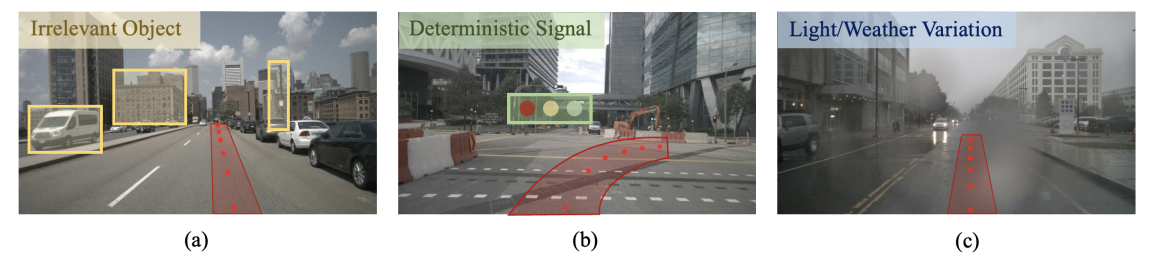
如图 1 所示,自然环境中存在着许多不需要关注的信息如建筑物、天气变化以及光照变化等,于驾驶任务而言,下一步往哪里行驶,信号灯是否允许通行,这些信息才是真正需要关注的。
-
(a) 静态障碍物和背景建筑物(黄色矩形中的物体)与驾驶决策无关;
-
(b) 视觉输入中的交通信号(标有绿色框)仅占图片的很小一部分,但对于控制输出而言却是确定性的;
-
(c) 端到端驾驶策略模型必须对不同的光照和天气条件具有鲁棒性。
当前预训练方法在策略学习任务中的限制
为解决端到端的驾驶策略模型对于大规模标注数据的需求,采用无标注的驾驶视频 (如图 2)数据对驾驶策略模型的感知部分进行预训练是很自然的思路,因此获得了非常广泛有效的应用,主流的预训练方法包括分类,对比学习,掩码图像建模。然而,不同于常见的检测和分割任务,端到端驾驶策略学习对自车的位姿敏感,缺乏平移或视角不变性。这也使得常见视觉任务预训练的常胜将军们,在端到端驾驶策略学习任务上败下阵来。由于上文提到的端到端驾驶任务输入的特殊性,其他机器人领域的视觉控制任务使用的预训练方法在这里也表现相对有限。

对此,OpenDriveLab 团队提出一个基于自监督几何建模的端到端自动驾驶策略预训练方法(PPGeo)。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢