

论文链接:
https://arxiv.org/abs/2210.06742
PyTorch代码:
https://github.com/yangxue0827/h2rbox-mmrotate
https://github.com/open-mmlab/mmrotate/tree/1.x/configs/h2rbox
Jittor代码:
https://github.com/Jittor/JDet/tree/master/projects/h2rbox
https://github.com/yangxue0827/h2rbox-jittor
导读
相比通用目标检测(水平框检测),旋转检测的研究兴起较晚。以我熟悉的遥感图像旋转检测为例(场景文字相关的旋转检测出现地更早),我是在17年末(国科大研二才进实验室)开始做旋转舰船检测的,当时几乎还找不到相关的研究,大部分还是水平框检测算法(如Faster RCNN、SSD等)在遥感图像的应用。旋转框标注的数据集也很少,当时做旋转舰船检测还是举实验室之力标注了一个。
从水平框检测发展到旋转检测的这段时间里,很多数据集以水平框标注的形式发布,如果现在想进一步用于旋转检测,似乎只有重新标注。如果数据集量小还好说,一旦实例数达到十万甚至百万级别,所需要花的人力物力是非常大的。比如,DIOR(19.2w个实例)数据集刚发布的时候是以水平框标注,后来又重新标注了旋转框;SKU110K(173.3w个实例)数据集也是在后来有了一个旋转标注版本。
于是乎,本文想到了这样一个的研究任务:水平框标注的旋转框目标检测。这算是一个弱监督检测任务(也不是很“弱”),就我目前所知好像还没有人做这个事情,算是一个小坑,感兴趣的同学赶紧入坑。如果效果比肩旋转框标注的话,就可以不用重新标注旋转框;即使效果一般般,起码也可以辅助标注旋转框。后来我们查了一下各种标注形式的价格,旋转框每一千个是86刀,比水平框高的63刀高36.5%的价格。
背景
尽管现在没有直接研究水平框标注的旋转检测算法,但是还是有非常相关的研究方向的,也就是基于水平框标注的实例分割,如本文主要对比的BoxInst和BoxLevelSet。只要在后处理阶段对最后预测的掩码取最小外接矩形就可以实现旋转框的检测了,我们在文中记为HBox-Mask-RBox方法,然而这种做法极易受Mask这个中间形态的影响。

图1(a)中飞机的分割往往会把周围的干扰物体(野点、异常点)也分割进去,最后所转换出的来旋转框明显不准。图1(b)中是两个密集排列的场景,这种场景下常常出现把相邻目标区域也分割进来(BoxInst采用的color pair-wise loss会经常出现这个问题),最终导致转化出来的框过大。除了最后的旋转框不准,模型的效率也会严重下降,因为Mask转成RBox这一步骤(最小外接矩形)非常耗时。HBox-Mask-RBox的方法还有一个缺陷是非常耗显存,这和它们所设计的损失函数有关系。下表就是相关参数的对比:
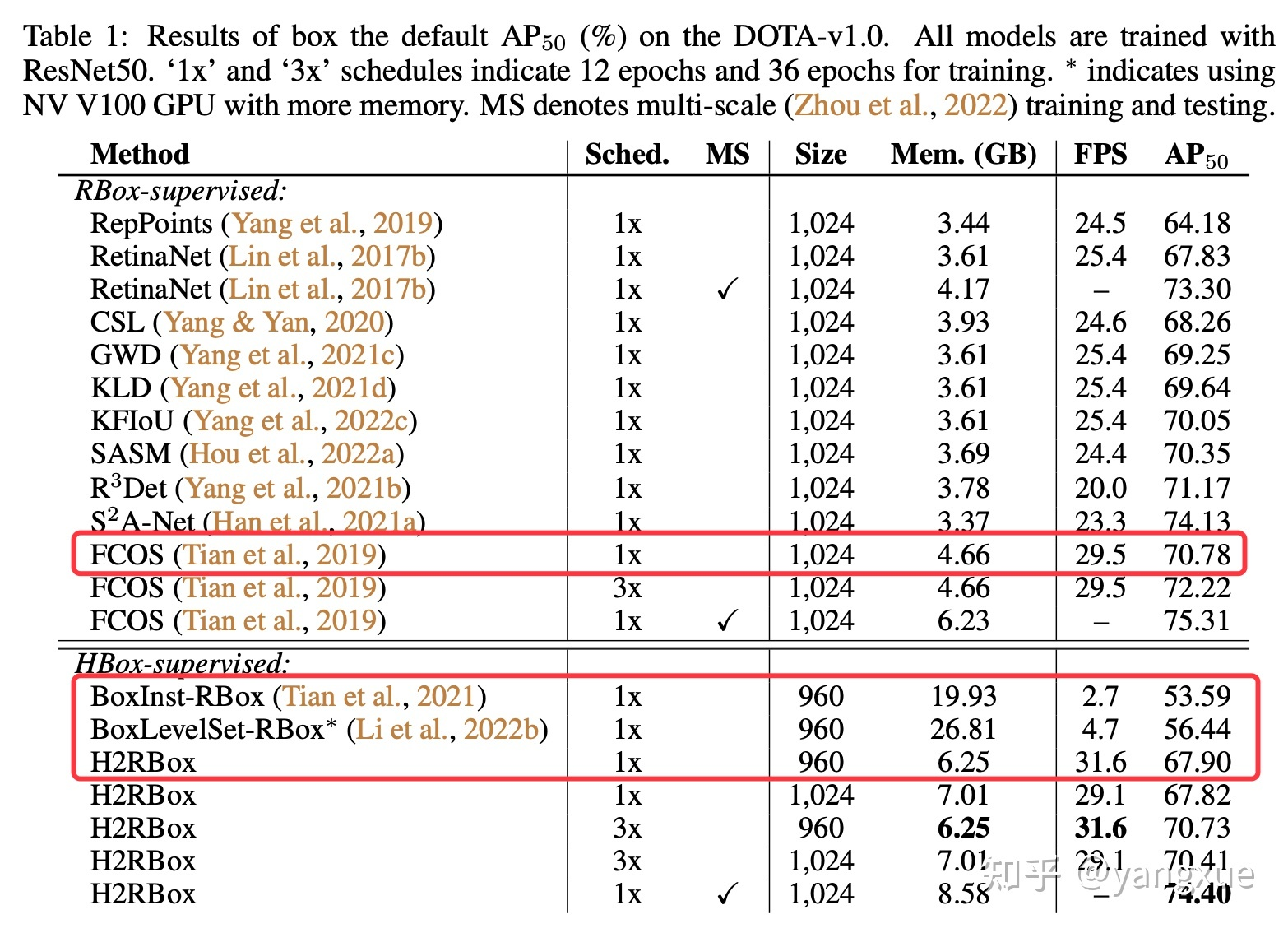
我们也在H2RBox代码中给了基于BoxInst的代码实现,大家亲自体验一下这类方法。这也解释了审稿人经常问我的一个问题:为什么不用实例分割来做旋转检测以及旋转目标检测这个任务存在的意义。对于预测旋转框可以满足要求的任务来说(如舰船检测、汽车检测等),实例分割的做法有点舍近求远了。像素级的表示比旋转矩形维度更高,自然会使得模型预测任务更难(图1就是具体的一些难点),最终导致效果更差了,这还不算实例分割会增加标注的成本。借用章老师(文章二作)的一句来做总结:标旋转框相比正框,价格上虽然略贵,但没有量级上的差异。国内标成本只高20%,国外标成本高40%,且目标类别越多价格差异越小。但标框和标分割,价格就差几倍了。所以旋转框的一个正经落地思路就是分割平替。有些场景标分割太隆重,标正框太粗糙,就正好标旋转框。
回到弱监督旋转目标检测这个正题,HBox-Mask-RBox方法不可行的万恶之源就是Mask这个过渡形态,所以我们提出了从HBox标注直接预测RBox的方法,也就是HBox-to-RBox方法,简称H2RBox。
方法
H2RBox方法既有弱监督也有自监督,先看一下整体的结构图:
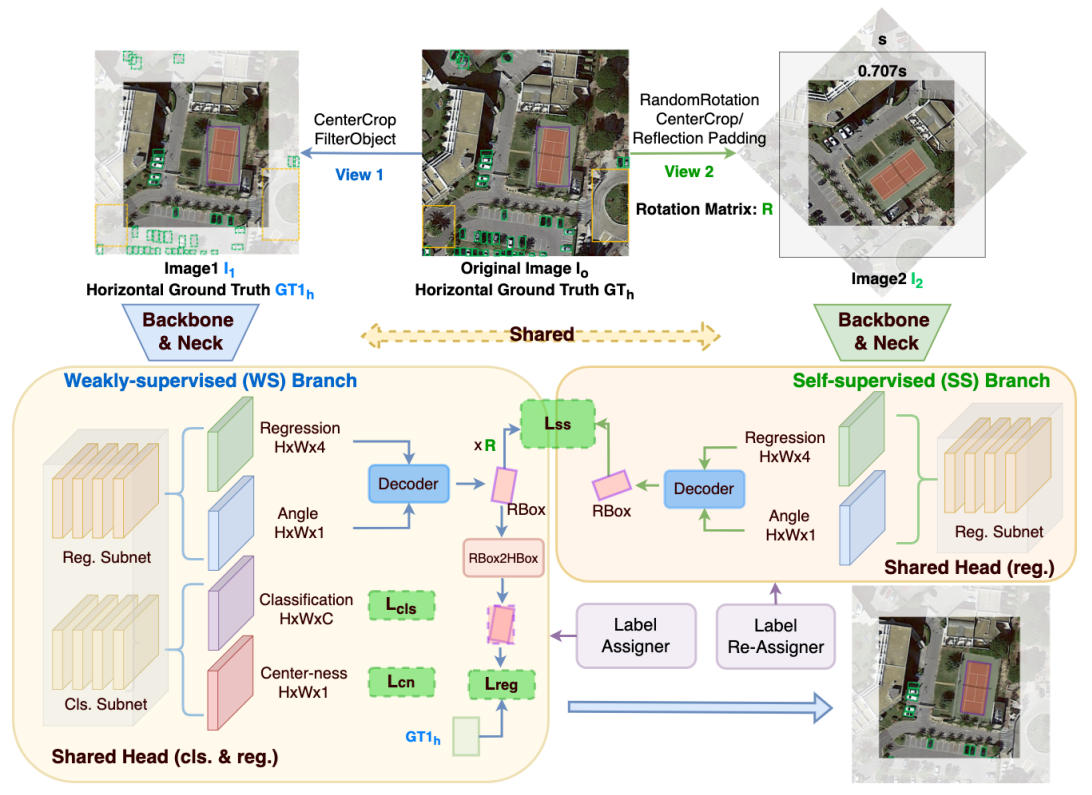
整个方法的结构是经典的双塔结构,左边是弱监督分支,右边是自监督分支,它们共享同一个骨干网络(Backbone)和多尺度特征融合网络(Neck)。
弱监督分支
弱监督分支选用的是FCOS作为基准模型,我们在回归子网络多预测了一个角度参数,因此最终的输出是旋转框。由于我们只有水平标注,因此无法直接使用旋转预测框和水平标注框计算损失。在计算回归损失之前,我们将预测的旋转框转换为其对应的水平外接矩形,然后再通过这些水平外接矩形与水平标注框计算损失。这个做法我们记为水平外接矩约束,这也建立了预测旋转框和未标注的旋转框之间的联系,也就是它们的水平外接矩形是高度重合的。当然这是理想情况,需要考虑到训练的模型预测的水平框不一定准,另外就是有些类别水平标注框不一定就是旋转标注框的水平外接矩形,如下图所示:
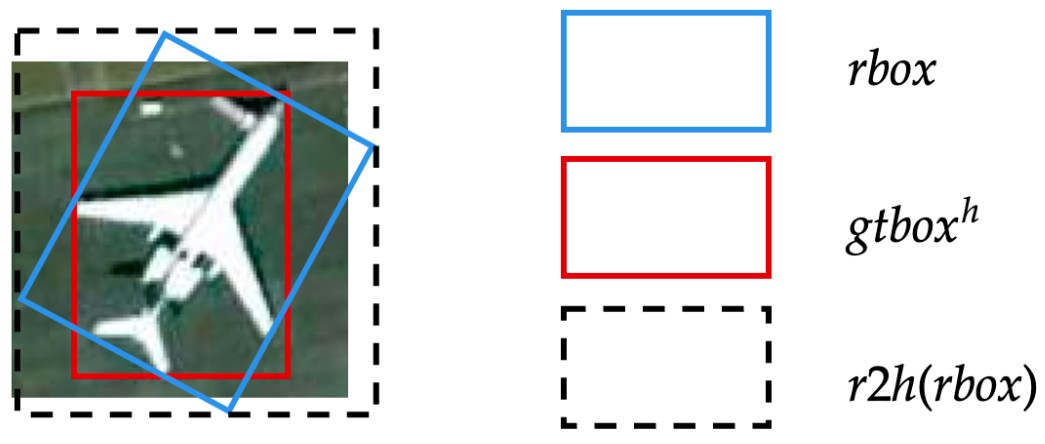
就从结果来看,这些因素可能会影响AP75这种高精度指标,对于AP50这种指标影响不是很大。水平外接矩约束的建立只能将弱监督分支预测的旋转框的可能形态减少,但依然有无数种可行解。为了让该分支预测的旋转框就是正确的那个框,需要增加其他约束来筛选,这也是自监督分支的作用。
自监督分支
自监督分支的输入是原图经过随机角度旋转得到的,旋转中心是图片的中心,旋转矩阵为R。这里需要注意图像旋转后会出现黑边区域而产生信息泄漏,因此文中提供了两种处理方法:
-
中心区域裁剪法(Center Region Cropping)舍弃包含黑边的区域
-
反射填充法(Reflection Padding)来填充黑边区域
从实验结果上来看,反射填充法效果更好,可能原因是这种做法不会降低图像的输入大小。
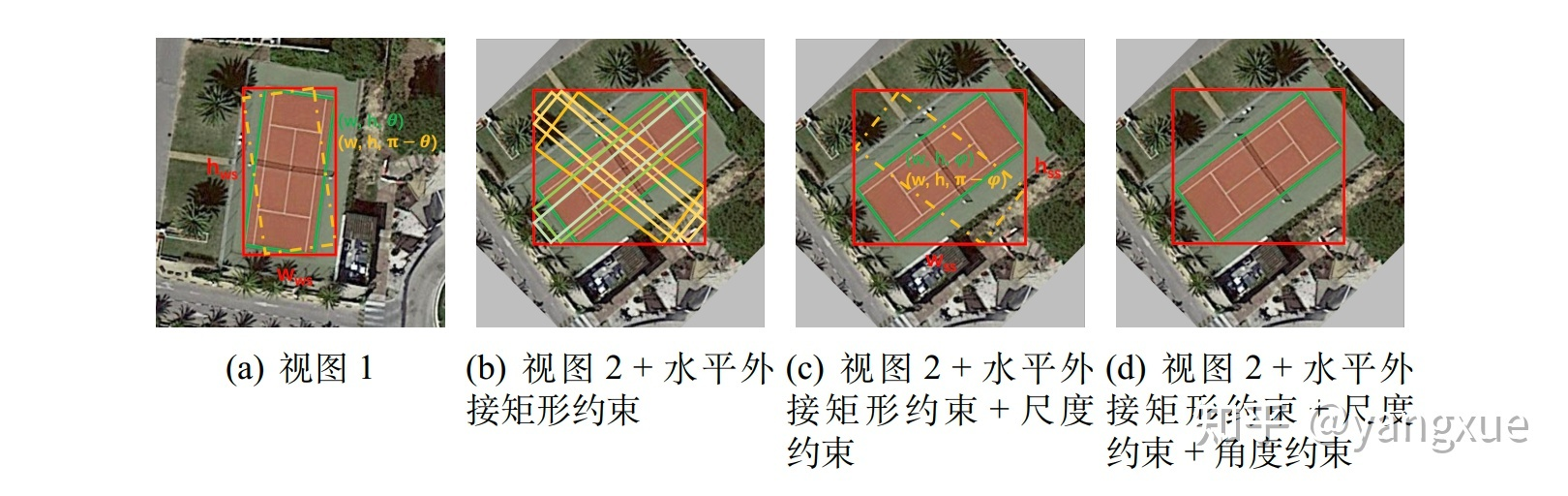
数据预处理完后就会被送入自监督分支,与弱监督分支不同的是该分支只包含回归子网络。自监督分支会输出新视角下的旋转预测框。有这样一个正确命题:对任意的旋转矩阵R,如果两个分支对同一个目标预测的旋转框都是正确的,那么所预测的旋转框之间的空间关系应该和两个输入图像的空间关系一致。通过证明,我们发现这个命题在水平外接矩约束存在的前提下是充分必要的。因此,我们将弱监督分支预测的旋转框做了R矩阵的变换,再计算变换后的旋转框与自监督分支预测的旋转框的一致性损失,也就是图中的 L_{ss} 。L_{ss} 主要包含尺度损失 L_{wh} 、中心点损失 L_{xy} 和角度损失 L_\theta ,主要是为了引入尺度约束和角度约束。到目前为止,已经引入了三种约束,下图描述了三种不同约束是如何引导模型一步步预测出正确的结果。
-
水平外接矩形约束: 从上图(b)可以看出尽管水平外接矩形约束已经减少了许多种错误的预测形式,但是依然还是存在无数种可能得情况,只是这些情况的水平外接矩形满足高度重合的条件;
-
尺度约束: 图(c)展示了这个约束可以将上述说的无数种可能得情况进一步减少到两种,也就是正确的结果和中心对称的结果。可能大家会迷惑 L_{wh} 只是让两个分支对同一目标预测的结果尺度保持一致,但是并不能保证这个尺度就是正确的。这里要稍微补充解释一下,由于自监督分支的输入图像的旋转角度是随机的,那么随着多轮的训练模型就会学习到这样的一个知识,同个目标不管旋转多少度,模型都能输出一个同尺度的旋转框,且这些旋转框的水平外接矩形和对应的水平gt保持高度重合,那么这里的尺度只能是目标的实际尺度才能满足。注意,这里的关键条件是同个目标不管旋转多少度。
-
角度约束: 现在模型距离正确预测结果只差消除中心对称的情况,两个分支的预测结果可能出现的下面四种情况(如下式所示),因此只要告诉模型两个分支预测结果的角度关系和输入图像的角度关系一致(R)就可以了。
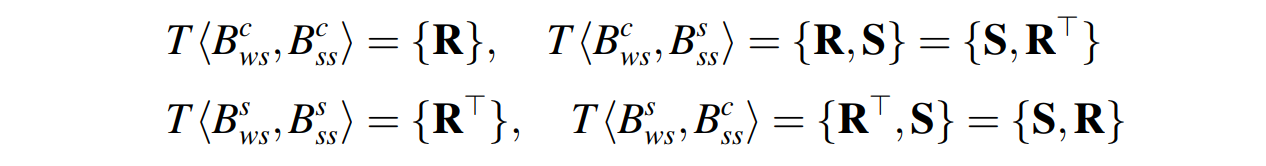
式中 \( B_{ws}^{c} \) 和 \( B_{ss}^{s} \)分别表示弱监督分支所估计的重合边界框和自监督分支估计的中心对称边界框。这里的 S 表示中心对称变换。
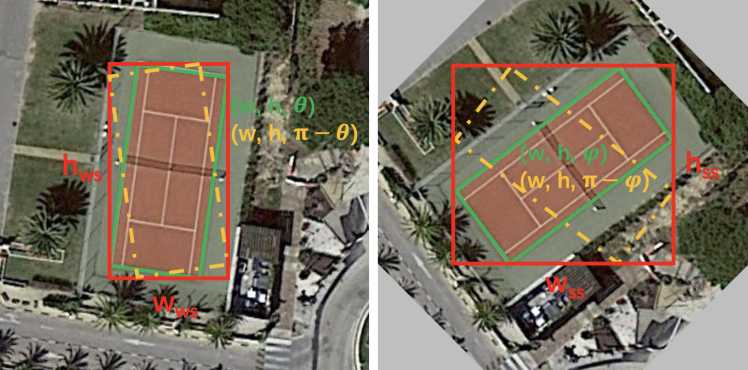
我们根据上述三个约束和上图列出了以下五个方程:
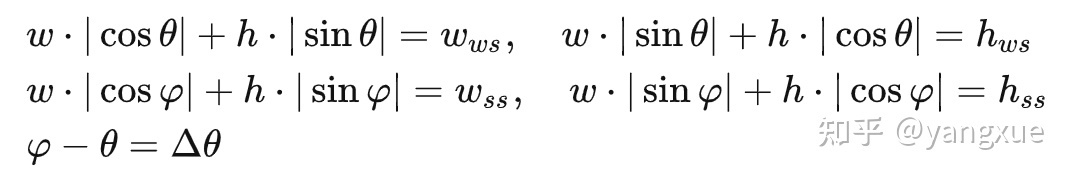
水平外接矩形约束保证 \( w_{w s}, h_{w s}, w_{s s}, h_{s s} \)是已知量。尺度约束使得两个分支预测的尺度相同都是 w, h 。此时只剩下四个末知数 ,在 时,方程组有唯一(因为不是线性方程组,所以我暂时还没法严格证明,求助各位大佬)。已知正确的gt是上述方程组的一个解,那么预测的结果就只能是正确的gt。
损失函数
弱监督分支损失:
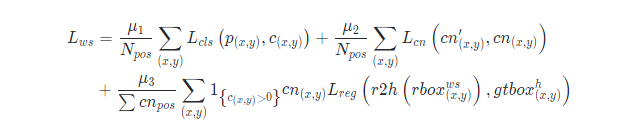
自监督分支损失:
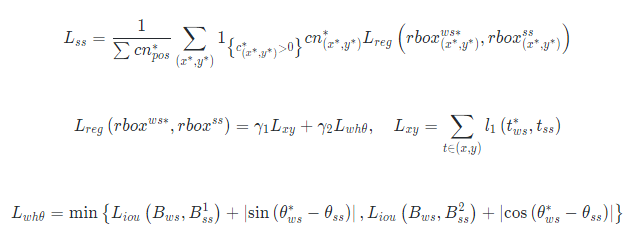
具体细节不过多介绍了,可以看原文对公式的具体说明。这里主要是想强调两点:
-
自监督分支中的中心点损失 L_{xy} 不是必须的,因为弱监督分支中的回归损失已经包含了这部分,因此在实际实验中我们发现 L_{xy} 需要设置一个比较小的权重,大概0-0.15即可;
-
自监督分支的gt是需要通过弱监督分支进行标签再分配得到了,本文最终采用了最简单的一对一空间位置对应关系(R的仿射变换)来进行重分配的,空间关系如下式所示:
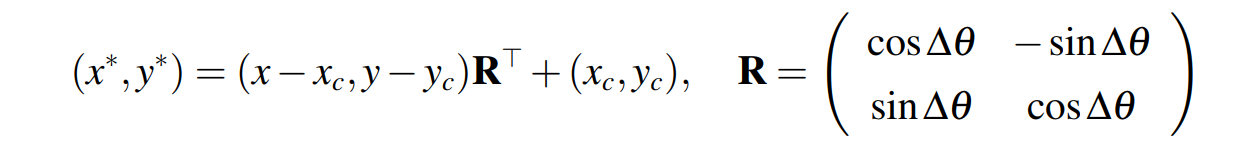
具体就是将弱监督分支位置 (x,y) 上的分配到的标签作为弱监督分支位置 的标签。
实验
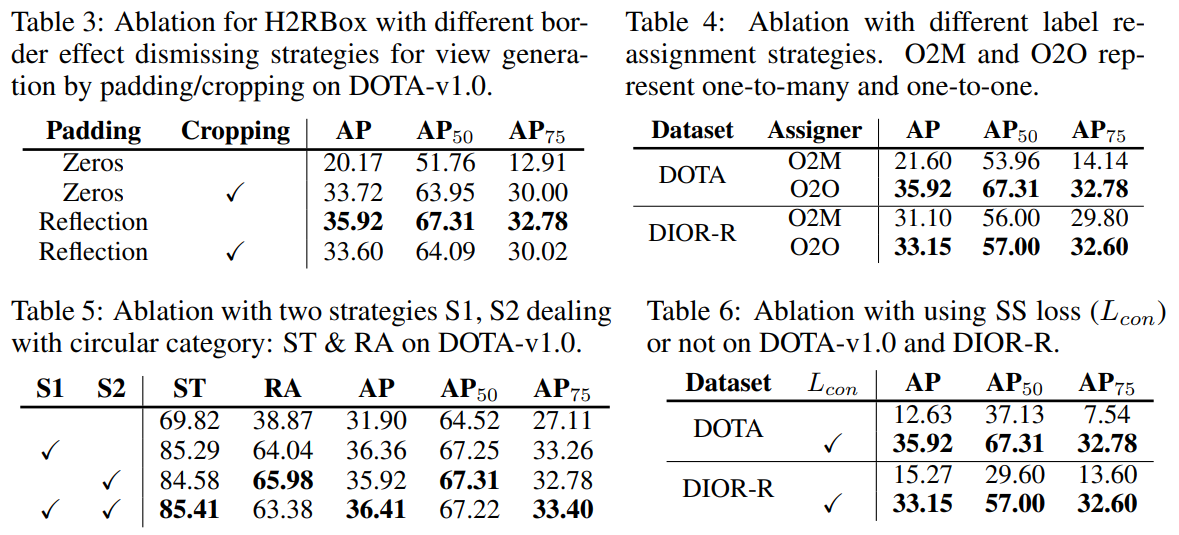
反射填充 (Reflection Padding)比补零填充 (Zeros Padding)效果要好;

一对一的再分配策略 (O2O)优于一对多再分配策略 (O2M);

类正方形需要做特殊处理:策略1 (S1) 为训练时类正方形类别(储油罐ST和环岛RA)不参与 L_\theta 的训练;策略2 (S2) 为测试时直接取类正方形类别预测结果的水平外接矩形作为最后的输出;这两种可以分开使用也可以单独使用,效果均差不多,但是两种共同使用会使训练更加鲁棒易收敛;
一致性损失 L_{ss} 的使用可以消除多余的预测情况,只保留正确的预测情况,显著地提升模型的检测精度。
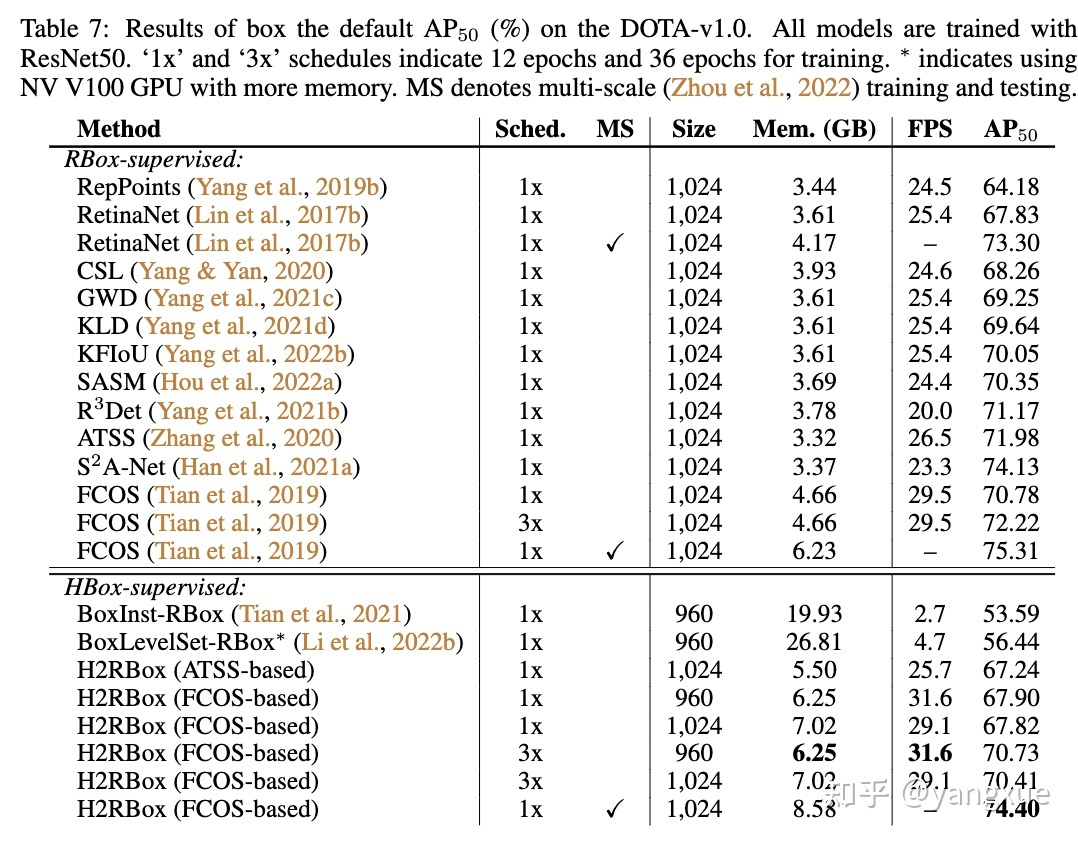
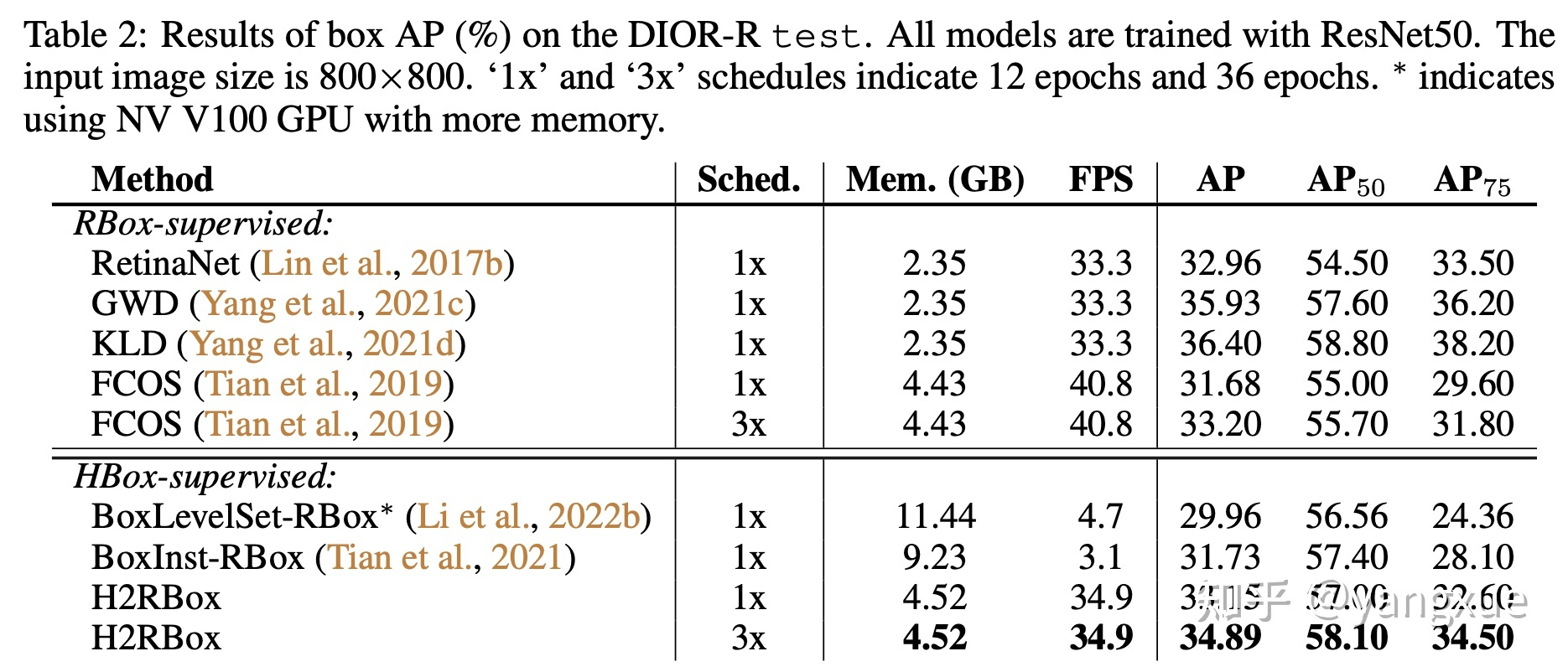
结论:
-
H2RBox不管在精度上还是在速度和存储开销上都远远好于HBox-Mask-RBox范式的工作,如BoxInst-RBox和BoxLevelSet-RBox;
-
对比于RBox监督的方法,H2RBox在各方面比已经做到了比较接近的水平。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢