
【标题】SHIRO: Soft Hierarchical Reinforcement Learning
【作者团队】Kandai Watanabe, Mathew Strong, Omer Eldar
【发表日期】2022.12.24
【论文链接】https://arxiv.org/pdf/2212.12786.pdf
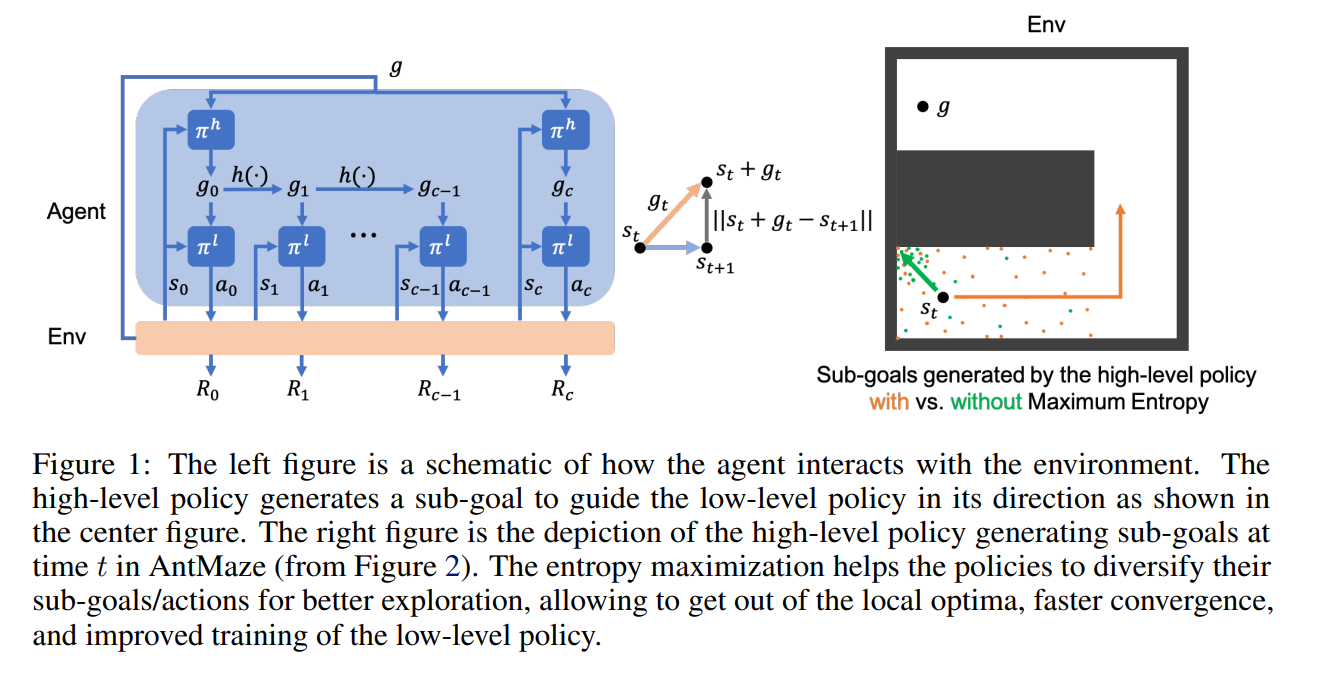
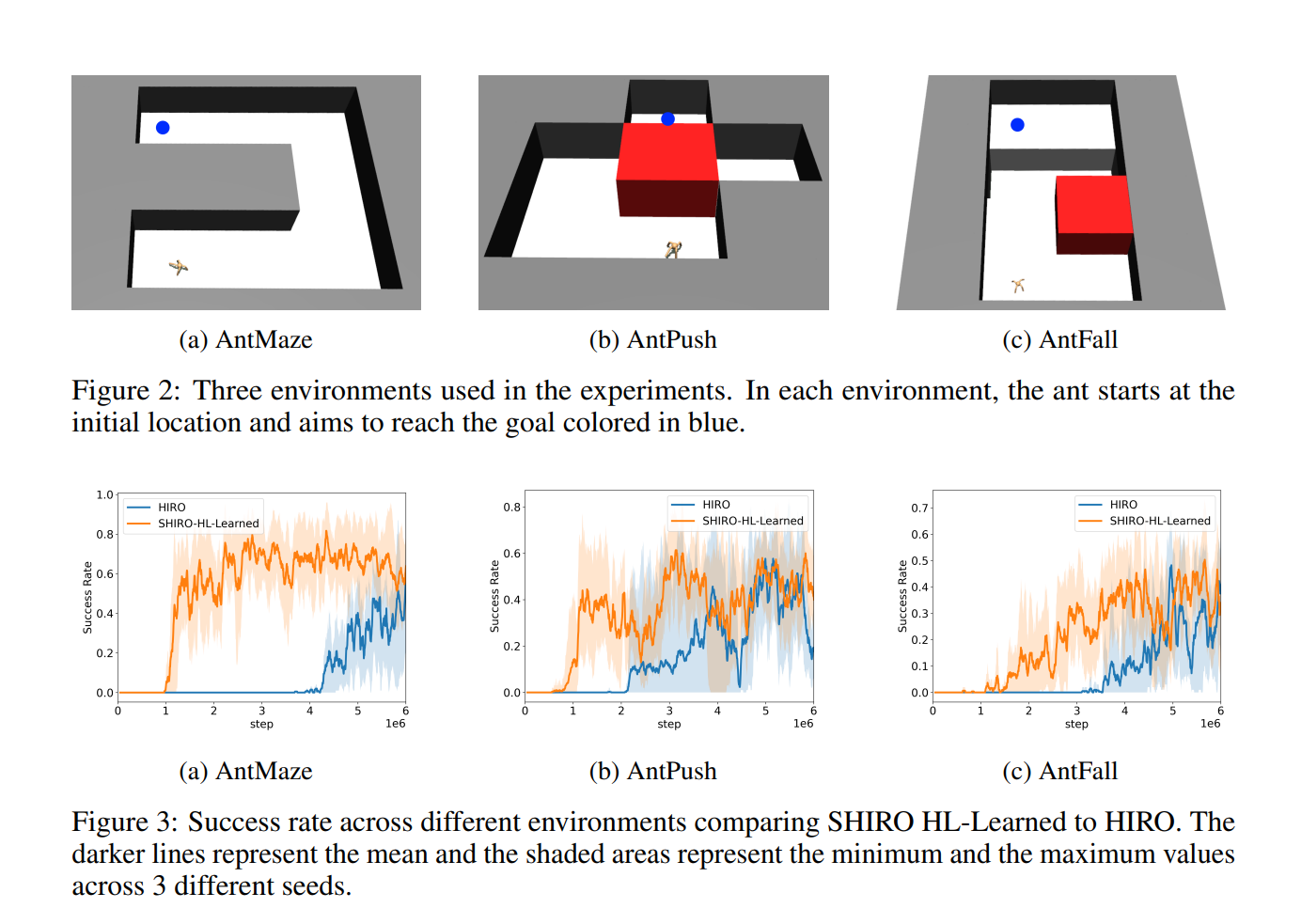
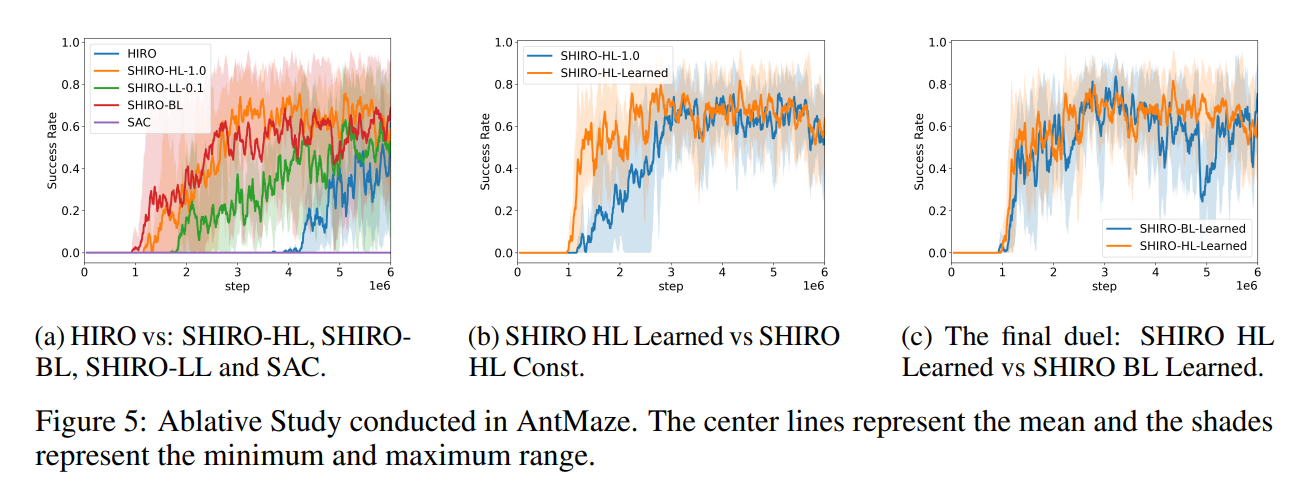
【推荐理由】分层强化学习 (HRL) 算法已被证明在高维决策制定和机器人控制任务上表现良好。 然而,由于它们只针对奖励进行优化,因此智能体倾向于冗余地搜索相同的空间。 这个问题降低了学习速度和获得的奖励。本文提出了一种 Off-Policy HRL 算法,可以最大化熵以进行有效探索。 该算法学习时间抽象的低级策略,并能够通过向高级策略添加熵来进行广泛探索。 这项工作的新颖之处在于在 HRL 设置中向 RL 目标添加熵的理论动机。 根据经验表明,如果低级策略的连续更新之间的 Kullback-Leibler (KL) 差异足够小,则可以将熵添加到两个级别。 作者进行了一项烧蚀研究来分析熵对层次结构的影响,其中向高层添加熵成为最理想的配置。 此外,低层温度较高会导致 Q 值高估,并增加高层运行环境的随机性,使学习更具挑战性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢