
作者:Haiyang Xu, Qinghao Ye, Ming Yan,等
推荐理由:本文是用于多模态预训练的模块化设计的新统一范例。
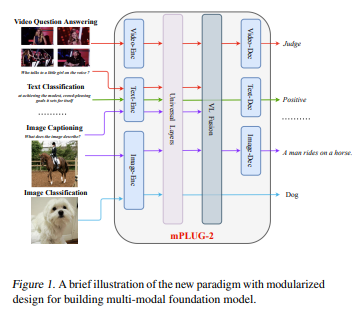
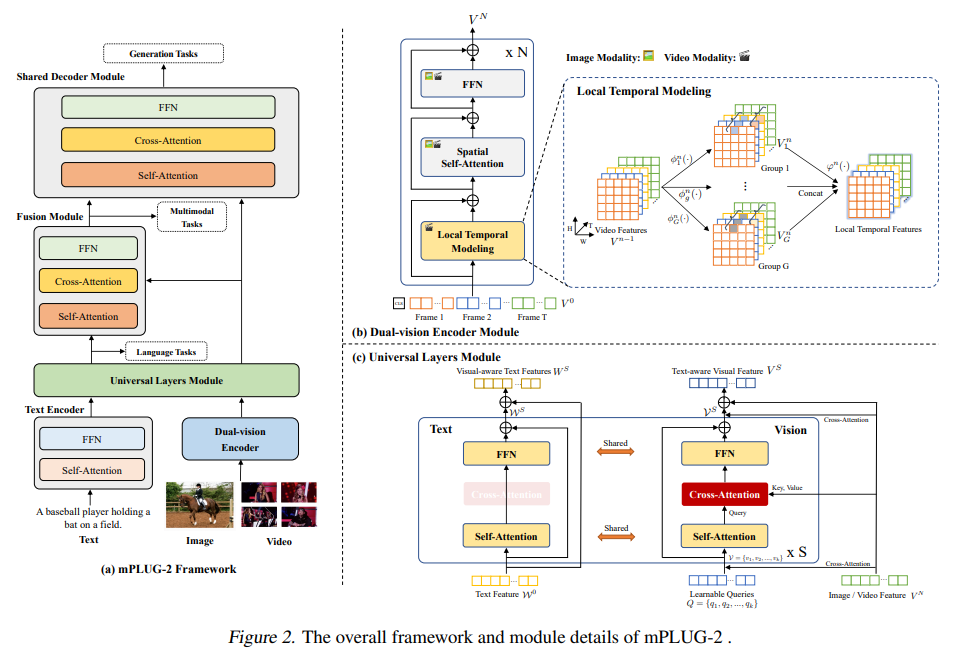
简介:近年来见证了语言、视觉和多模态预训练的大融合。在这项工作中,作者提出了 mPLUG-2---重在解决模态纠缠问题的同时受益于模态协作。与仅依赖序列到序列生成或基于编码器的实例识别的主要范例相比,mPLUG-2 通过共享通用模块进行模态协作、并解开不同模态模块以处理模态纠缠,从而引入了多模块组合网络,可以灵活地选择不同的模块来处理包括文本、图像和视频在内的所有模态的不同理解和生成任务。实证研究表明:mPLUG-2 在 30 多个下游任务中取得了SOTA结果,涵盖图像文本和视频文本理解和生成的多模态任务,以及单模态任务纯文本、纯图像和纯视频的理解。值得注意的是,mPLUG-2 在模型尺寸和数据规模小得多的具有挑战性的 MSRVTT 视频 QA 和视频字幕任务中显示了 48.0 top-1 准确度和 80.3 CIDEr 的最新最新结果。它还在视觉语言和视频语言任务上展示了强大的零样本可迁移性。
论文下载:https://arxiv.org/pdf/2302.00402.pdf
源码下载:https://github.com/alibaba/AliceMind
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢