
论文标题:
GeneFace: Generalized and High-Fidelity Audio-Driven 3D Talking Face Synthesis
https://arxiv.org/abs/2301.13430
https://github.com/yerfor/GeneFace
导读
语音驱动的说话人视频合成(Audio-driven Talking Face Generation)是虚拟人领域的一个热门话题,它旨在根据一段输入的语音,合成对应的目标人脸说话视频。高质量的说话人视频需要满足两个目标:(1)合成的视频画面应具有较高的保真度;(2)合成的人脸面部表情应与输入的驱动语音保证高度对齐。
近年出现的神经辐射场(NeRF;Neural Radiance Field)[1] 为实现第一个目标,即合成高保真度的说话人视频提供了绝佳的工具。仅需要 3 分钟左右的目标人说话视频作为训练数据,即可合成该目标人说任意语音的视频。然而,目前基于 NeRF 的说话人视频合成算法在实现第二个目标还面临许多挑战,具体来说主要可以分为两个方面:
1. 对域外驱动音频的弱泛化能力:由于训练数据集仅包括数分钟的说话人语音-面部表情的成对数据,模型对不同说话人、不同语种、不同表现形式(如歌声)等域外音频难以生成准确的面部表情。
2. “平均脸”问题:由于相同的语音可能有多种合理的面部动作,使用确定性的回归模型来学习这样一个语音到动作的映射可能导致过于平滑的面部动作和较低的表情表现力 [2]。
在今年的人工智能顶级会议 ICLR 2023 上,浙江大学与字节跳动提出了全新的说话人视频合成模型 GeneFace,该算法旨在解决上述的对域外音频的弱泛化能力和“平均脸”问题,实现了高可泛化、高保真度的语音驱动的说话人视频合成。
背景
目前基于 NeRF 的说话人视频合成方法 [3] 的主要思路是训练一个基于音频输入的条件神经辐射场(Conditional NeRF):
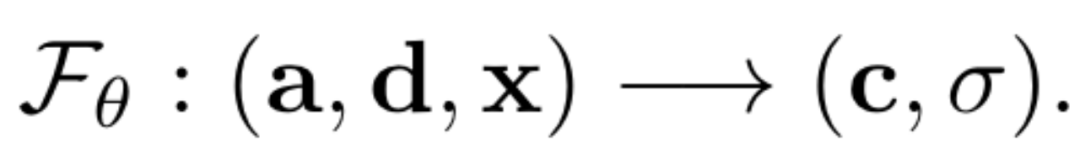
其中输入空间的 a,d,x分别是语音表征、观察方向、3D位置。输出空间的c,\( \sigma \)则分别代表对应位置的颜色和体密度。根据体积渲染(Volume Rendering)公式,可以在辐射场中任意位置、任意视角观察,渲染得到对应的图像:
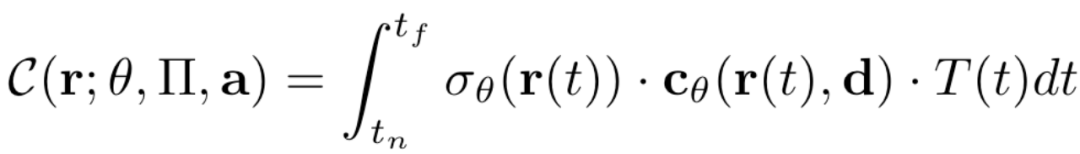
其中T(t)是从观察位置到被观察位置射出的射线的累积不透明度,可以表示为:
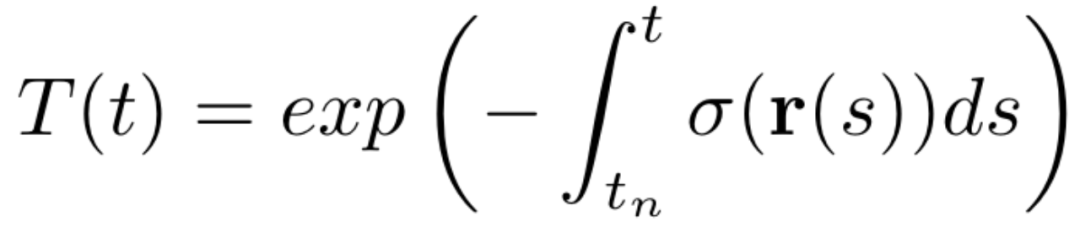
在得到渲染的人脸图像后,对渲染图像与真实图像计算误差,即可对进行模型训练:
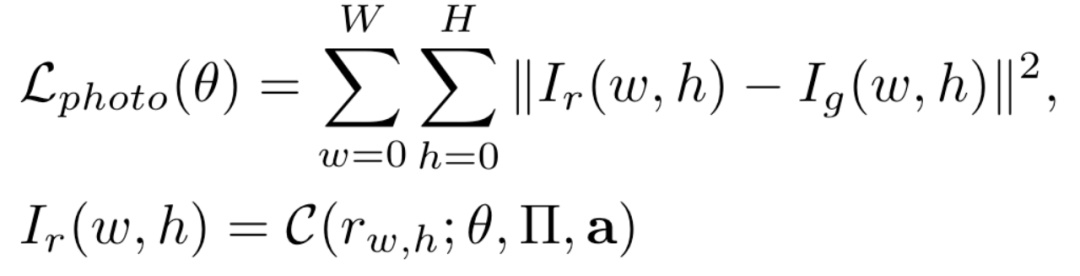
方法
整体方案思路
尽管现有的基于 NeRF 的说话人视频合成方法 [3] 实现了视频的高保真度,但如上所述,由于其使用均方误差损失端到端地训练语音到说话人图像的映射,导致模型对域外驱动音频的弱泛化能力和“平均脸”问题。
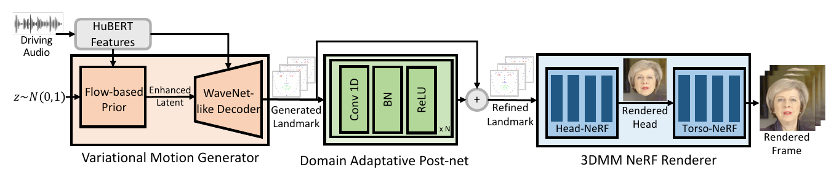
为了解决上述问题,GeneFace 采用 3D 人脸关键点作为中间变量,提出了一个三阶段的框架。
第一阶段是“语音转动作”,我们在大规模唇语识别数据集上学习语音到动作的映射,这使得我们的模型能够享受大数据集带来的高泛化能力。注意为了解决平均脸问题,我们设计了一个变分动作生成器(Variational Motion Generator)来学习这个语音到动作的映射,该模型可以根据输入的语音生成精确的、具有丰富细节和表现力的面部动作。
第二个阶段是“动作域迁移”,我们提出了一种基于对抗训练的域适应方法,以训练一个人脸动作的后处理网络(Domain Adaptative Post-net),从而弥合大规模唇语识别数据集与目标人视频之间的域差距(Domain Gap)。
第三个阶段是“基于动作渲染视频”,我们设计了一个基于 NeRF 的渲染器(3DMM NeRF Renderer),它以预测的 3D 人脸关键点为条件来渲染高保真的说话人视频。GeneFace 的三阶段推理流程如下图所示:
GeneFace 的第一阶段任务是根据输入的音频,得到对应的人脸表情。我们利用 HuBERT 模型从原始音频中提取语音表征,使用 3D 人脸关键点表示人脸表情。我们利用一个大型的唇语识别数据集中的语音-动作数据对,训练了一个准确、鲁棒的语音到动作映射。
为了避免简单的确定性模型导致的“平均脸”问题,我们提出了变分动作生成器(Varaitional Motion Generator)结构。该模型结合了变分自编码器(VAE;Variaitonal Auto-Encoder)和流模型(Flow-based Models)的优点,能根据输入语音生成准确且富有表现力的人脸动作。其训练流程图如下所示:
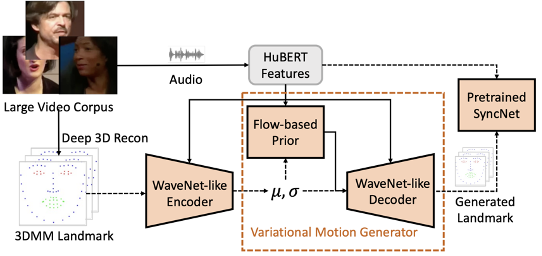
由于目标人视频的数据量(约 3-5 分钟)与大规模唇读数据集(约数百小时)相比差距过大,实验结果表明,目标人的人脸表情与大规模数据集中的人脸表情存在巨大的域差异,可能导致最终渲染的图像出现模糊或不真实的情况。要解决这一问题,一种常见的方法是直接在目标人数据集上微调(fine-tune)整个语音转动作模型。但这个做法可能会导致灾难性遗忘,使模型失去在大数据集上学习到的泛化能力。
在这种情况下,我们设计了一个半监督的对抗训练流程来进行动作域适应。具体来说,我们训练了一个动作后处理网络(post-net)将语音转动作模块所预测的 3D 人脸表情迁移到目标人脸的个性化领域。该后处理网络的训练流程图如下所示:
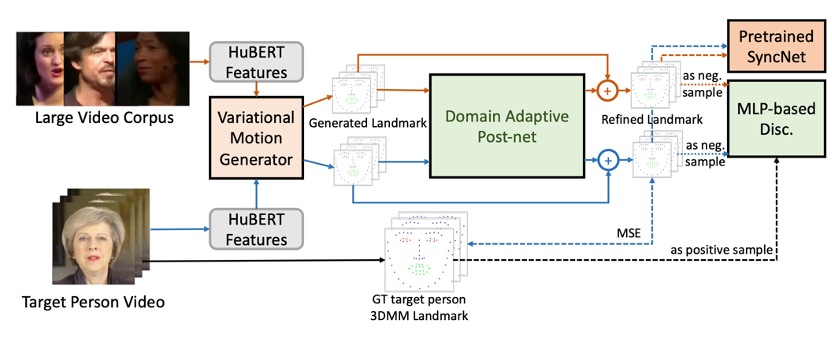
具体来说,动作后处理网络的训练损失函数由三项构成:
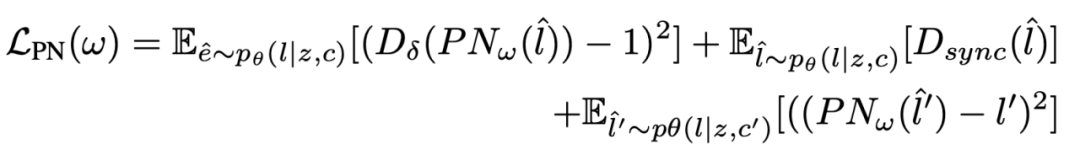
其中前两项是在大规模数据集样本上的 LSGAN [4] 对抗损失,第三项是在目标人数据集样本上经过后处理的预测动作与真实动作的误差损失。
3 基于动作渲染视频
为了给予前两个模块预测的 3D 人脸特征点渲染对应的视频,我们提出了一个以 3D 人脸特征点作为输入条件的 NeRF 模型。具体来说,除了观察方向和 3D 位置之外,3D 人脸特征点也将作为 NeRF 的输入空间,以预测对应位置的颜色和体密度。这一模型可以描述为如下的一个映射:
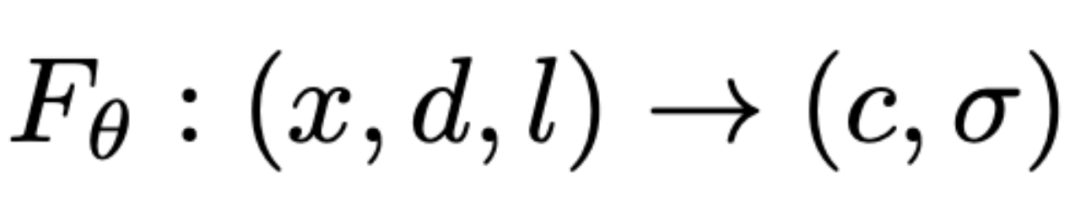
其中l表示 3D 人脸特征点。该模型的训练方式与上文介绍的 NeRF 模型训练方法一致。
实验
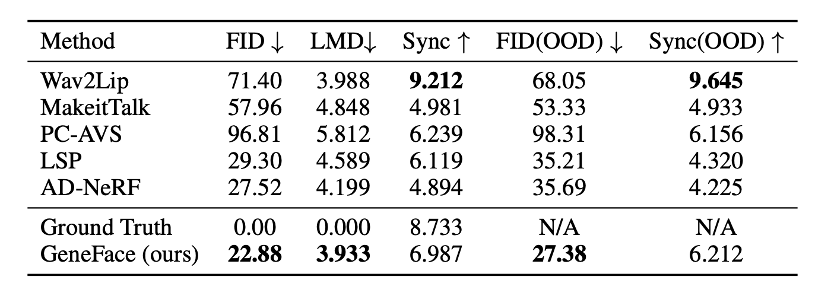
实验表明,GeneFace 相比基准方法实现了更好的图像质量(更低的 FID)、更好的嘴唇对齐程度(更低的 LMD 和更高的 Sync 指标)。尤其是在受域外(OOD;Out-of-Domain)语音驱动时,GeneFace 的优势更加明显。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢