
作者:Hao Liu, Wilson Yan, Pieter Abbeel
推荐理由:本文是业界第一个通过利用预训练语言模型的力量将未对齐图像用于多模态任务的工作。
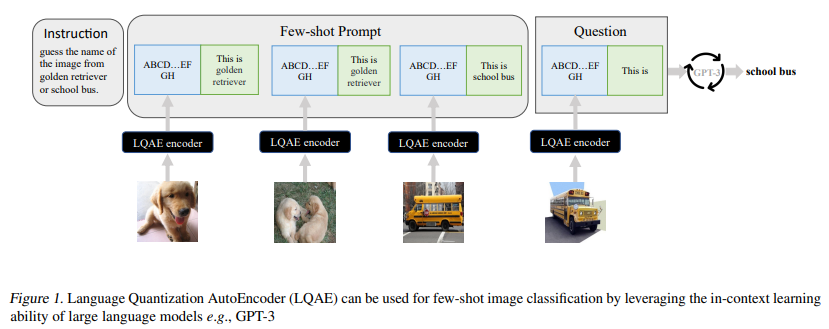
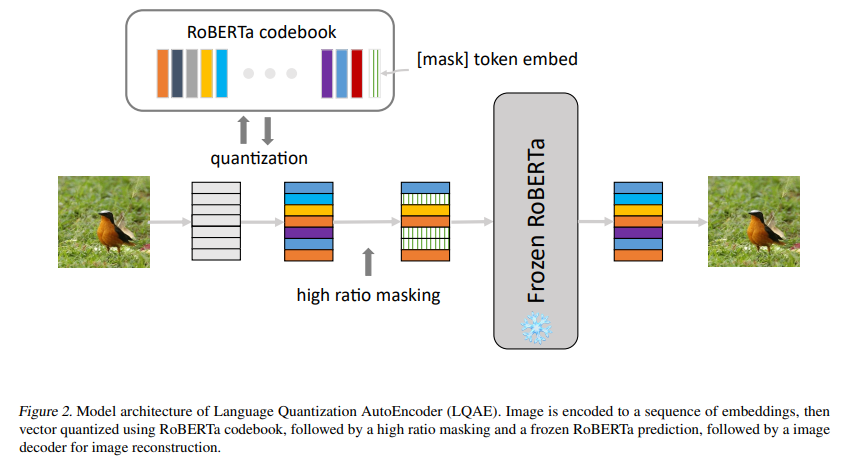
简介:最近在扩大大型语言模型方面取得的进展表明,在广泛的基于文本的任务中执行小样本学习的能力令人印象深刻。然而,一个关键的限制是这些语言模型从根本上缺乏视觉感知——这是扩展这些模型以便能够与现实世界交互并解决视觉任务所需的关键属性(例如视觉问答和机器人技术)。之前的工作主要是通过对精选的图像-文本数据集进行预训练和/或微调,将图像与文本联系起来,这可能是一个代价高昂的过程。为了解决这个限制,作者提出了一种简单而有效的方法,称为语言量化自动编码器(LQAE),它是 VQ-VAE 的一种修改、通过利用预训练的语言模型(如BERT)以无监督的方式学习对齐文本图像数据。作者的主要想法是通过使用预训练语言码本直接量化图像嵌入,将图像编码为文本标记序列。然后作者应用随机掩码,然后是 BERT 模型,并让解码器从 BERT 预测的文本标记嵌入中重建原始图像。通过这样做,LQAE 学会了用相似的文本标记集群来表示相似的图像,从而在不使用对齐的文本图像对的情况下对齐这两种模式。这使得能够使用大型语言模型(例如 GPT-3)进行小样本图像分类,以及基于 BERT 文本特征的图像线性分类。作者希望本文的工作将启发未来在多模式任务中使用未对齐数据的研究。
论文下载:https://arxiv.org/pdf/2302.00902.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢