
【标题】On Pre-trained Language Models for Antibody
【作者团队】Danqing Wang, Fei Ye, Hao Zhou
【发表时间】2023/01/28
【机 构】UCSB、字节、AIR
【论文链接】https://arxiv.org/pdf/2301.12112.pdf
【代码链接】https://github.com/dqwang122/EATLM
本文已被ICLR2023接受
抗体是重要的蛋白质,为人体提供强大的保护,防止病原体侵入。一般蛋白质和特定抗体的预训练语言模型的发展都有助于抗体预测任务,然而很少有研究全面地探讨不同的预训练语言模型在不同的抗体问题上的表现能力。在此,为了研究这个问题,本文旨在回答以下关键问题:预训练的语言模型在不同特异性的抗体任务中表现如何,如果本文在预训练过程中引入特定的生物机制,模型将获得多少好处,学会的抗体预训练表征在现实世界的抗体问题中是否有意义,如药物发现和免疫过程理解。以前没有可用的基准,为了方便调查,本文提供了一个抗体理解评估(ATUE)基准。本文通过实证研究全面评估蛋白质预训练语言模型的性能,并得出结论和新的见解。
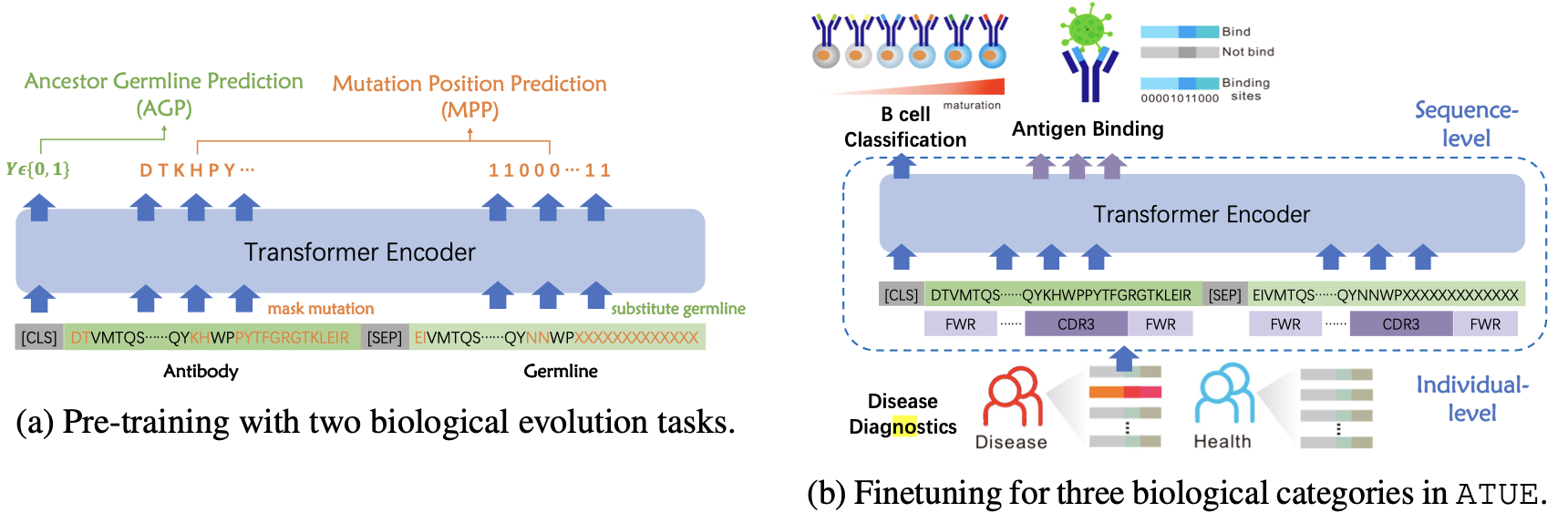
上图展示了本文的预训练和微调的框架。本文引入了2个新的进化相关预训练任务,AGP(ancestor germline prediction)随机替换成对的种系为随机种系并预测祖先关系,MPP(mutation position prediction)预测种系上的突变位置和抗体上的遮蔽突变残基。
在微调方面,本文在语言模型之上添加一个线性层,并在下游任务上对整个模型进行微调。下游任务数据来自ATUE,可以分为序列级和individual级任务,下游任务包括:
- 抗原结合预测是一个二元序列分类任务,以确定抗体的CDR区域是否能与特定的抗原结合。
- 补位预测是确定抗体序列上的结合位置,这是一个序列标签任务,为CDR片段的每个残基预测一个0/1的标签。
- B细胞成熟度分析 这是一个6分类任务,以区分B细胞抗体序列的成熟阶段。每个序列属于不成熟,过渡性,成熟,浆细胞,记忆IgD+,记忆IgD-中的一个。
- 抗体发现任务,该任务是一个二元序列分类任务,以区分哪个抗体直接负责SARS-CoV-2的结合。
- 疾病分类任务, 本文对个体档案中的每个序列进行打分,并计算所有序列的修剪平均值,得到个体得分,并使用所有这些疾病资料来建立用于疾病诊断的Q7多分类任务,
最终得到了以下结论,PPLM指通用抗体预训练模型ESM,PALM指抗体预训练模型比如本文模型或者Antibert
(i) PPLMs在与结构有很大关系的抗体任务中表现良好,例如与抗原的结合。然而,它们在具有高抗体特异性的任务中表现最差,表明有利于蛋白质结构预测的表示法对抗体特异性任务是有害的。
(ii) 在大多数情况下,PALMs的表现与PPLMs一样好,甚至比PPLMs的预训练数据还要好。
(iii) PALMs可以通过加入进化过程而得到改进。然而,来自MSA的进化信息并不总是有利于抗体任务。
(iv) 引入两种抗体生物机制有助于PALMs具有更多的抗体特异性特征,并提高模型在高抗体特异性任务中的表现。这是首次尝试显示抗体特异性进化信息如何被纳入预训练语言模型中。
推荐理由
1. 为了促进抗体的应用研究,本文开发了第一个全面的抗体基准,同时还引入了两个针对抗体进化的目标任务。
2. 为了加速现实世界的抗体发现,本文确定了11个潜在的SARS-CoV-2结合物,其序列与现有的与病毒结合的治疗性抗体高度一致。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢