
一个最新发布的“图生文”模型在网上爆火,其优秀的效果引发众多网友纷纷转发、点赞。
不仅是基础的“看图说话”功能,写情诗、讲解剧情、给图片中对象设计对话等等,这个AI都拿捏得稳稳的!比如,当你在网上刷到诱人的美食时,只需把图片发给它,它就会立马识别出需要的食材和做菜步骤:

甚至图片中的一些列文虎克的细节也能“看”得清清楚楚。
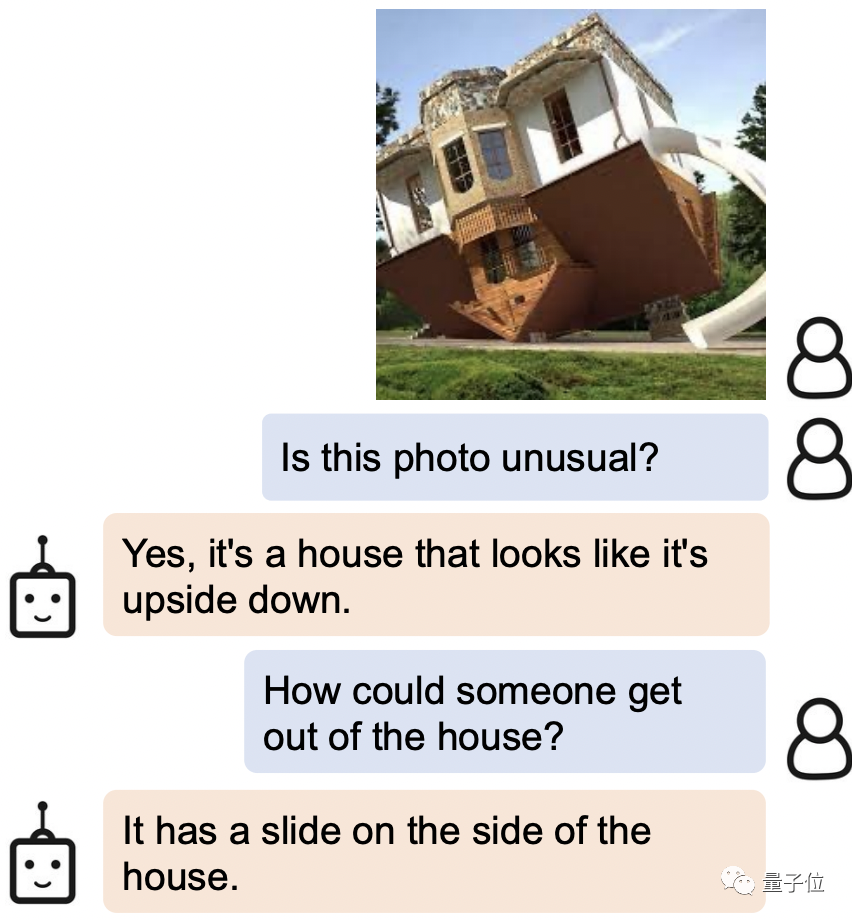
当被问到如何才能从图片中倒着的房子里离开,AI的回答是:侧面不是有滑梯嘛!
这只新AI名为BLIP-2 (Bootstrapping Language-Image Pre-training 2),目前代码已开源。
最重要的是,和以前的研究不同,BLIP-2使用的是一种通用的预训练框架,因此可以任意对接自己的语言模型。
BLIP-2的研究团队来自Salesforce Research,作者之一Steven Hoi:BLIP-2未来就是“多模态版ChatGPT”

第一作者为Junnan Li,他也是一年前推出的BLIP的一作。
目前是Salesforce亚洲研究院高级研究科学家。本科毕业于香港大学,博士毕业于新加坡国立大学。研究领域很广泛,包括自我监督学习、半监督学习、弱监督学习、视觉-语言。
以下是BLIP-2的论文链接和GitHub链接,感兴趣的小伙伴们可以自取~
论文链接:
https://arxiv.org/pdf/2301.12597.pdf
GitHub链接:
https://github.com/salesforce/LAVIS/tree/main/projects/blip2
参考链接:
[1]https://twitter.com/mrdbourke/status/1620353263651688448
[2]https://twitter.com/LiJunnan0409/status/1620259379223343107
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢