
最近在课程学习过程中调研了跨域命名实体识别相关的论文,看到了最近挂出的一篇论文觉得很有意思,在这里与大家分享。

论文链接 :https://arxiv.org/abs/2301.10410
本文转载自知乎:https://zhuanlan.zhihu.com/p/603116072
1. Introduction
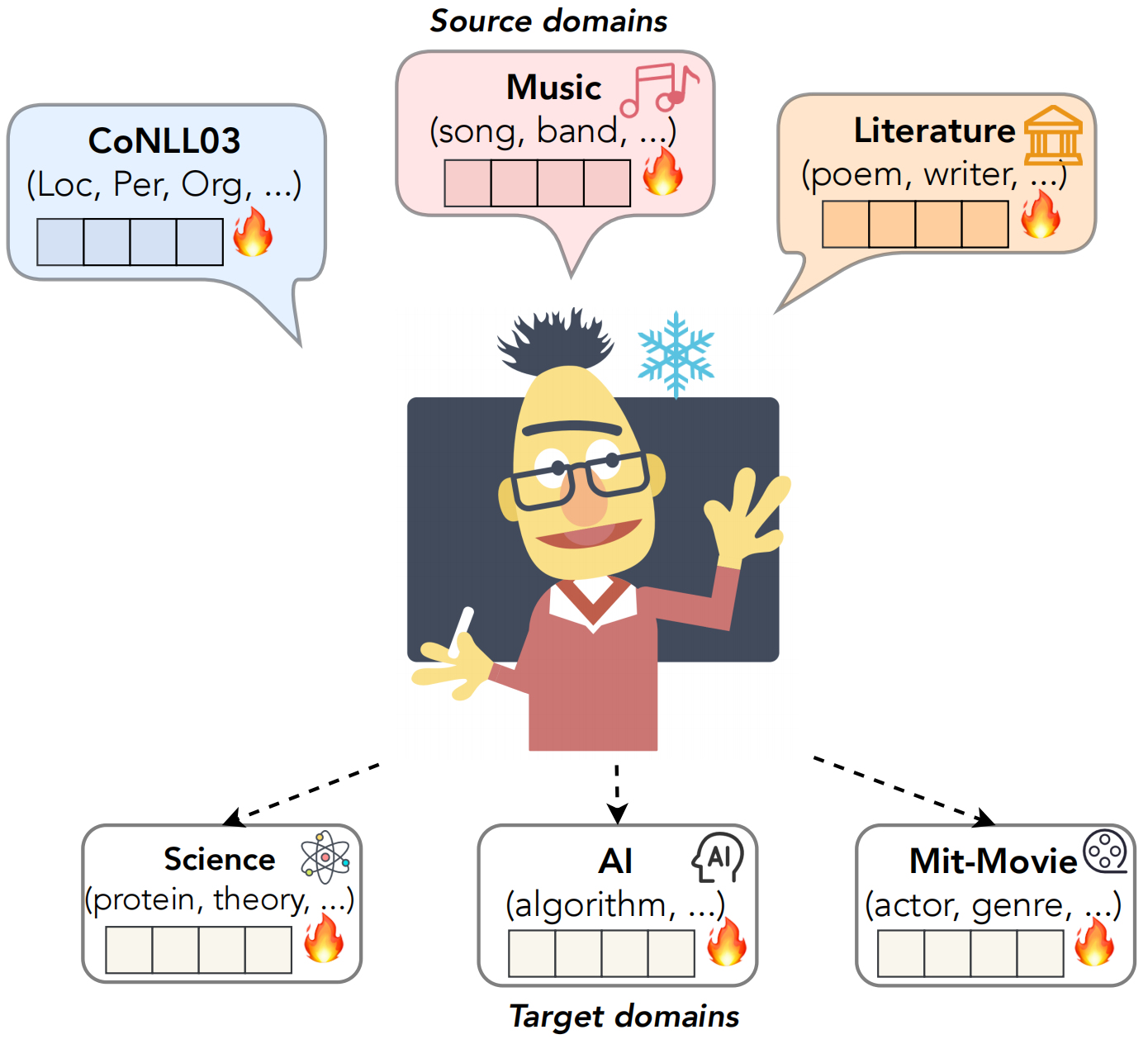
命名实体识别(NER)是知识图谱和自然语言处理领域的重要任务。现实场景中由于数据稀缺的原因,要获取大量的domain相关的标注数据通常消耗巨大。另一方面,想要在资源丰富的domain数据(source)上训练模型,并将知识迁移到新的特定的domain数据(target)上,通常面临语义鸿沟以及target domain数据量受限的问题。要解决上述问题,跨域命名实体识别(Cross-domain NER)任务应运而生。
Cross-domain NER任务出现后,早期的一些工作采用增加辅助模块或者设计新的模型结构的方法来解决,这类方法分别在source和target domain数据上进行训练。NER-BERT在target domain的预料上进一步进行预训练来提升在target domain数据集上的表现。另外一些方法建模source和target domain数据标签之间的关系来帮助标签信息的迁移。目前在CrossNER benchmark上的SOTA模型LANER设计了单独模块来更好地利用domain之间的语义关联,以提升模型cross-domain的表现。然而目前的工作仍然存在很多问题,主要有三方面:(1)之前的方法对于不同的task设计不同的模型,这样限制了模型的实用性;(2)大多数现有的方法对于不同的target domain都训练完整的PLM参数,这大大消耗了计算资源;(3)对于cross-domain NER来说,domian间的知识迁移至关重要,而之前的方法通常只能从一个source domain迁移到target domain,缺乏从多个source迁移到target的能力。
基于上述问题,本篇论文提出了CP-NER模型,主要贡献有三方面:
(1) 本文将NER重新定义为基于domain相关的text-to-text生成instructor (text-to-text generation grounding domain-related instructor),这种新的定义形式可以触发PLMs产生关于NER任务的普遍知识,并可以处理不同的实体类别,而不需要针对不同domain修改PLM的参数,这为one model for all domains奠定了基础。
(2) 本文提出domain-prefix协同调优 (collaborative domain-prefix tuning),目的是将知识适应于cross-domain NER任务。本文应该是第一个提出将多个source domain的知识进行迁移的工作,对于cross domain信息抽取领域具有重要贡献。
(3) 本文的方法在CrossNER benchmark上的单一source domain迁移到target domain设定下取得了SOTA,另外进一步的实验结果表明CP-NER可以高效地利用少量的参数进行知识迁移,并对所有的domian同意了模型框架。
2. Method
2.1 Problem Definition
给定句子 \textbf{x}=\{w_1,w_2,\dots,w_n\} ,NER的目的是从长度为 n 的句子中抽取出所有的实体 \textbf{y} ,我们定义第 i 个实体 y_i \in \textbf{y} 为 y_i=(\textbf{x}_{l:r},t) ,其中 t \in \mathcal{T} 指的是实体类型, r 和 l 指的是实体的边界下标。source和target domain的数据分别表示为 \mathcal{D}_{src} 和 \mathcal{D}_{tgt} 。本文既考虑One Source for Target,又包括Multiple Source for Target设定。
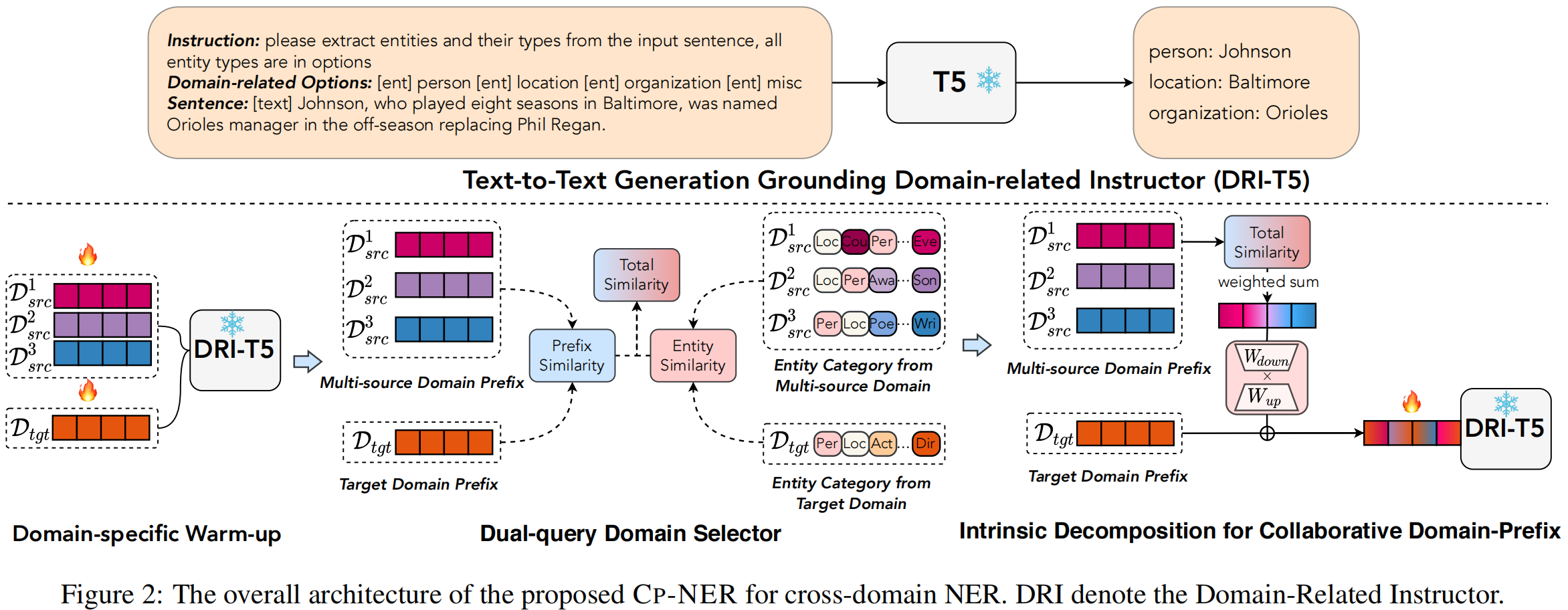
2.2 Text-to-Text Generation Grounding Domain-Related Instructor
本文将cross-domain NER处理为sequence-to-sequence生成式任务,并使用了固定参数的T5模型。模型的输入由如下三部分组成(如图2所示):
- Sentence ( \textbf{x} ):输入的句子;
- Instruction ( \textbf{s} ):告诉模型如何处理NER的指令,要求模型根据指令生成序列;
- Domain-related Options ( \bf{o} ):包含所有实体类型的选项来限制和提示模型。
由此模型的输出可以表示为:
![]()
模型的输出由实体类型、实体mention和特殊符组成,例如“Johnson, who played eight seasons in Baltimore, was named Orioles manager in the off-season replacing PhilRegan.”的输出为“((person: Johnson)(location: Baltimore)(organization: Orioles))”。作者提到使用text-to-text generation grounding domain-related instructor具有两个优点:1)指引T5生成domain-specific实体类型的命名实体序列,使得不需要更改模型的结构就能适应新的domain;2)激发PLM处理不同domain的NER任务的潜力,为引导冻结的PLM通过前缀调优生成实体序列奠定基础。
2.3 Insights of Tuned Prefix as Domain Controller
prefix tuning是将可训练的连续tokens (soft prompts) 添加到Transformer的隐层前。本文将prefix作为cross-domain NER中的domain controller,第 j 层的prefix \delta^{(j)} 通过可训练的矩阵 \mathbf{P}^{(j)} 获取,其他所有的模型参数都是固定不可调整的。第 j 层带有prefix的self-attention表示如下:

2.4 Collaborative Domain-Prefix Tuning
由于文本风格、实体类型等的差异,source prefix中储存的知识在target domain数据上进行fine-tune后容易被稀释或遗忘,这使得通过prefix tuning直接进行知识迁移变得困难。为了帮助T5的domain controller更有效地从source domain获取知识并迁移到target domain上,文章提出了domain-prefix的协同优化方法。具体步骤如图2:
1) domain-specific warm-up从各个domain的语料中捕获知识;
2) dual-query domain selector从多个source domain确定不同prefix知识的比重;
3) intrinsic decomposition for collaborative domain-prefix灵活地融合source和target domain的prefix中的知识。
2.4.1 Domain-specific Warm-up
为了灵活地使用不同domain中包含知识的prefix,本文首先用domain语料对prefix进行训练。形式上,对被固定的T5模型的所有 L 层设置新的初始化训练参数矩阵 \{\textbf{P}^{(0)},\dots,\textbf{P}^{(L-1)}\} ,最终第 l 层的prefix来自参数矩阵 \textbf{P}^{(l)} ,训练过程中使用训练集 \mathcal{D}_{tr} 对每一层的参数矩阵进行优化以得到最终的prefix,优化目标如下:
![]()
其中 \sigma 表示softmax函数,用于将输出 h^{(L)}_O 映射到vocabulary上的向量分布。 h^{(j)}_i 是第 i 个token第 j 层的中间向量。最终通过warm-up得到的domain controller为 \{\delta^{(0)},\dots,\delta^{(L-1)}\} 。
2.4.2 Dual-query Domain Selector
当source和target domain部分实体类型相同时,从直觉上看利用那些具有相似语义信息的共享标签来灵活地适应target domain是有利的。此外domain-specific prefixes可以提供domian特定的语法风格和知识。基于上述考虑,本文从label相似度和prefix相似度两方面设计dual-query domain selector来决定不同source domain对于target domain的重要程度。
entity相似度:文章通过T5模型下实体标签词的embedding来计算实体相似度,对于第 i 个source domain的标签语义编码 E^i_{src} \in \mathbb{R}^{|\mathcal{T}_{src}|\times d} 和target domain标签语义编码 E^i_{tgt} \in \mathbb{R}^{|\mathcal{T}_{tgt}|\times d} ,标签相似度 \mathcal{S}^i_e 表示为:
![]()
prefix相似度:给定source domain的prefix \delta_{src}=\{\delta^{(0)}_{src},\dots,\delta^{(L-1)}_{src}\} 和target domain的prefix \delta_{tgt}=\{\delta^{(0)}_{tgt},\dots,\delta^{(L-1)}_{tgt}\} ,计算二者的余弦相似度:
![]()
第 i 个source domain与target domain的总相似度根据entity相似度和prefix相似度计算:
![]()
其中超参数 \alpha 在 [0,1] 之间。总相似度分布根据各个 \mathcal{S}^i_{total} 进行softmax计算得到:
![]()
2.4.3 Intrinsic Decomposition for Collaborative Domain-Prefix
该部分负责将多个source domain的prefix进行融合。为了更好地联系不同domain的知识,文章在prefix的参数矩阵中加入了可训练的低秩矩阵 W_{down} \in \mathbb{R}^{d \times r} 和 W_{up} \in \mathbb{R}^{r \times d},最终融合source prefix与target prefix的公式表达如下:
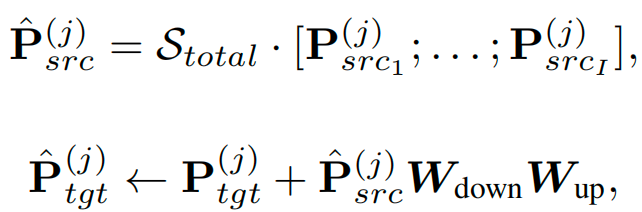
3. 实验
实验在CrossNER 数据集上进行,baseline包括DAPT、COACH、CROSS-DOMAIN LM、FLAIR、BARTNER、LST-NER、LANER、LIGHTNER,为了对比的公平性,所有的baseline都使用base级别的PLM。
3.1 Transfer from Single Source Domain
如表1所示,CP-NER在不同target上全面超过了SOTA模型LANER,F1-score平均提升3.56%,特别是在science和music两个数据集上分别提升了6%和8%。实验结果证明CP-NER技术可以在CrossNER benchmark上取得优秀的表现。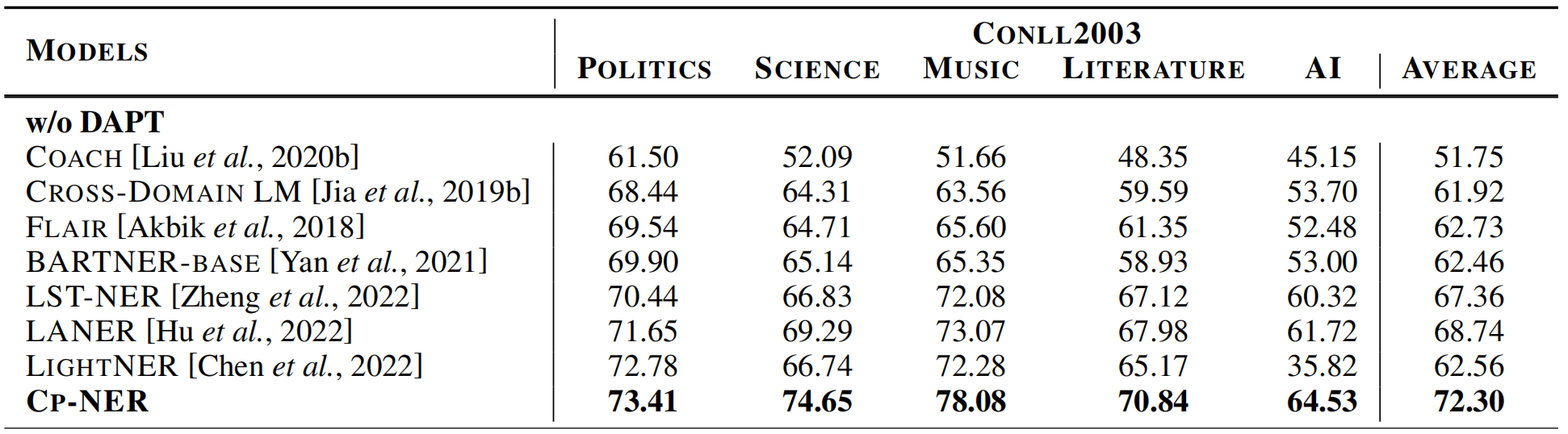
3.2 Transfer from Multiple Source Domains
先前的工作只聚焦于从单一source迁移到target,忽略了现实场景下多个source存在的情况。如表2所示,文章使用多个source domain进行了实验,为了对比实验效果,针对baseline设定了两种训练方式:
1)<Ensemble Transfer>针对每个source domain分别训练并迁移到target domain上,最后集成所有的训练结果得到最终表现;
2)<Chain Transfer>轮流在各个source domain上接力训练,并迁移到target domain上得到结果;
3)<Multiple Source>使用warm-up domain-specific prefix进行domain-prefix协同调优。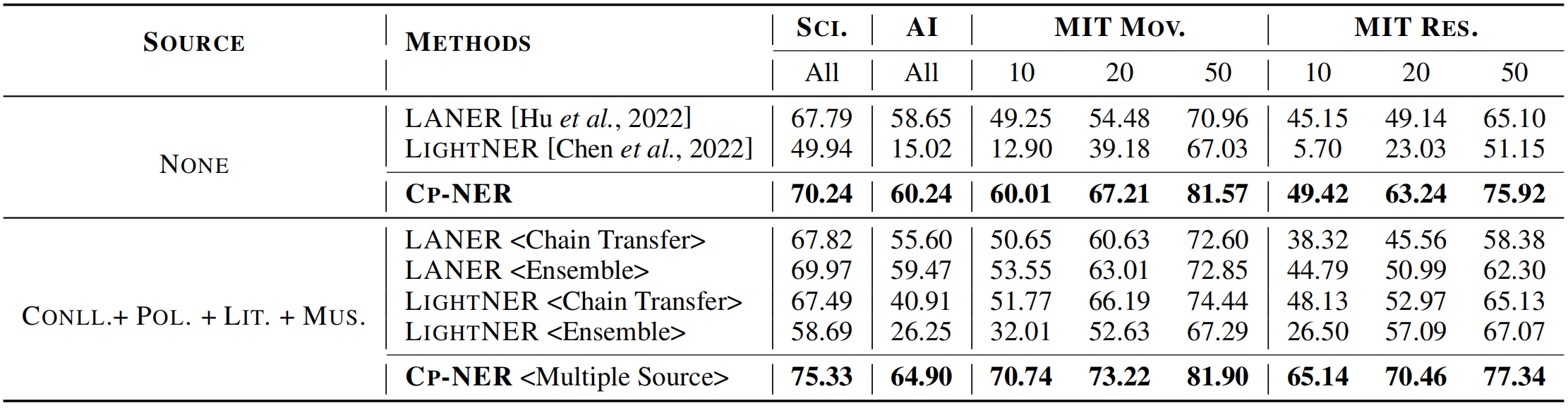
综合表1和表2可以验证,文章提出的多个source迁移的方法相对单一source的表现更加突出。进一步可以观察到baseline中只有LIGHTNER<Ensemble>和LANER<Chain>相对于单一source有所提升,表明<Ensemble>设定可能更适用于少参数调优,而<Chain>设定更适用于全参数调优。
文章进一步进行了少样本测试,可以发现几乎所有的方法随着训练数据规模的增大性能都有所提升,表明有标签数据量的关键。可以发现本文的方法在少样本上也表现突出。
3.3 Analysis
3.3.1 Similarity-based Selector![]()
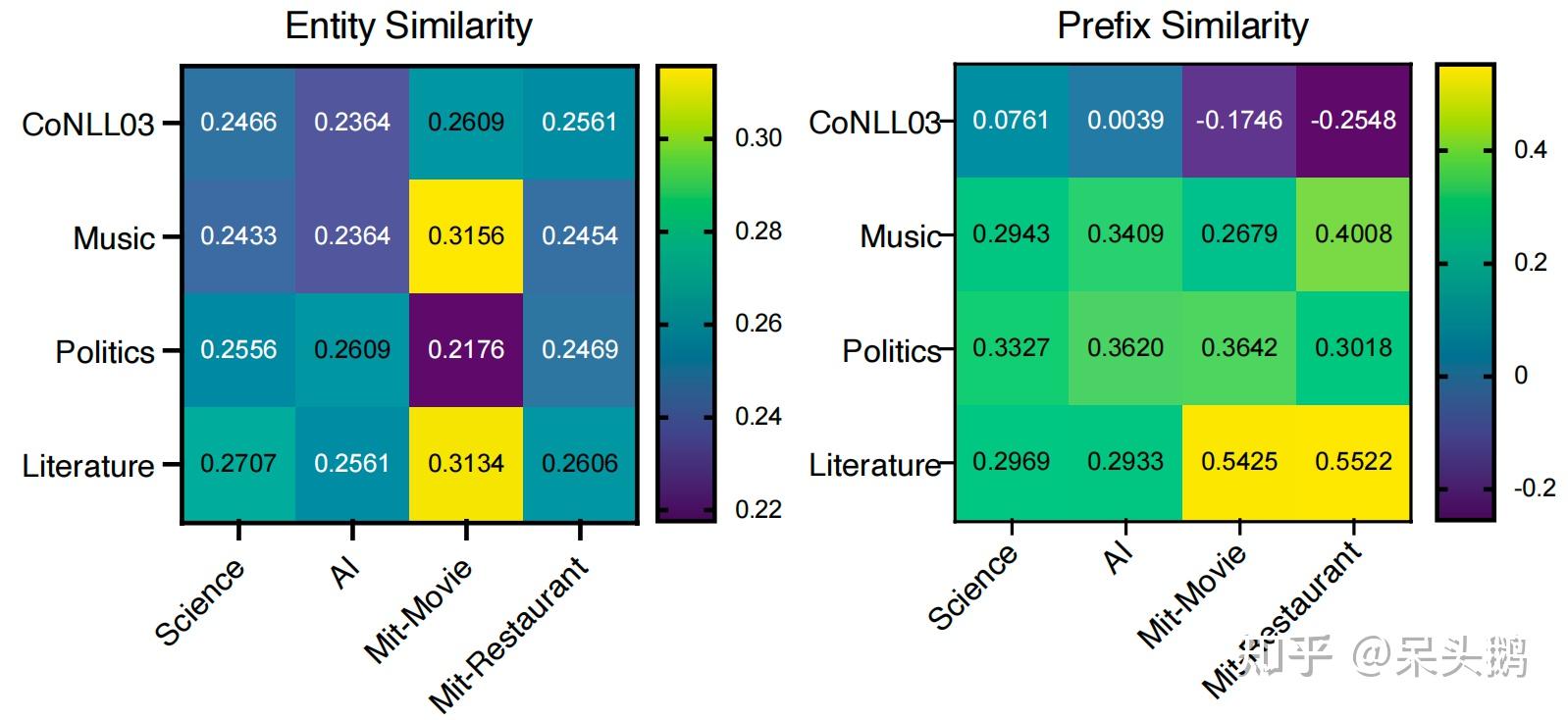
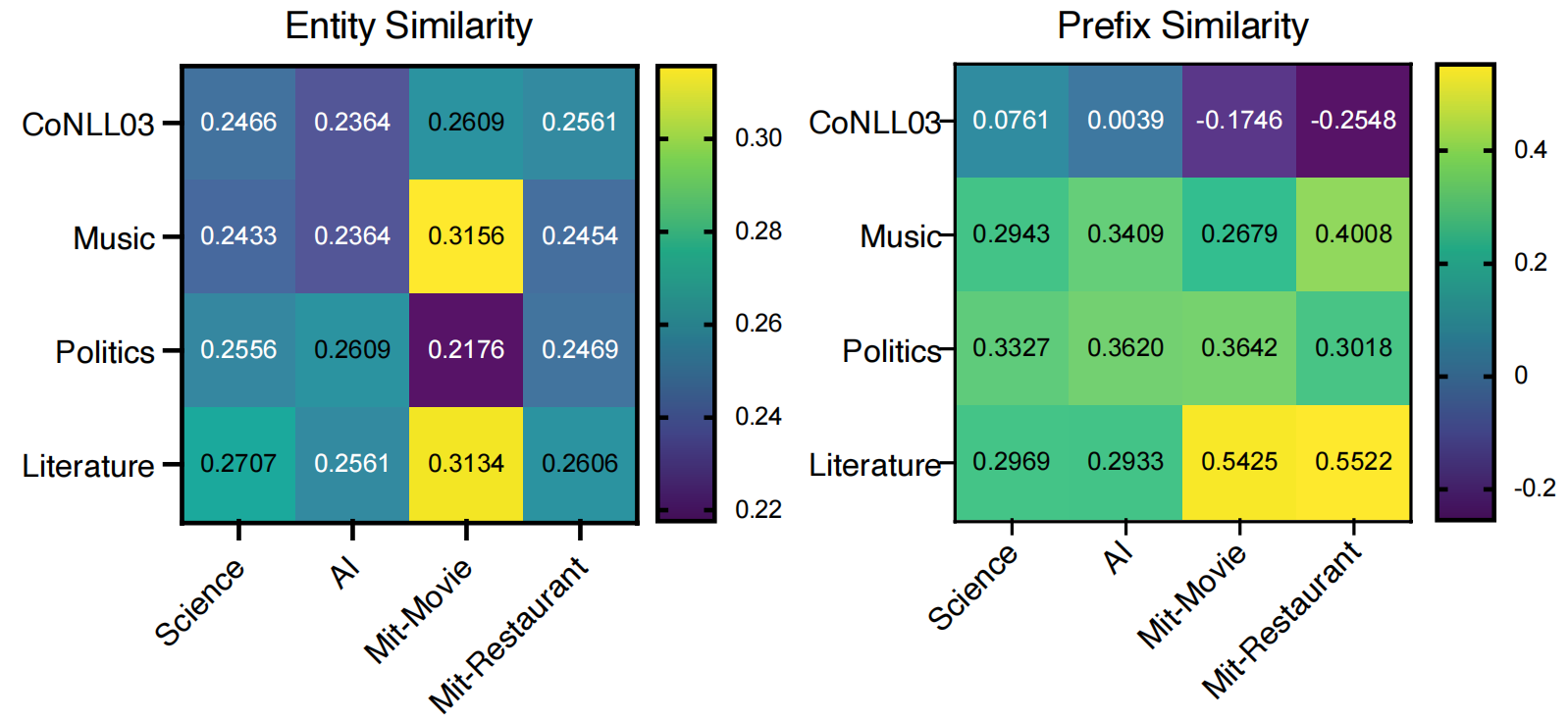
图3将source和target domain之间的entity和prefix相似度进行了可视化。可以发现entity相似度与实体类别高度相关,例如music与movie最相关,因为它们具有相同的实体类别“song”以及类似的实体类别“genre”和“musicgenre”。此外entity相似度和prefix相似度的趋势基本一致,相似度较高的source domain大致相同。这些现象表明基于相似度的选择器可以有效地为target domain选择最有价值的source domain。
3.3.2 Case Analysis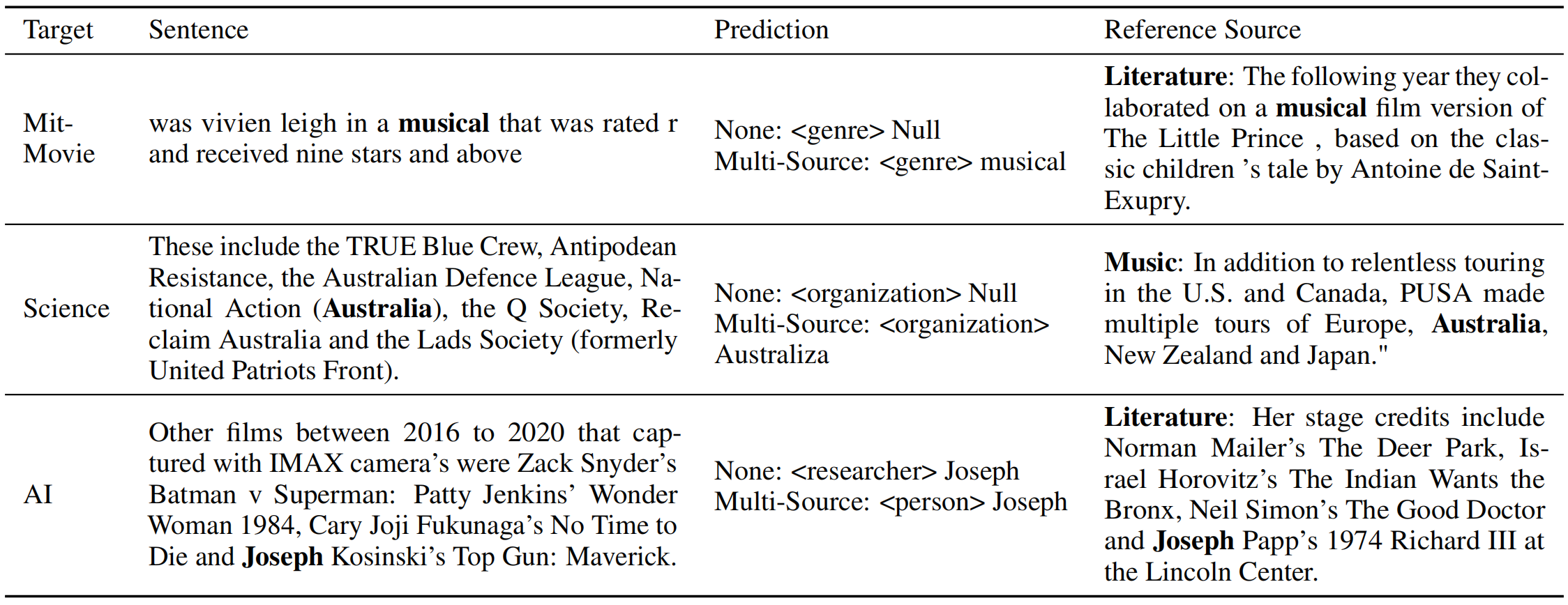
表3显示在多个source上迁移的模型表现得更加鲁棒,例如一些实体已经出现在source domains中,在target domain中很容易被预测到。
3.3.3 Ablation Study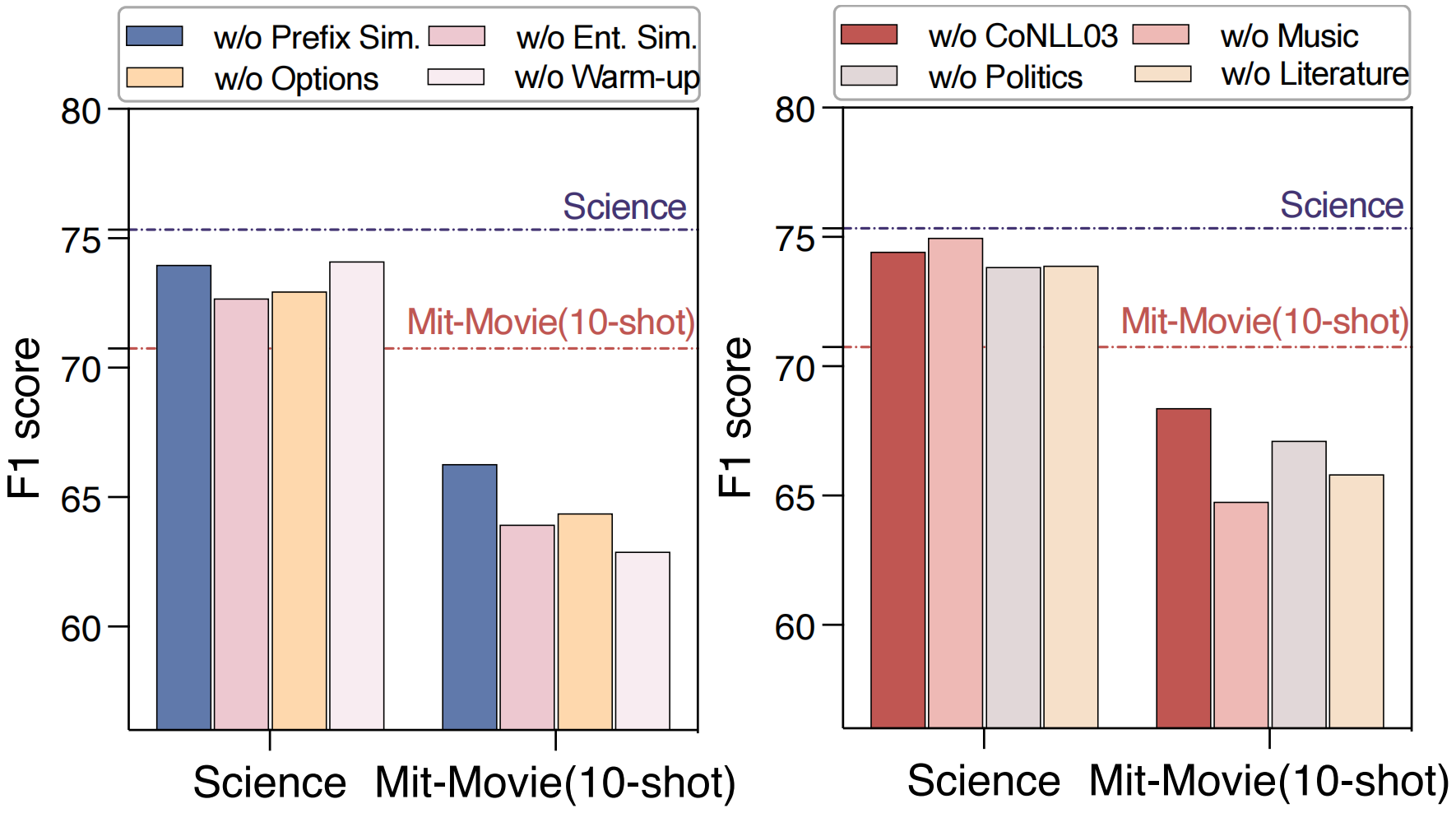
图4左侧显示了去掉相应模块后模型在science和mit-movie数据集上的表现,可以发现模型表现在不同程度上均有所下降,尤其在没有entity相似度时,这表明标签对于cross domain NER的重要性。另外图4右侧探究了不同source domain对target domain的影响,发现每个source domain在迁移过程中发挥着独特的作用,并对不同的target domain表现出不同程度的重要性,验证了利用来自多个domain的知识来提高target domain性能的有效性。
4. Conclusion
本篇论文使用CP-NER模型来处理cross-domain NER任务,该模型使用domain-prefix协同调优来更好地利用多个domain的知识。通过实验表明,CP-NER模型在CrossNER benchmark上的表现全面超过了一系列baseline和SOTA模型。本文提出的CP-NER方法可以实现one mode for all domains,在现实中可以发挥很大的实际作用。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢